memset() 看起来比 mmap() 快大约一个数量级,至少在我目前能访问的 Solaris 11 服务器上是这样。我强烈怀疑 Linux 也会产生类似的结果。
我编写了一个小型基准测试程序:
#include <stdio.h>
#include <sys/mman.h>
#include <string.h>
#include <strings.h>
#include <sys/time.h>
#define NUM_BLOCKS ( 512 * 1024 )
#define BLOCKSIZE ( 4 * 1024 )
int main( int argc, char **argv )
{
int ii;
char *blocks[ NUM_BLOCKS ];
hrtime_t start = gethrtime();
for ( ii = 0; ii < NUM_BLOCKS; ii++ )
{
blocks[ ii ] = mmap( NULL, BLOCKSIZE,
PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_PRIVATE, -1, 0 );
blocks[ ii ][ ii % BLOCKSIZE ] = ii;
}
printf( "setup time: %lf sec\n",
( gethrtime() - start ) / 1000000000.0 );
for ( int jj = 0; jj < 4; jj++ )
{
start = gethrtime();
for ( ii = 0; ii < NUM_BLOCKS; ii++ )
{
blocks[ ii ] = mmap( blocks[ ii ],
BLOCKSIZE, PROT_READ | PROT_WRITE,
MAP_FIXED | MAP_ANONYMOUS | MAP_PRIVATE, -1, 0 );
blocks[ ii ][ ii % BLOCKSIZE ] = 0;
}
printf( "mmap() time: %lf sec\n",
( gethrtime() - start ) / 1000000000.0 );
start = gethrtime();
for ( ii = 0; ii < NUM_BLOCKS; ii++ )
{
memset( blocks[ ii ], 0, BLOCKSIZE );
}
printf( "memset() time: %lf sec\n",
( gethrtime() - start ) / 1000000000.0 );
}
return( 0 );
}
请注意,在页面的任何位置写入一个字节就足以强制创建物理页面。
我在我的Solaris 11文件服务器上运行了它(目前只有这个原生运行POSIX样式系统)。我没有在我的Solaris系统上测试madvise(),因为与Linux不同,Solaris不能保证映射将重新填充零填充页,只能保证“系统开始释放资源”。
结果如下:
setup time: 11.144852 sec
mmap() time: 15.159650 sec
memset() time: 1.817739 sec
mmap() time: 15.029283 sec
memset() time: 1.788925 sec
mmap() time: 15.083473 sec
memset() time: 1.780283 sec
mmap() time: 15.201085 sec
memset() time: 1.771827 sec
memset() 几乎快了一个数量级。我有机会时,会在 Linux 上重新运行该基准测试,但很可能必须在虚拟机上运行(AWS 等)。
这并不令人惊讶 - mmap() 很昂贵,内核仍然需要在某个时候清零页面。
有趣的是,注释掉一行
for ( ii = 0; ii < NUM_BLOCKS; ii++ )
{
blocks[ ii ] = mmap( blocks[ ii ],
BLOCKSIZE, PROT_READ | PROT_WRITE,
MAP_FIXED | MAP_ANONYMOUS | MAP_PRIVATE, -1, 0 );
}
产生以下结果:
setup time: 10.962788 sec
mmap() time: 7.524939 sec
memset() time: 10.418480 sec
mmap() time: 7.512086 sec
memset() time: 10.406675 sec
mmap() time: 7.457512 sec
memset() time: 10.296231 sec
mmap() time: 7.420942 sec
memset() time: 10.414861 sec
强制创建物理映射的负担已经转移到了
memset()调用上,仅在测试循环中有隐式的
munmap(),在这里,当
MAP_FIXEDmmap()调用替换它们时,映射将被销毁。请注意,仅
munmap()的时间比将页面保留在地址空间并将其
memset()成零要长3-4倍。
mmap()的成本实际上不是
mmap()/
munmap()系统调用本身,而是新页面需要大量的后台CPU周期来创建实际的物理映射,这并不发生在
mmap()系统调用本身 - 它发生在进程访问内存页面之后。
如果您对结果有疑问,请注意
Linus Torvalds本人的LMKL帖子:
...
然而,虚拟内存映射的游戏本身非常昂贵。它有许多相当真实的缺点,人们往往忽视它们,因为内存复制被认为是一件非常慢的事情,有时优化这种复制被视为一个明显的改进。
mmap 的缺点:
- 设置和清除成本非常高昂。我的意思是“非常显著”。这些东西包括跟随页表以清理所有映射的工作。它是维护所有映射列表的簿记工作。它是取消映射后需要清除 TLB。
- ...
使用Solaris Studio 的性能分析工具和分析器工具对代码进行分析,产生了以下输出:
Source File: mm.c
Inclusive Inclusive Inclusive
Total CPU Time Sync Wait Time Sync Wait Count Name
sec. sec.
