您需要阅读编程指南的附录J,尤其是 J.2.2节。
使用统一内存时,使用cudaMallocManaged分配的内存默认情况下会附加到所有流(“全局”),我们必须修改此设置,以便有效地利用流,例如实现计算/复制重叠。我们可以使用cudaStreamAttachMemAsync函数来完成此操作,如J.2.2.3节所述。通过将每个内存“块”与一个流相关联,UM子系统可以智能地决定何时传输每个数据项。
以下示例演示了这一点:
#include <stdio.h>
#include <time.h>
#define DSIZE 1048576
#define DWAIT 100000ULL
#define nTPB 256
#define cudaCheckErrors(msg) \
do { \
cudaError_t __err = cudaGetLastError(); \
if (__err != cudaSuccess) { \
fprintf(stderr, "Fatal error: %s (%s at %s:%d)\n", \
msg, cudaGetErrorString(__err), \
__FILE__, __LINE__); \
fprintf(stderr, "*** FAILED - ABORTING\n"); \
exit(1); \
} \
} while (0)
typedef int mytype;
__global__ void mykernel(mytype *data){
int idx = threadIdx.x+blockDim.x*blockIdx.x;
if (idx < DSIZE) data[idx] = 1;
unsigned long long int tstart = clock64();
while (clock64() < tstart + DWAIT);
}
int main(){
mytype *data1, *data2, *data3;
cudaStream_t stream1, stream2, stream3;
cudaMallocManaged(&data1, DSIZE*sizeof(mytype));
cudaMallocManaged(&data2, DSIZE*sizeof(mytype));
cudaMallocManaged(&data3, DSIZE*sizeof(mytype));
cudaCheckErrors("cudaMallocManaged fail");
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaStreamCreate(&stream3);
cudaCheckErrors("cudaStreamCreate fail");
cudaStreamAttachMemAsync(stream1, data1);
cudaStreamAttachMemAsync(stream2, data2);
cudaStreamAttachMemAsync(stream3, data3);
cudaDeviceSynchronize();
cudaCheckErrors("cudaStreamAttach fail");
memset(data1, 0, DSIZE*sizeof(mytype));
memset(data2, 0, DSIZE*sizeof(mytype));
