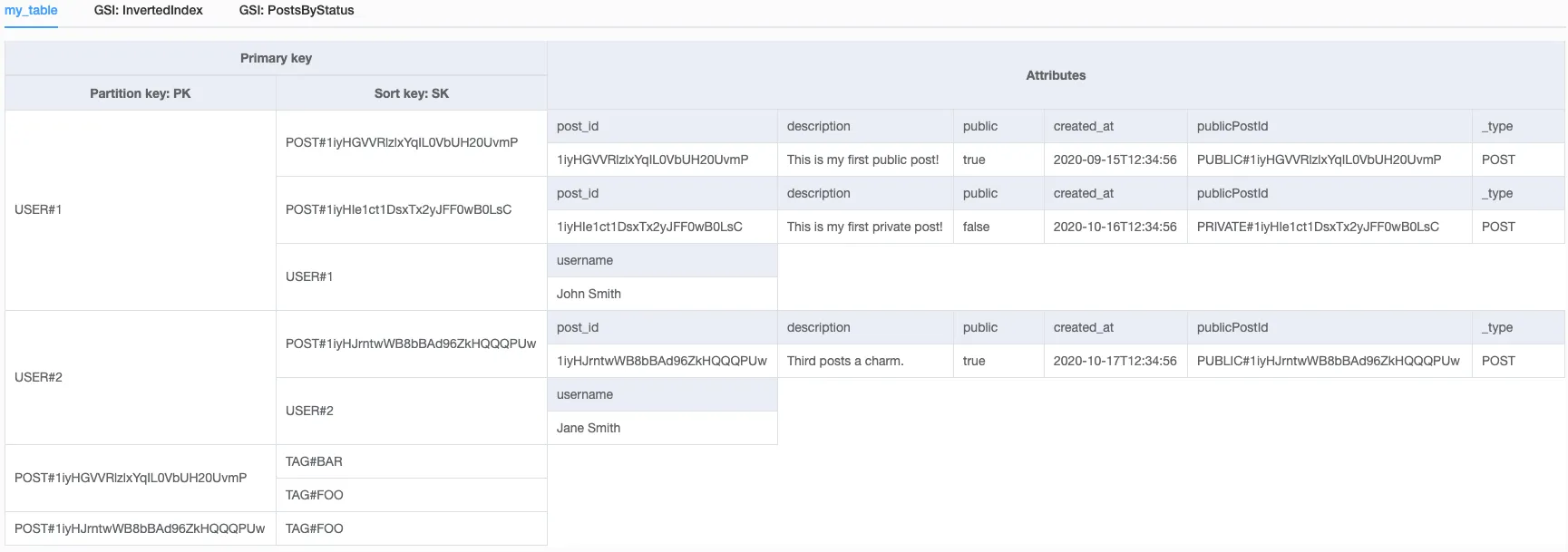
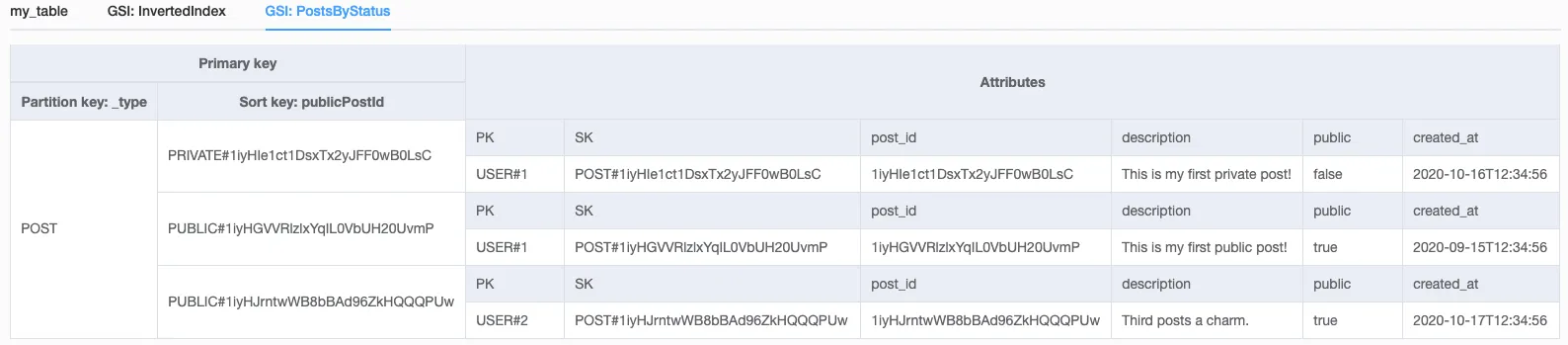
我是一名新手,对NoSql的世界并不熟悉。我正在使用dynamodb构建一个无服务器应用程序。在关系型数据库中,当我有3个实体,如post、post_likes和post_tags时,我会有几个表,并使用连接来获取数据。但是,我想知道,在post与likes存在一对多关系,而与tags存在多对多关系的情况下,应该如何制定NoSql结构。
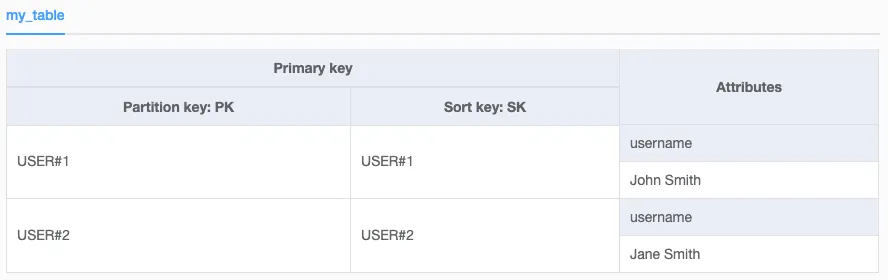
Post模型:
