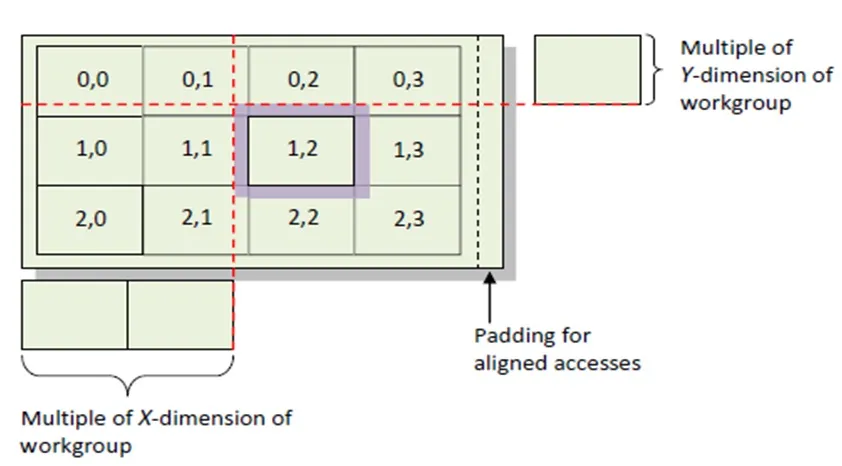
为了确保满足对齐要求,我多次阅读了《Heterogeneous Computing with OpenCL》第157页的以下段落。这展示了如何为图像卷积中的一个问题设置填充(假设16 x 16工作组大小)。
内存访问对齐
NVIDIA和AMD GPU上的性能都受益于全局内存中的数据对齐。特别是对于NVIDIA,将访问对齐在128字节边界上,并访问128字节段将理想地映射到内存硬件。然而,在此示例中,16宽的工作组仅将访问64字节段,因此数据应该对齐到64字节地址。这意味着每个工作组访问的第一列应该从64字节对齐地址开始。在此示例中,选择使边框像素不产生值决定所有工作组的偏移量将是工作组维度的倍数(即,对于16 x 16工作组,工作组将从列N * 16开始访问数据)。 为确保每个工作组正确对齐,则唯一的要求是使用额外的列填充输入数据,以便其宽度成为工作组的X维度的倍数。
1-有人可以帮助我理解如何在填充后使每个工作组访问的第一列从64字节对齐地址开始(就像上述段落中提到的要求吗?)
2-关于该图,语句是否正确:对于16 x 16工作组,工作组将从列N * 16开始访问数据。
如果是正确的,则图中显示的工作组1,2应该从第1列x16开始访问数据,这与图中所示的相反。 我完全困惑了!! :(
更新: 问题2现在对我来说已经清楚了。 实际上,在OpenCL约定中,图中显示的工作组是2,1(先按列),因此它是完全正确的:2x16 = 32而不是我所想的1x16。
但是问题1仍未得到解答。