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11. int main( int argc, char **argv )
<Function: main>
0.011 0. 0 12. {
13. int ii;
14.
15. char *blocks[ NUM_BLOCKS ];
16.
0. 0. 0 17. hrtime_t start = gethrtime();
18.
0.129 0. 0 19. for ( ii = 0; ii < NUM_BLOCKS; ii++ )
20. {
21. blocks[ ii ] = mmap( NULL, BLOCKSIZE,
22. PROT_READ | PROT_WRITE,
3.874 0. 0 23. MAP_ANONYMOUS | MAP_PRIVATE, -1, 0 );
24. // force the creation of the mapping
7.928 0. 0 25. blocks[ ii ][ ii % BLOCKSIZE ] = ii;
26. }
27.
28. printf( "setup time: %lf sec\n",
0. 0. 0 29. ( gethrtime() - start ) / 1000000000.0 );
30.
0. 0. 0 31. for ( int jj = 0; jj < 4; jj++ )
32. {
0. 0. 0 33. start = gethrtime();
34.
0.560 0. 0 35. for ( ii = 0; ii < NUM_BLOCKS; ii++ )
36. {
37. blocks[ ii ] = mmap( blocks[ ii ],
38. BLOCKSIZE, PROT_READ | PROT_WRITE,
33.432 0. 0 39. MAP_FIXED | MAP_ANONYMOUS | MAP_PRIVATE, -1, 0 );
29.535 0. 0 40. blocks[ ii ][ ii % BLOCKSIZE ] = 0;
41. }
42.
43. printf( "mmap() time: %lf sec\n",
0. 0. 0 44. ( gethrtime() - start ) / 1000000000.0 );
0. 0. 0 45. start = gethrtime();
46.
0.101 0. 0 47. for ( ii = 0; ii < NUM_BLOCKS; ii++ )
48. {
7.362 0. 0 49. memset( blocks[ ii ], 0, BLOCKSIZE );
50. }
51.
52. printf( "memset() time: %lf sec\n",
0. 0. 0 53. ( gethrtime() - start ) / 1000000000.0 );