那么这个表格看起来会像这样:
分区键设置为public,排序键设置为post_id
第二个全局次要索引:
分区键设置为user_id,排序键设置为post_id
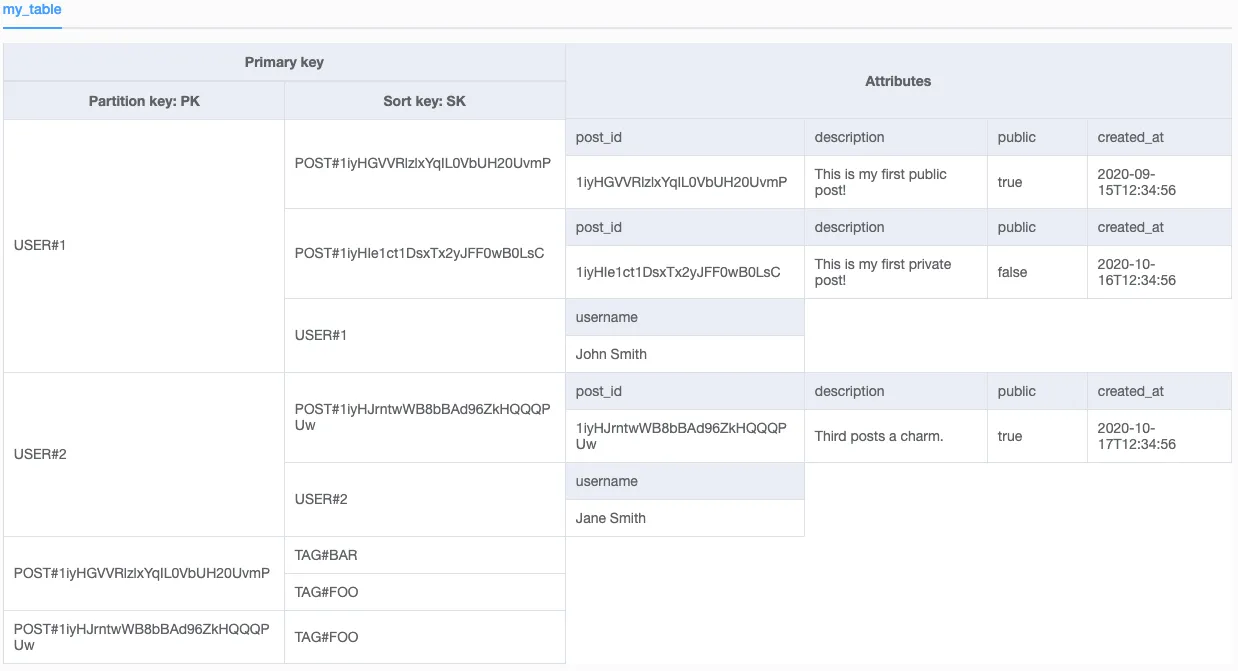
这样每个标签下的帖子,在表中都会有一个副本。我认为通过将标签作为第一个过滤器,可以有效地查询帖子,如果需要按标签查询它们。
user_id <string>
attachment_url <string>
description <string>
public <boolean>
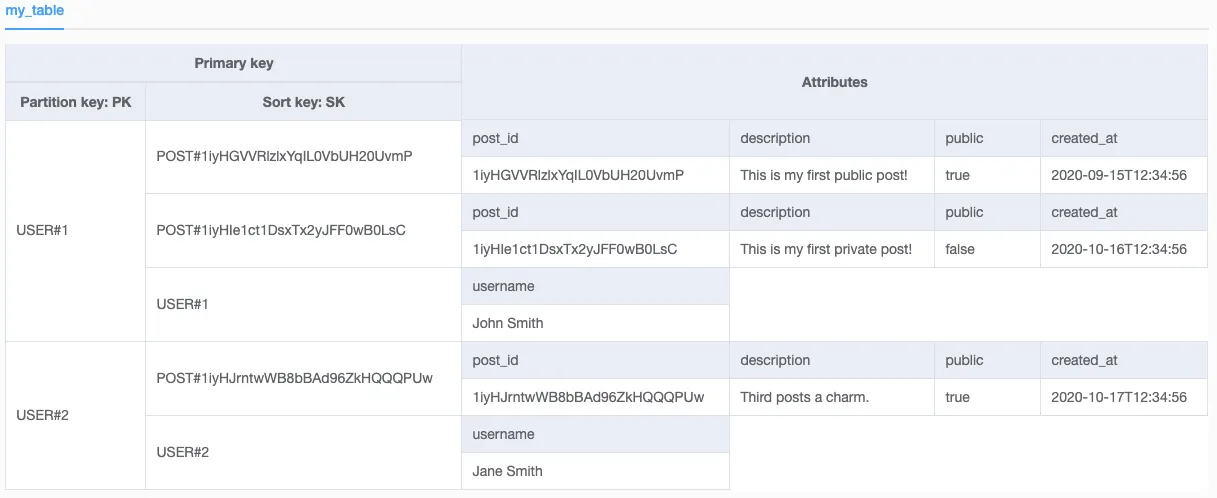
像模型:
user_id <string>
post_id <string>
type <string>
标签模型:
name <string>
我有几个访问模式:
- 获取所有公共帖子
- 获取所有按单个标签和公共状态过滤的帖子
- 按用户ID获取所有帖子
- 按帖子ID获取单个帖子
每次都需要获取带有标签数据和包含附加在喜欢中的用户数据的喜欢数据的帖子。在关系型数据库中,我会创建一个post_tags表,并通过标签获取所有帖子。但是,在dynamodb中该怎么做呢?
我正在努力弄清楚我的表应该长什么样子,以及在这种情况下应将哪些字段设置为主键和排序键,例如post_id、user_id、tag_name或public字段?
