我一直试图学习神经网络中的反向传播(back-propagation)是如何工作的,但是还没有从非技术角度找到好的解释。
反向传播是如何工作的?它如何从提供的训练数据集中学习?我将不得不编写代码来实现它,但在那之前,我需要更加深入地了解它。
我一直试图学习神经网络中的反向传播(back-propagation)是如何工作的,但是还没有从非技术角度找到好的解释。
反向传播是如何工作的?它如何从提供的训练数据集中学习?我将不得不编写代码来实现它,但在那之前,我需要更加深入地了解它。
反向传播算法试图在神经网络的误差曲面上进行梯度下降,使用动态规划技术调整权重以使计算可行。
我将尝试用高级术语解释所有刚提到的概念。
如果你有一个具有 N 个输出神经元的神经网络,那么你的输出实际上是一个 N 维向量,这个向量存在于一个 N 维空间中(或者说存在于一个 N 维曲面上)。与此同时,你正在训练的“正确”输出也处于同样的空间中。你的实际输出与“正确”输出之间的差异也如此。
通过适当的条件(特别是一些绝对值的考虑),这种差异就成为了误差向量,它存在于误差曲面上。
基于这个概念,你可以将神经网络的训练过程视为调整神经元权重的过程,使得误差函数变小,最理想的情况是误差为零。从概念上讲,你需要使用微积分来实现这一点。如果你只有一个输出和一个权重,那么这个过程就很简单——求出几个导数,它们会告诉你应该向哪个“方向”移动,并进行相应的调整。
但是,你并不只拥有一个神经元,而是 N 个神经元,以及更多的输入权重。
原理是相同的,只不过你需要使用矢量代数表达式来替代在头脑中想象斜率的线上的微积分。术语梯度是多维空间中斜率的类比,而下降意味着你想要向下移动误差曲面,直到误差变小。
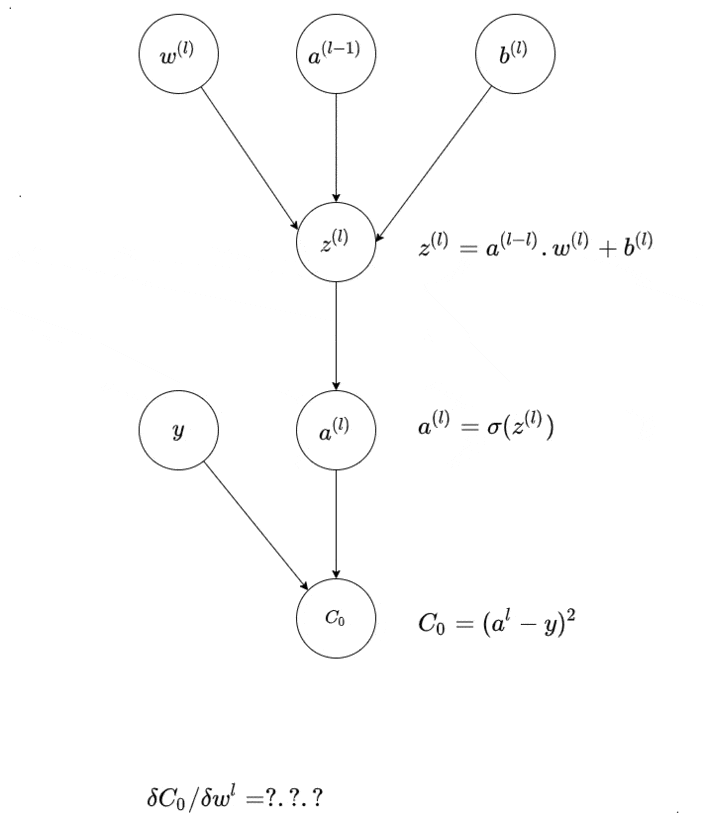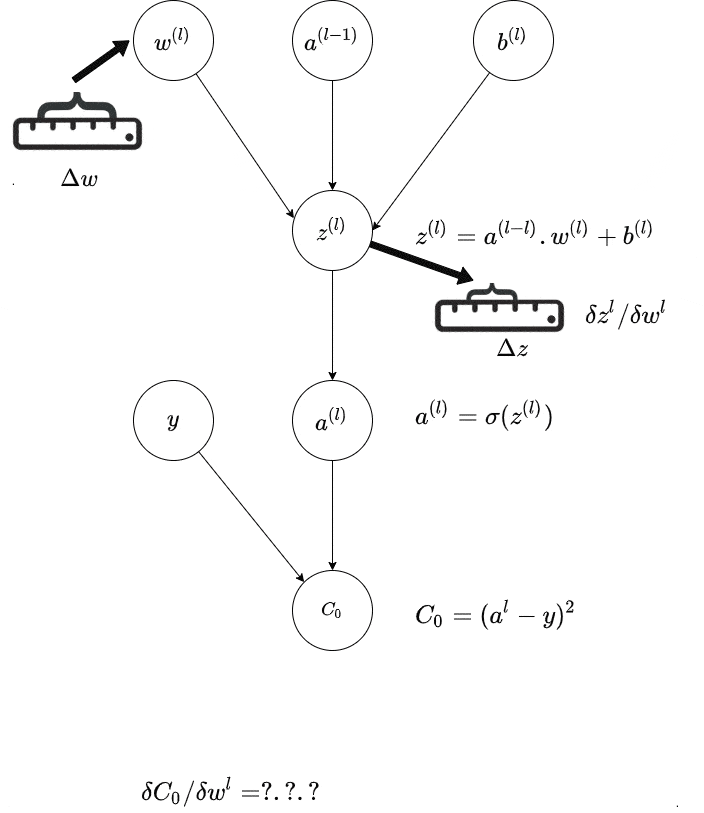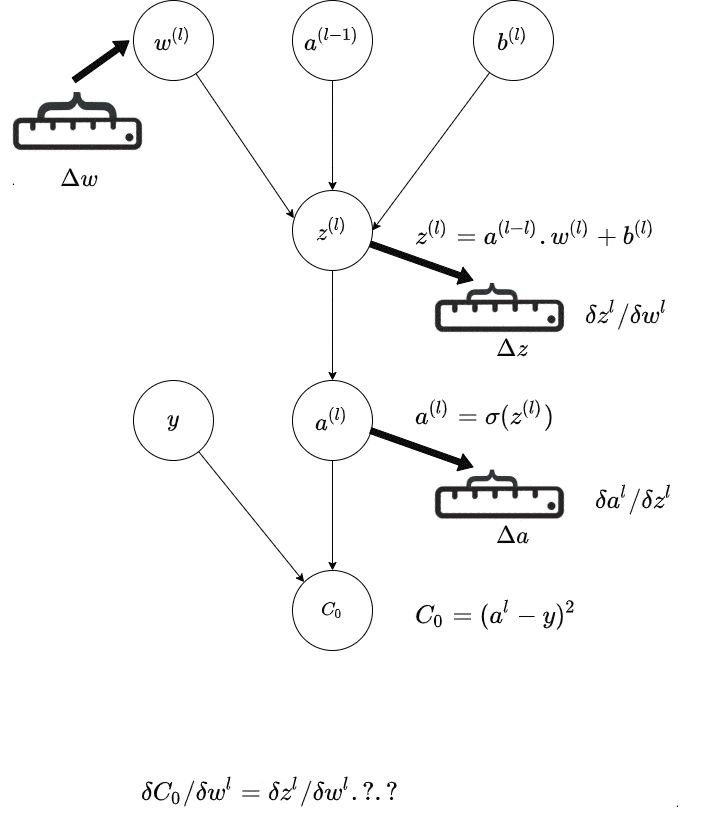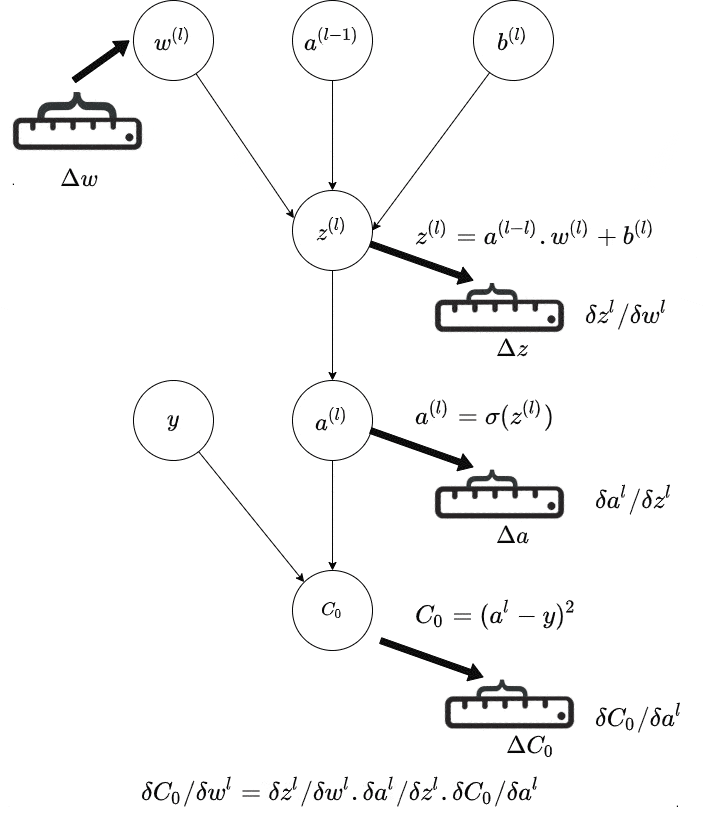