memset(data3, 0, DSIZE*sizeof(mytype));
mykernel<<<(DSIZE+nTPB-1)/nTPB, nTPB, 0, stream1>>>(data1);
mykernel<<<(DSIZE+nTPB-1)/nTPB, nTPB, 0, stream2>>>(data2);
mykernel<<<(DSIZE+nTPB-1)/nTPB, nTPB, 0, stream3>>>(data3);
cudaDeviceSynchronize();
cudaCheckErrors("kernel fail");
for (int i = 0; i < DSIZE; i++){
if (data1[i] != 1) {printf("data1 mismatch at %d, should be: %d, was: %d\n", i, 1, data1[i]); return 1;}
if (data2[i] != 1) {printf("data2 mismatch at %d, should be: %d, was: %d\n", i, 1, data2[i]); return 1;}
if (data3[i] != 1) {printf("data3 mismatch at %d, should be: %d, was: %d\n", i, 1, data3[i]); return 1;}
}
printf("Success!\n");
return 0;
}
上述程序创建了一个内核,使用
clock64()使其人工运行时间变长,以便给我们提供计算/复制重叠的模拟机会(模拟计算密集型内核)。我们启动了3个此内核实例,每个实例都在单独的“数据块”上操作。
当我们对上述程序进行分析时,可以看到以下内容:
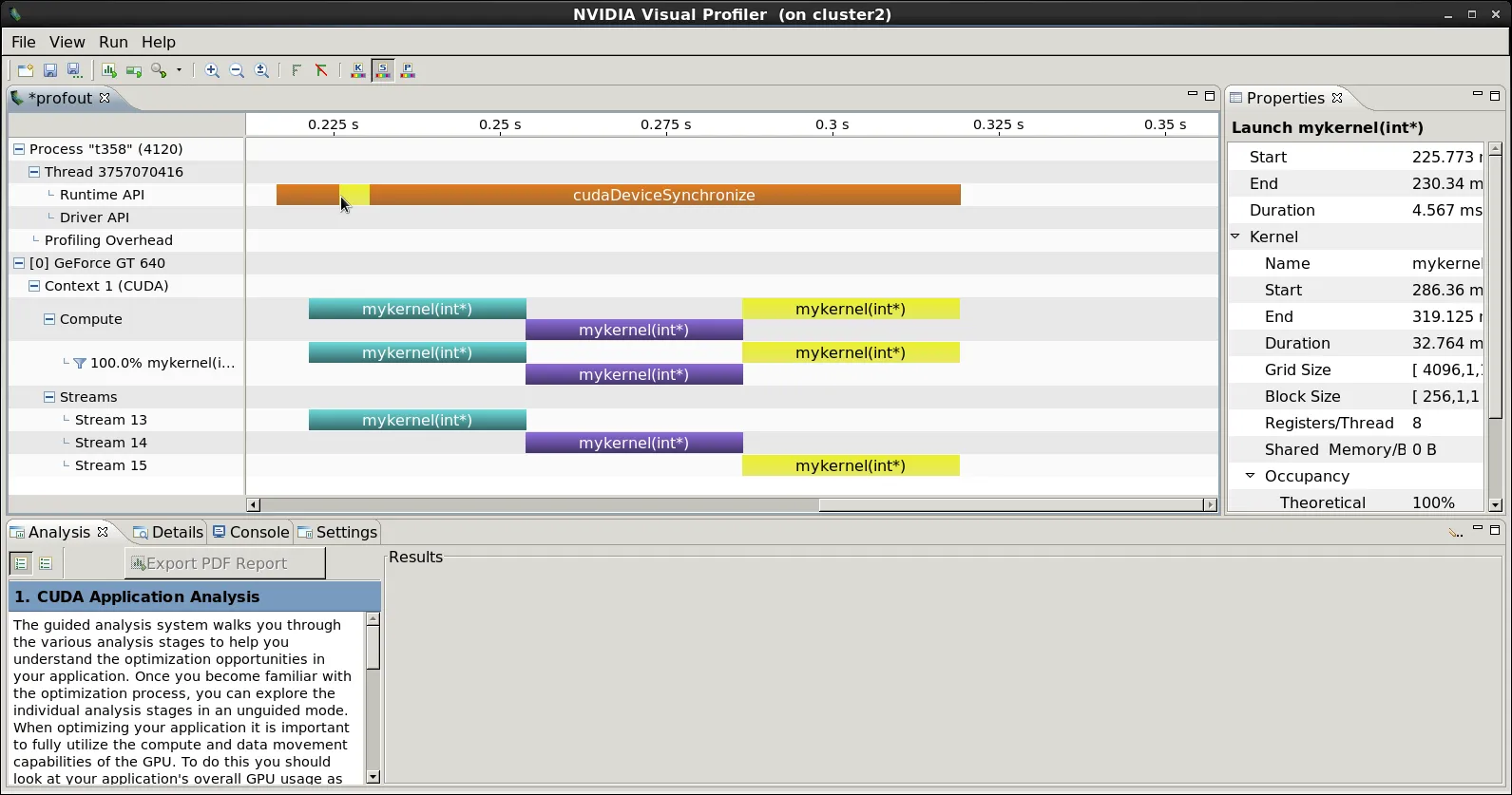 首先,请注意第三个内核启动被黄色突出显示,并且它紧随着紫色突出显示的第二个内核启动。在运行时API线中由鼠标指针指示了这个第三个内核的实际
首先,请注意第三个内核启动被黄色突出显示,并且它紧随着紫色突出显示的第二个内核启动。在运行时API线中由鼠标指针指示了这个第三个内核的实际cudaLaunch运行时API事件,也被黄色突出显示(并且在第一个2个内核的cudaLaunch事件之前)。由于该启动发生在第一个内核执行期间,并且从那一点到第三个内核开始没有任何中间的“空白空间”,因此我们可以观察到第三个内核的数据传输(即data3)发生在内核1和2正在执行时。因此,我们实现了复制和计算的有效重叠。(我们可以对内核2做出类似的观察)。
虽然我在这里没有展示它,但是如果我们省略cudaStreamAttachMemAsync行,程序仍然可以编译和运行正确,但是如果我们对其进行分析,我们会观察到cudaLaunch事件和内核之间的不同关系。整个配置文件看起来类似,并且内核正在依次执行,但是整个cudaLaunch过程现在在第一个内核开始执行之前开始并结束,并且在内核执行期间没有任何cudaLaunch事件。这表明(由于所有的cudaMallocManaged内存都是全局的),所有的数据传输都在第一个内核启动之前发生。程序无法将“全局”分配与任何特定的内核相关联,因此所有这样分配的内存都必须在第一个内核启动之前转移(即使该内核仅使用data1)。