54. }
55.
0. 0. 0 56. return( 0 );
0. 0. 0 57. }
Compile flags: /opt/SUNWspro/bin/cc -g -m64 mm.c -W0,-xp.XAAjaAFbs71a00k.
请注意在每个新映射页面中设置单个字节所花费的大量时间,以及在mmap()中花费的大量时间。
这是来自分析工具的概述。请注意系统时间的大量使用:
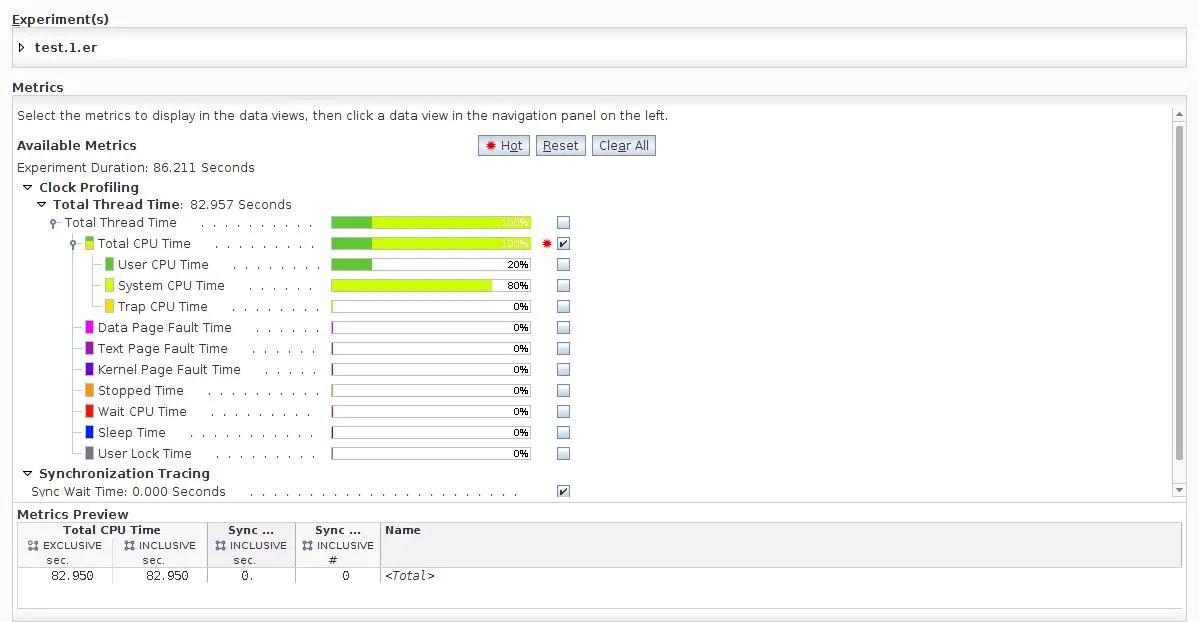
大量消耗的系统时间是用于映射和取消映射物理页面的时间。
这个时间轴展示了所有这些时间被消耗的时间点。
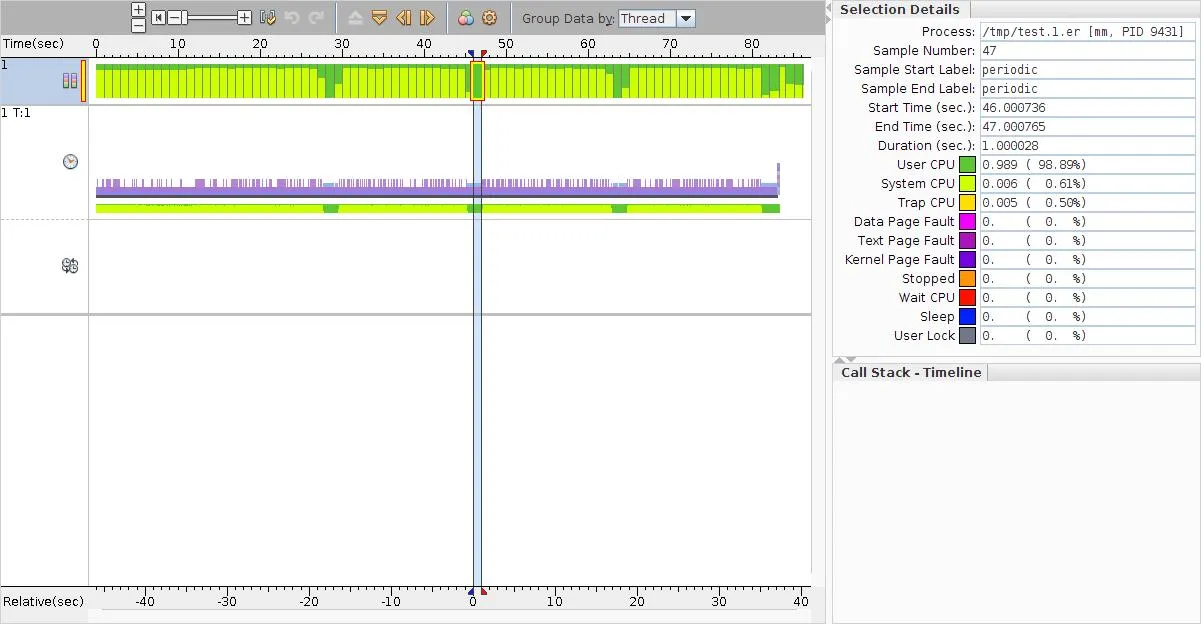
淡绿色是系统时间-这都在循环中。当循环运行时,您可以看到切换到深绿色用户时间。我已经突出了其中一个实例,以便您在那个时间看到发生了什么。
来自Linux虚拟机的更新结果:
setup time: 2.567396 sec
mmap() time: 2.971756 sec
memset() time: 0.654947 sec
mmap() time: 3.149629 sec
memset() time: 0.658858 sec
mmap() time: 2.800389 sec
memset() time: 0.647367 sec
mmap() time: 2.915774 sec
memset() time: 0.646539 sec
这与我昨天在评论中所说的完全一致:
顺便提一下,我进行的快速测试表明,对memset()进行简单的单线程调用比重新执行mmap()要快五到十倍
我根本不理解这种对
mmap()的迷恋。
mmap()是一个非常昂贵的调用,并且它是一个强制的单线程操作 - 机器上只有一组物理内存。
mmap()不仅
慢,而且会影响整个进程地址空间和整个主机上的VM系统。
使用任何形式的
mmap()来清零内存页面都是适得其反的。首先,页面不会免费清零 - 必须有
memset()将它们清除。为了清除一页RAM,添加拆除和重新创建内存映射到那个
memset()就毫无意义了。
memset()还具有这样的优点:
可以同时清除多个线程的内存。更改内存映射是单线程过程。
mmap()实际上不会清除内存。它只是从/dev/zero克隆页面,并设置COW。成本将在稍后产生,一旦(如果!)引用了这些页面。 - wildplassermemset()、madvise()和mmap()之间清除现有页面的时间差异,还计算了所有初始mmap()和最终munmaps()的时间,以及额外的循环来将'A'或'B'写入整个映射页面。这些都与性能差异无关,memset()、madvise()和mmap()之间的内存清零。顺便说一下,我运行的快速测试表明,简单的单线程调用memset()比重新执行mmap()要快五到十倍。 - Andrew Henle