在RStudio控制台上打印时看起来完全正常,但在写入csv并使用Excel打开时会出现奇怪字符的字符字符串。
可重复示例
以下代码生成了一个名为"a wit"的对象,并将其写入csv:
# install.packages("dplyr")
library(dplyr)
serialized_char <- "580a000000030003060200030500000000055554462d380000001000000001000080090000000661c2a0776974"
(string <- serialized_char %>%
{substring(., seq(1, nchar(.), 2), seq(2, nchar(.), 2))} %>%
paste0("0x", .) %>%
as.integer %>%
as.raw %>%
unserialize())
[1] "a wit"
write.csv(string, "myfile.csv", row.names=F)
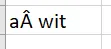
这是从 Mojave 中编写的样子(在MacOS Mojave中用Excel查看)- 包含不良字符:
 这是从 High Sierra 中编写的样子(在High Sierra中用Excel查看)- 包含不良字符:
这是从 High Sierra 中编写的样子(在High Sierra中用Excel查看)- 包含不良字符:
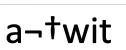 当从 Windows 10 编写并在Windows 10上用Excel查看时,它看起来正常!
当从 Windows 10 编写并在Windows 10上用Excel查看时,它看起来正常!
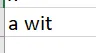 这是从 Mojave 编写的样子,但在Windows 10上用Excel查看 - 仍然包含不良字符:
这是从 Mojave 编写的样子,但在Windows 10上用Excel查看 - 仍然包含不良字符:
问题
我有很多这种形式的字符数据(在CSV格式下打开Excel时看起来奇怪),如何清理这些数据,使文本在Excel中呈现正常。
我尝试过的方法
我已经尝试了4件事情
write.csv(string, "myfile.csv", fileEncoding = 'UTF-8')
Encoding(string) <- "latin-1"
Encoding(string) <- "UTF-8"
iconv(string, "UTF-8", "latin1", sub=NA)
"a wit",使得identical(a_wit_from_above, "a wit")为TRUE吗? - steveciconv(stringi::stri_trans_nfkd(x), 'UTF-8', 'ASCII', sub=''); 使用它,'ä\ua0test'将变成'a test'。 - Konrad Rudolph