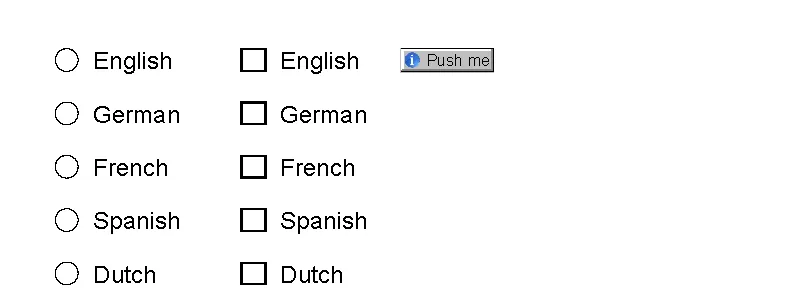
我想使用Java NetBeans从PDF中的按钮获取图像图标,并将其放置在某些面板中。然而,我遇到了麻烦。
我正在使用PDFBox作为我的PDF导出器,但似乎无法理解足够多的信息。
我已经成功地从表单字段中读取数据,但是在试图在PDFBox中找到按钮提取器时却没有找到。
我应该如何做?是否可以使用这种方法,或者有其他方法可以解决问题?
谢谢提前帮助。
编辑: 我已经找到了用以下代码提取图像的示例实用程序:
然而,我仍然无法从按钮图像中读取。顺便说一下,我阅读了这个页面上的教程,以将按钮图像添加到PDF中。 https://acrobatusers.com/tutorials/how-to-create-a-button-form-field-to-insert-a-pdf-file
第二次编辑: 在这里,我还给您链接到具有图标的PDF。PDF Link。 预先感谢您。
编辑: 我已经找到了用以下代码提取图像的示例实用程序:
File myFile = new File(filename);
try {
//PDDocument pdDoc = PDDocument.loadNonSeq( myFile, null );
PDDocument pdDoc = null;
pdDoc = PDDocument.load( myFile );
PDDocumentCatalog pdCatalog = pdDoc.getDocumentCatalog();
PDAcroForm pdAcroForm = pdCatalog.getAcroForm();
// dipakai untuk membaca isi file
List pages = pdDoc.getDocumentCatalog().getAllPages();
Iterator iter = pages.iterator();
while( iter.hasNext() )
{
PDPage page = (PDPage)iter.next();
PDResources resources = page.getResources();
Map images = resources.getImages();
if( images != null )
{
Iterator imageIter = images.keySet().iterator();
while( imageIter.hasNext() )
{
String key = (String )imageIter.next();
PDXObjectImage image = (PDXObjectImage)images.get(key);
BufferedImage imagedisplay= image.getRGBImage();
jLabel5.setIcon(new ImageIcon(imagedisplay)); // NOI18N
}
}
}
} catch (Exception e) {
JOptionPane.showMessageDialog(null, "error " + e.getMessage());
}
然而,我仍然无法从按钮图像中读取。顺便说一下,我阅读了这个页面上的教程,以将按钮图像添加到PDF中。 https://acrobatusers.com/tutorials/how-to-create-a-button-form-field-to-insert-a-pdf-file
第二次编辑: 在这里,我还给您链接到具有图标的PDF。PDF Link。 预先感谢您。