TensorFlow无法检测到GPU的问题可能由以下原因之一引起:
- 系统中仅安装了TensorFlow的CPU版本。
- 系统中同时安装了TensorFlow的CPU和GPU版本,但Python环境优先选择了CPU版本。
在解决该问题之前,我们假设已安装的环境是AWS深度学习AMI,其中已安装了CUDA 8.0和TensorFlow版本1.4.1。该假设源自评论中的讨论。
要解决该问题,请按照以下步骤进行操作:
- 通过在操作系统终端执行以下命令来检查已安装的TensorFlow版本。
pip freeze | grep tensorflow
- 如果仅安装了CPU版本,则通过执行以下命令删除它并安装GPU版本。
pip uninstall tensorflow
pip install tensorflow-gpu==1.4.1
- 如果同时安装了CPU和GPU版本,则删除两者并仅安装GPU版本。
pip uninstall tensorflow
pip uninstall tensorflow-gpu
pip install tensorflow-gpu==1.4.1
如果tensorflow的所有依赖项都正确安装,则TensorFlow GPU版本应该可以正常工作。在这个阶段遇到的常见错误(如OP所遇)是缺少cuDNN库,可能会导致在将tensorflow导入python模块时出现以下错误:
ImportError: libcudnn.so.6: 无法打开共享对象文件: 没有那个文件或目录
可以通过安装正确版本的NVIDIA的cuDNN库来解决。Tensorflow版本1.4.1依赖于cuDNN版本6.0和CUDA 8,因此我们从cuDNN归档页面下载相应版本 (下载链接)。我们必须登录NVIDIA开发者账户才能下载文件,因此不能使用命令行工具(如wget或curl)进行下载。一个可能的解决方案是在主机系统上下载文件,然后使用scp将其复制到AWS上。
复制到AWS上后,使用以下命令提取文件:
tar -xzvf cudnn-8.0-linux-x64-v6.0.tgz
提取出的目录应该具有类似CUDA工具包安装目录的结构。假设CUDA工具包已安装在目录
/usr/local/cuda中,我们可以通过将从已下载存档中提取的文件复制到CUDA工具包安装目录的相应文件夹,然后执行链接器更新命令
ldconfig来安装cuDNN,具体如下所示:
cp cuda/include/* /usr/local/cuda/include
cp cuda/lib64/* /usr/local/cuda/lib64
ldconfig
之后,我们应该能够将tensorflow GPU版本导入python模块。
注意事项:
- 如果使用Python3,则应将
pip替换为pip3。
- 根据用户权限,可能需要以
sudo身份运行pip、cp和ldconfig命令。
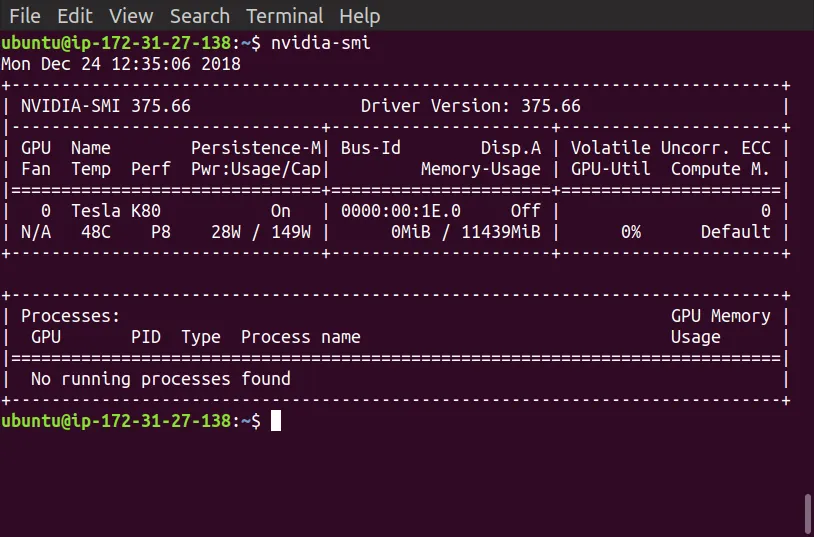
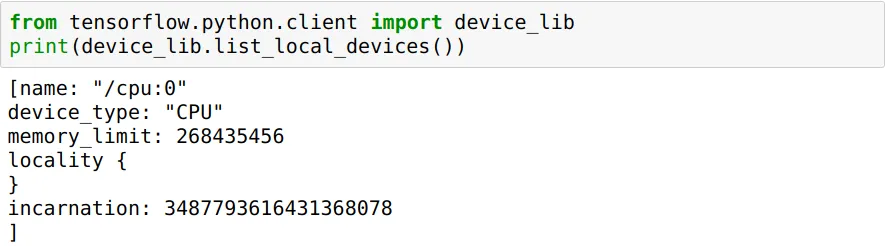
pip freeze | grep tensorflow,以确定已安装的软件包是tensorflow还是tensorflow-gpu。它应该是tensorflow-gpu才能利用 GPU。 - T.Ztensorflow之后,您还需要重新安装tensorflow-gpu。这意味着您只需执行pip uninstall tensorflow-gpu && pip install tensorflow-gpu即可。 - T.Zpip uninstall tensorflow-gpu && pip install tensorflow-gpu==1.4.1。 - T.Z