这是一种方法。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import seaborn as sns; sns.set()
import csv
df = pd.read_csv('C:\\business.csv')
df.dropna(axis=0,how='any',subset=['latitude','longitude'],inplace=True)
K_clusters = range(1,10)
kmeans = [KMeans(n_clusters=i) for i in K_clusters]
Y_axis = df[['latitude']]
X_axis = df[['longitude']]
score = [kmeans[i].fit(Y_axis).score(Y_axis) for i in range(len(kmeans))]
plt.plot(K_clusters, score)
plt.xlabel('Number of Clusters')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show()
X = df[['longitude', 'latitude']].copy()
kmeans = KMeans(n_clusters = 5, init ='k-means++')
kmeans.fit(X[X.columns[1:2]])
X['cluster_label'] = kmeans.fit_predict(X[X.columns[1:3]])
centers = kmeans.cluster_centers_
labels = kmeans.predict(X[X.columns[1:2]])
X.head(10)
X.plot.scatter(x = 'latitude', y = 'longitude', c=labels, s=50, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5)
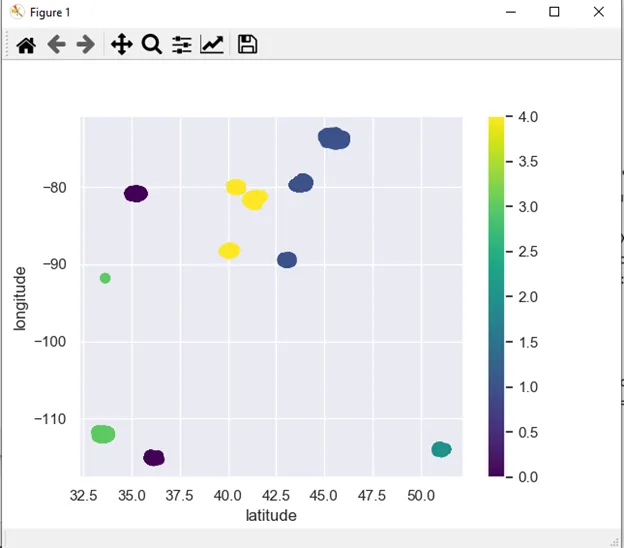
这里还有一个想法。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from collections import Counter
df = pd.read_csv('C:\\properties_2017.csv')
df = df.head(10000)
list(df)
df.shape
df.shape
df = df.sample(frac=0.2, replace=True, random_state=1)
df.shape
df = df.fillna(0)
df.isna().sum()
df['regionidzip']=df['regionidzip'].fillna(97000)
df.dropna(axis=0,how='any',subset=['latitude','longitude'],inplace=True)
X=df.loc[:,['latitude','longitude']]
zp=df.regionidzip
id_n=8
kmeans = KMeans(n_clusters=id_n, random_state=0).fit(X)
id_label=kmeans.labels_
ptsymb = np.array(['b.','r.','m.','g.','c.','k.','b*','r*','m*','r^']);
plt.figure(figsize=(12,12))
plt.ylabel('Longitude', fontsize=12)
plt.xlabel('Latitude', fontsize=12)
for i in range(id_n):
cluster=np.where(id_label==i)[0]
plt.plot(X.latitude[cluster].values,X.longitude[cluster].values,ptsymb[i])
plt.show()
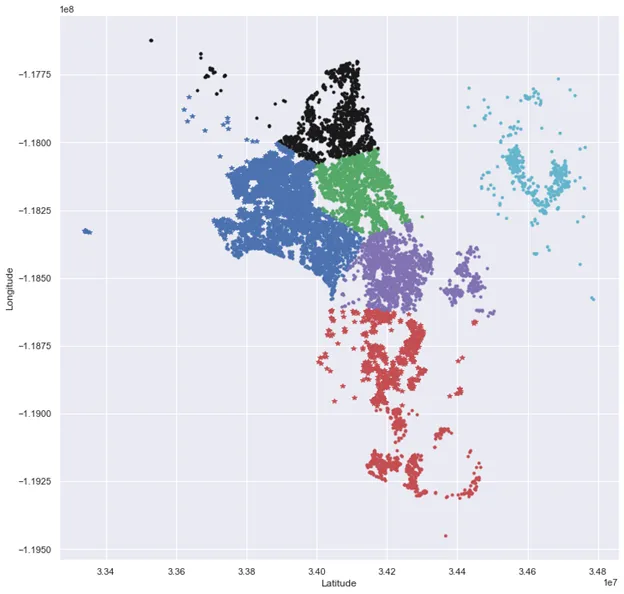
uniq_zp=np.unique(zp)
for i in uniq_zp:
a=np.where(zp==i)[0]
c = Counter(id_label[a])
c.most_common(1)[0][0]
id_label[a]=c.most_common(1)[0][0]
plt.figure(figsize=(12,12))
plt.ylabel('Longitude', fontsize=12)
plt.xlabel('Latitude', fontsize=12)
for i in range(id_n):
cluster=np.where(id_label==i)[0]
plt.plot(X.latitude[cluster].values,X.longitude[cluster].values,ptsymb[i])
plt.show()
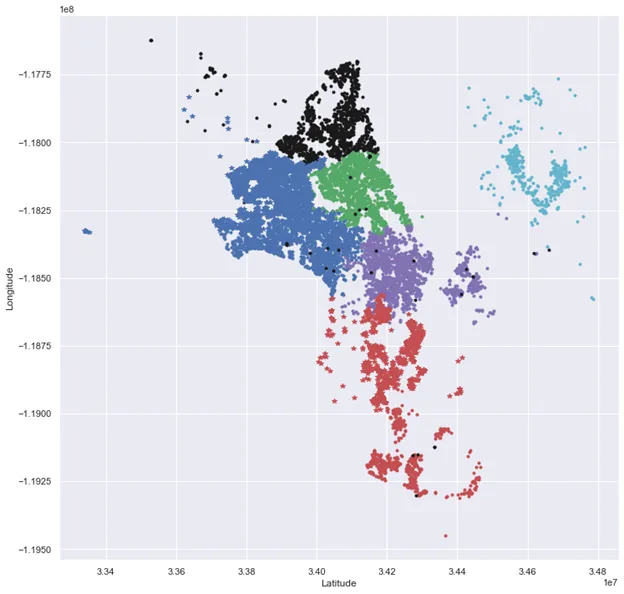
此处 提供了一个关于经纬度k均值聚类的案例,相关内容涉及it技术。
此处 提供了有关房价预测的数据集,相关内容涉及it技术。
另外,可以查看此处提供的内容,了解如何对地理位置信息进行聚类分析。
此处提供了一个数据存储的csv文件,相关内容涉及it技术。