我需要一个算法,将无向图的顶点划分为一个或多个子图,以使每个子图都是完全图 (每个顶点都与其他每个顶点相邻)。每个顶点必须恰好属于其中一个子图。
以下是一个示例:
以下是一个示例:
input = [
(A, B),
(B, C),
(A, C),
(B, D),
(D, E),
]
output = myalgo(input) # [(A, B, C), (D, E)]
下面是更好描述问题的图片:
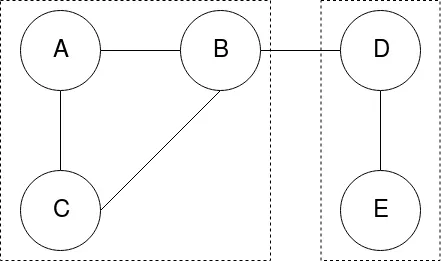
输入列表按距离降序排序,这就是为什么我连接A-B-C而不是B-D的原因。
我认为这可能称为“强连通分量”,并已经尝试了以下解决方案:
在无向图中查找强连通分量: 它寻找的是不同的东西
在无向图中查找所有循环: 它给我许多循环,并且并不是最好的,它不关心输入顺序。
一个从数据对中创建集群的算法 in Python: 它连接了所有分量,只因为它们之间有一条路径(A-B-C-D-E)。
Kosaraju算法: 它只适用于有向图。