我的最初想法是构建一个实体类似于这样的表:
Partition key | Sort key | data attributes
tag_name | post_id | public | user_id | likes[] | other post attributes...
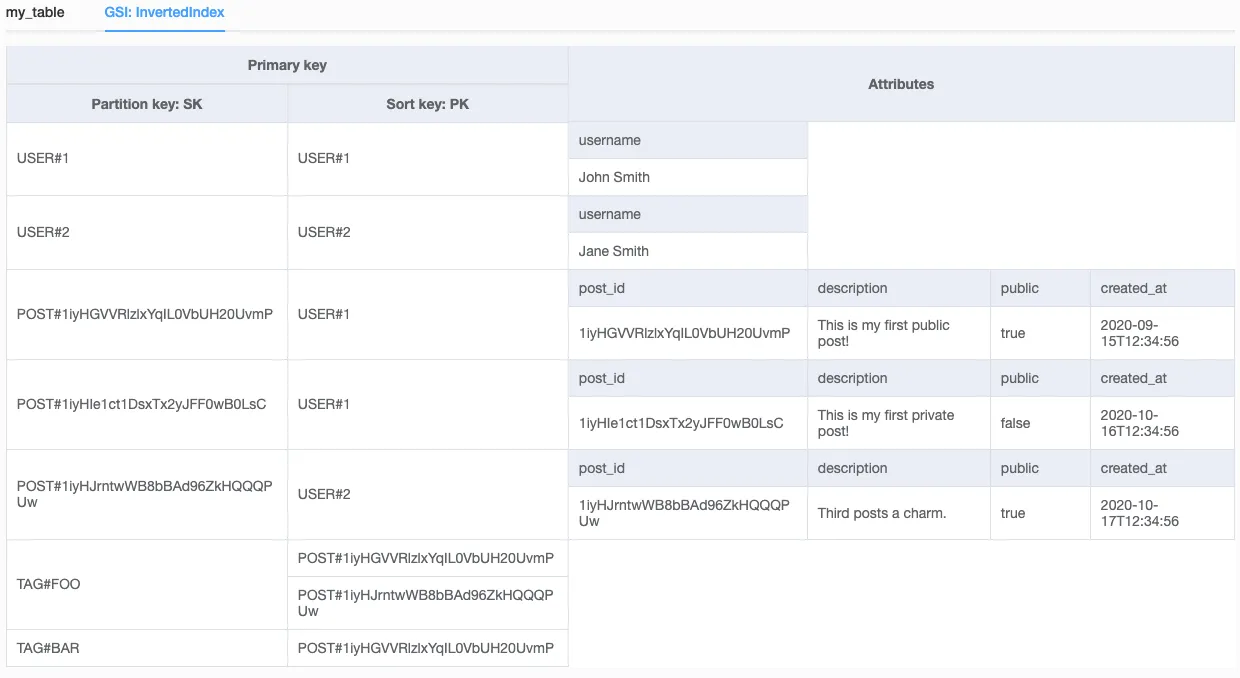
那么这个表格看起来会像这样:
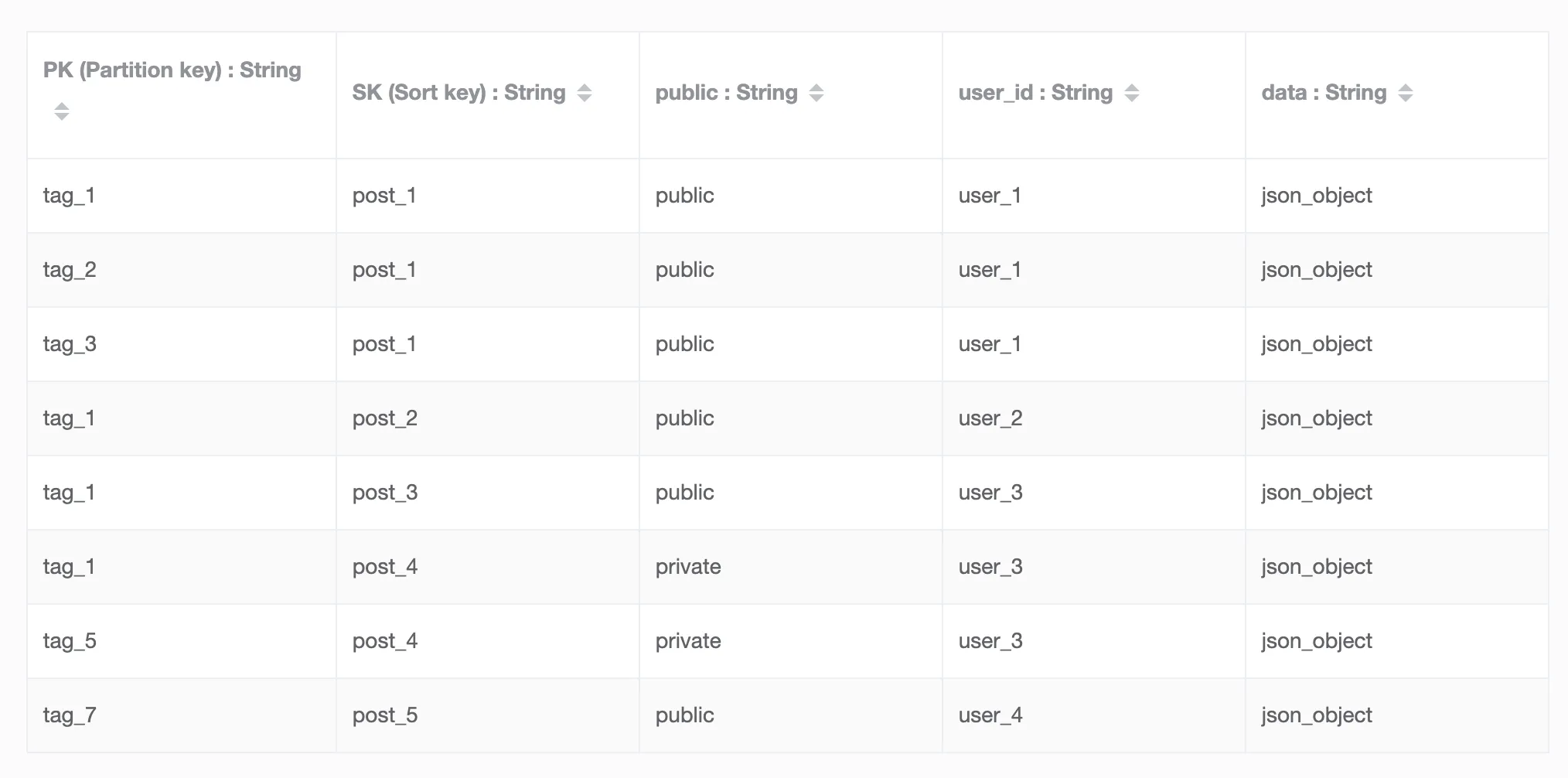
