file1 包含一些全角的 :,我想将它们转换成普通的半角的 :。在 bash 中该怎么做?也许需要使用 Python 脚本?
5个回答
4
恕我直言,Python不是这项工作的正确工具;Perl才是:
perl -CSAD -i.orig -pe 'tr[:][:]' file1
或者
perl -CSAD -i.orig -pe 'tr[\x{FF1A}][:]' file1
或者
perl -CSAD -i.orig -Mcharnames=:full -pe 'tr[\N{FULLWIDTH COLON}][:]' file1
或者
perl -CSAD -i.orig -Mcharnames=:full -pe 'tr[\N{FULLWIDTH EXCLAMATION MARK}\N{FULLWIDTH QUOTATION MARK}\{FULLWIDTH NUMBER SIGN}\N{FULLWIDTH DOLLAR SIGN}\N{FULLWIDTH PERCENT SIGN}\N{FULLWIDTH AMPERSAND}\{FULLWIDTH APOSTROPHE}\N{FULLWIDTH LEFT PARENTHESIS}\N{FULLWIDTH RIGHT PARENTHESIS}\N{FULLWIDTH ASTERISK}\N{FULLWIDTH PLUS SIGN}\N{FULLWIDTH COMMA}\N{FULLWIDTH HYPHEN-MINUS}\N{FULLWIDTH FULL STOP}\N{FULLWIDTH SOLIDUS}][\N{EXCLAMATION MARK}\N{QUOTATION MARK}\N{NUMBER SIGN}\N{DOLLAR SIGN}\N{PERCENT SIGN}\{AMPERSAND}\N{APOSTROPHE}\N{LEFT PARENTHESIS}\N{RIGHT PARENTHESIS}\N{ASTERISK}\N{PLUS SIGN}\N{COMMA}\{HYPHEN-MINUS}\N{FULL STOP}\N{SOLIDUS}]' file1
- tchrist
1
我同意,Perl的解决方案更加简洁。虽然对于OP来说,规范化文本也可能是一个有趣的选择。 - Acorn
3
我同意Python并不是处理这种情况最有效的工具。虽然目前为止提出的选项都不错,但sed是另一个好工具:
sed -i 's/\xEF\xBC\x9A/:/g' file.txt
-i选项会导致sed直接在文件中进行编辑,类似于tchrist的perl示例。请注意,
\xEF\xBC\x9A是UTF-16值\xFF1A的UTF-8等效值。如果您需要处理相同Unicode值的不同编码,请参考该页面,这是一个有用的参考资料。- ajk
1
1处理编码级别的事情总是错误的方法。您永远不应该必须从这种或那种编码中拼写出特定的位模式。您应该始终只处理逻辑字符。其他任何东西都是疯狂的。 - tchrist
1
你可能想要研究一下Python的
它可以让你将一个Unicode字符串规范化为特定的形式,例如:
如果您只想替换特定字符,可以使用
unicodedata.normalize()函数。它可以让你将一个Unicode字符串规范化为特定的形式,例如:
unicodedata.normalize('NFKC', thestring)
下面是Unicode标准附录#15中不同规范化形式的表格:Unicode Standard Annex #15。
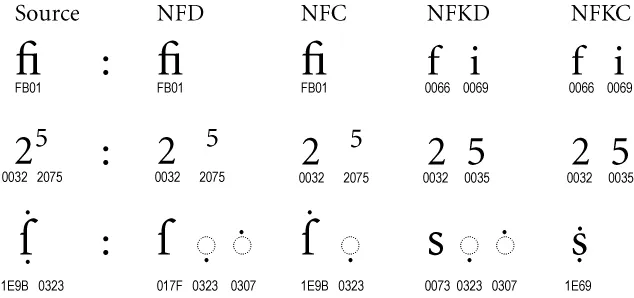
如果您只想替换特定字符,可以使用
unicode.translate()方法。
>>> orig = u'\uFF1A:'
>>> table = {0xFF1A: u':'}
>>> print repr(orig)
u'\uFF1A:'
>>> print repr(orig.translate(table))
u'::'
- Acorn
10
python -c .... 的等价物是我刚才给出的 Perl 一行命令吗? - tchrist-1 你显然没有测试过这个。 (1)
u'\x{FF1A}' 是无效的语法 -- 应该使用 u'\uFF1A' (2) string.maketrans 是用于 str 对象,而不是 unicode 对象 -- 你需要 table = {0xFF1A: u':'} (3) 你还没有将输入的 str 对象从 utf8/big5/gbk/shift_jis/whatever 解码为 unicode。 - John Machin哎呀,是的,我只测试了非Unicode..谢谢你指出来并解释所有的更正!看起来我有点过于急躁了.. - Acorn
如果你弄乱了翻译表,
repr(result) 将包含原始的 u'\uff1a' -- print result 会显示全角冒号,这在视觉上和 ASCII 冒号非常相似。 - John Machin@John:哦,没错,是
:和\uff1a的区别。你之前的评论让我以为输出会变成\x3a。 - Acorn显示剩余5条评论
0
在Python 2.x中,您可以使用
以下代码设置了一个翻译表,将所有ASCII图形字符的全角等效字符映射到它们的ASCII等效字符:
(参考:请见维基百科)
unicode.translate方法将单个Unicode代码点转换为0、1或多个代码点。replacement_string = original_string.translate(table)
以下代码设置了一个翻译表,将所有ASCII图形字符的全角等效字符映射到它们的ASCII等效字符:
# ! is 0x21 (ASCII) 0xFF01 (full); ~ is 0x7E (ASCII) 0xFF5E (full)
table = dict((x + 0xFF00 - 0x20, unichr(x)) for x in xrange(0x21, 0x7F))
(参考:请见维基百科)
如果你想要类似地处理空格,请使用table[0x3000] = u' '
- John Machin
0
你可以尝试使用
tr:cat file.ext | tr ":" ":" > file_new.ext
- Blender
1
@Mike:这是因为tr不支持Unicode。但Perl可以。 - tchrist
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
cat file1 | iconv -t latin1//TRANSLIT没有帮到你吗?这个问题是在这个问题之前提出的... - sehe