然而还有另一个问题——如果你有多层神经元,你无法轻松地看出某个非输出层与实际输出之间权重的变化。
动态规划是一种记账方法,用于帮助跟踪发生的情况。在最高层次上,如果你尝试天真地进行所有这些向量微积分,那么你最终会一遍又一遍地计算一些导数。现代反向传播算法避免了其中的一些问题,因此你首先更新输出层,然后是倒数第二层,以此类推。更新从输出向后传播,因此得名。
因此,如果你很幸运地接触过梯度下降或向量微积分,那么希望这可以让你理解。
反向传播的完整推导可以简化为大约一页紧凑的符号数学,但没有高层次的描述,很难理解该算法。(在我看来十分令人难以理解)。如果你对向量微积分没有很好的掌握,那么很抱歉,上面的内容可能并不有帮助。但是为了使反向传播实际工作,不必理解完整的推导过程。
当我尝试理解这个材料时,我发现了以下论文(作者为Rojas),即使它是他的一本书的一个章节的大PDF,也非常有帮助。
for each link in node.uplinks
error = link.destination.error
main = learningRate * error * node.output // The amount of change is based on error, output, and the learning rate
link.weight += main * alpha * momentum // adjust the weight based on the current desired change, alpha, and the "momentum" of the change.
link.momentum = main // Momentum is based on the last change.
学习率和alpha是可以设置的参数,用于调整它快速锁定解决方案的速度,以及最终(希望能够)准确地解决问题的能力。