分区键设置为public,排序键设置为post_id
第二个全局次要索引:
分区键设置为user_id,排序键设置为post_id
这样每个标签下的帖子,在表中都会有一个副本。我认为通过将标签作为第一个过滤器,可以有效地查询帖子,如果需要按标签查询它们。
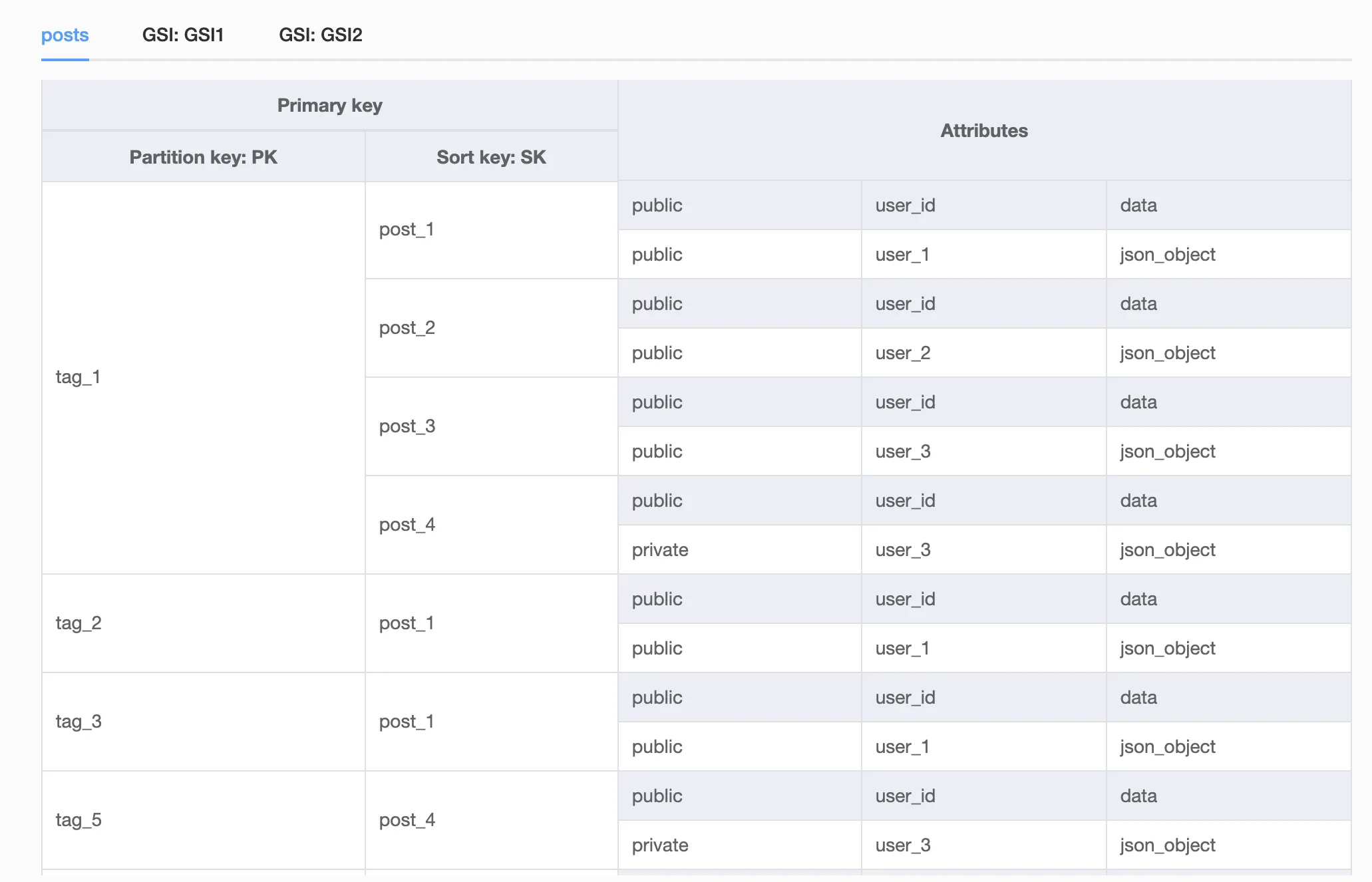
但是,如果我只按照公共状态或用户 ID进行查询,我将会获得每个标签下的所有重复帖子。
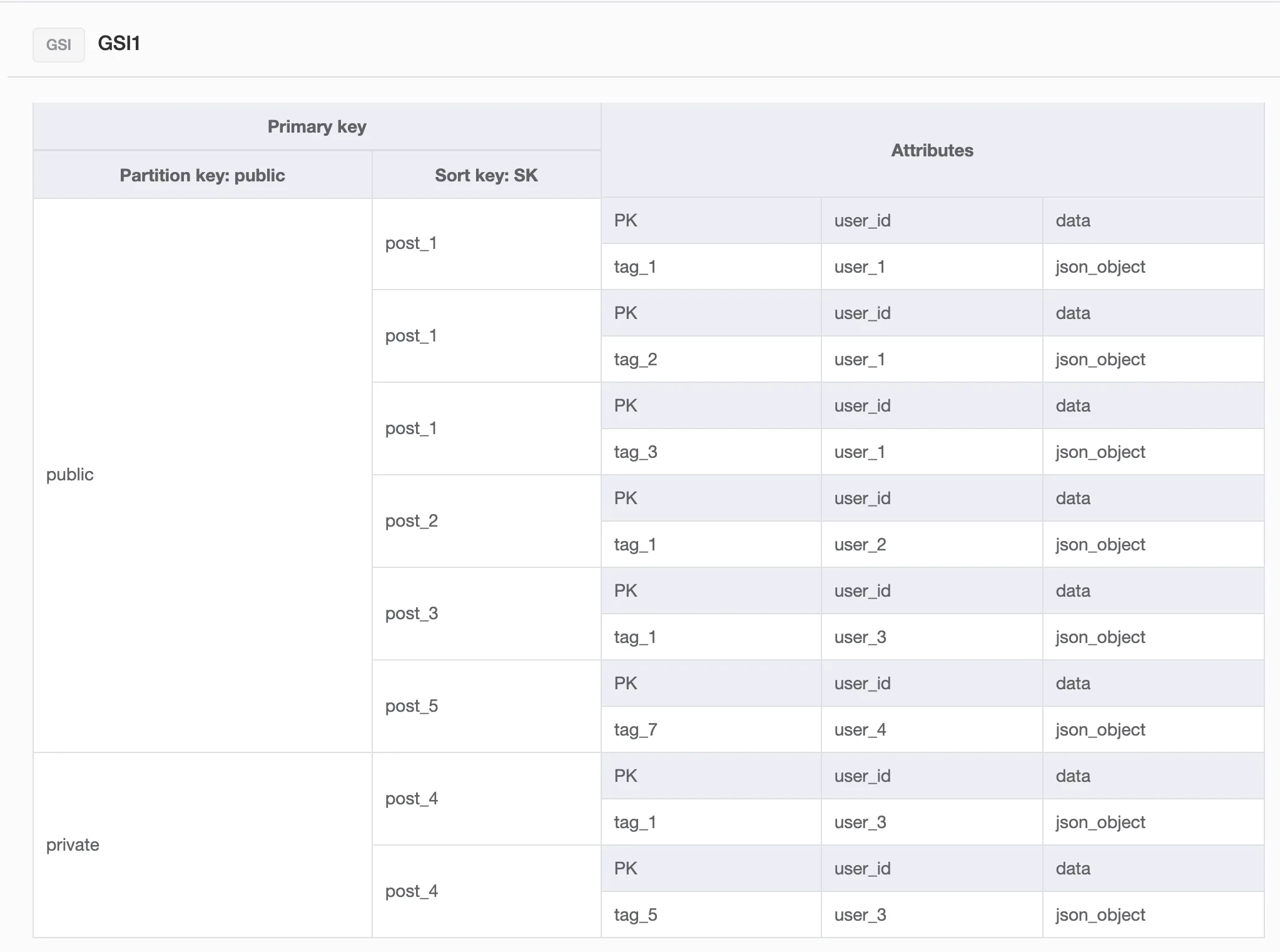
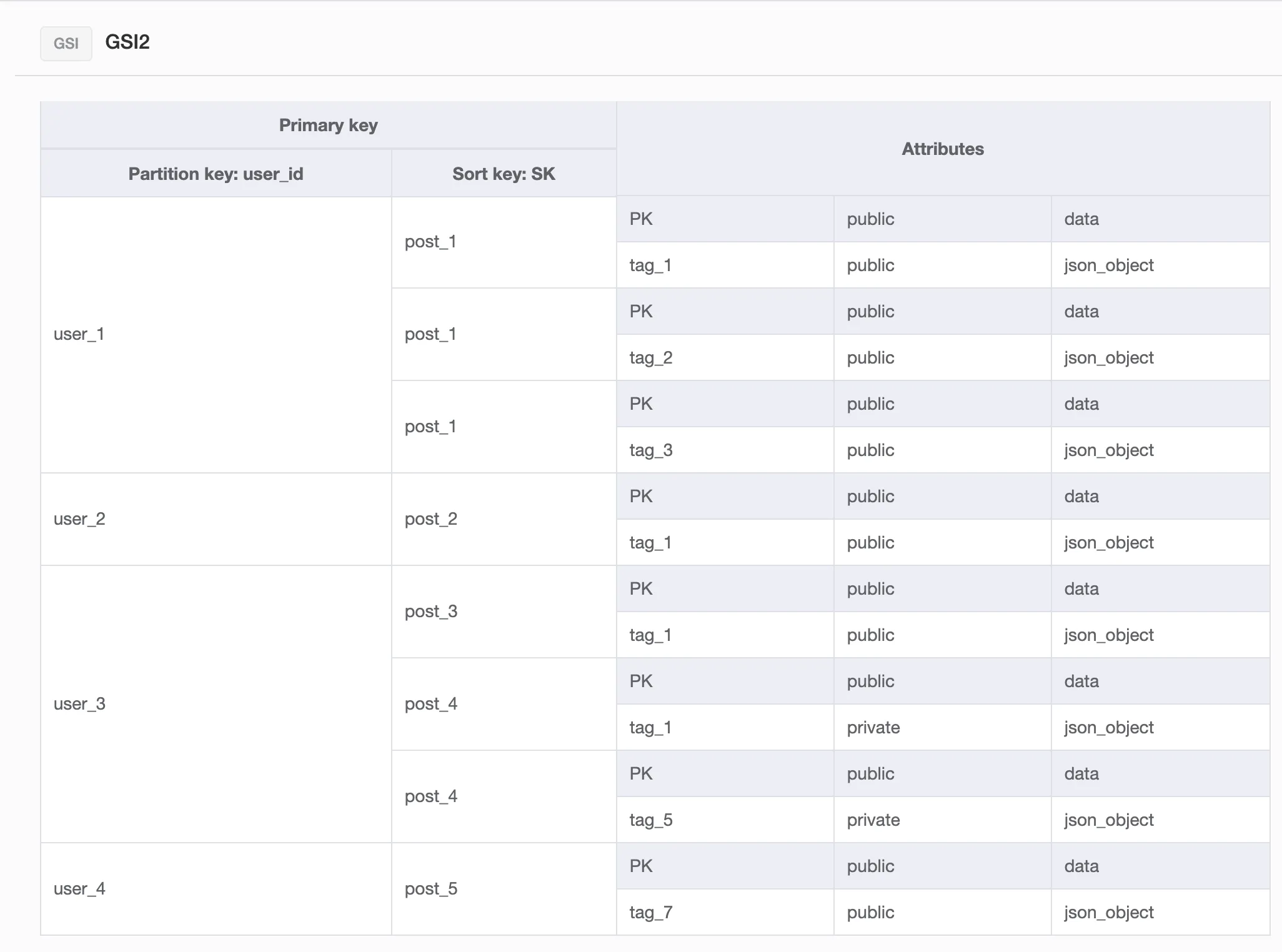
那么这个数据库结构应该如何呈现?