我正在使用 subprocess.run() 进行一些自动化测试。主要是用于自动化执行以下操作:
dummy.exe < file.txt > foo.txt
diff file.txt foo.txt
如果您在shell中执行上述重定向,则两个文件始终相同。但是,每当
file.txt 太长时,下面的Python代码就不会返回正确的结果。这是Python代码:
import subprocess
import sys
def main(argv):
exe_path = r'dummy.exe'
file_path = r'file.txt'
with open(file_path, 'r') as test_file:
stdin = test_file.read().strip()
p = subprocess.run([exe_path], input=stdin, stdout=subprocess.PIPE, universal_newlines=True)
out = p.stdout.strip()
err = p.stderr
if stdin == out:
print('OK')
else:
print('failed: ' + out)
if __name__ == "__main__":
main(sys.argv[1:])
这里是在dummy.cc中的C++代码:
#include <iostream>
int main()
{
int size, count, a, b;
std::cin >> size;
std::cin >> count;
std::cout << size << " " << count << std::endl;
for (int i = 0; i < count; ++i)
{
std::cin >> a >> b;
std::cout << a << " " << b << std::endl;
}
}
file.txt 可以是像这样的任何东西:
1 100000
0 417
0 842
0 919
...
第一行的第二个整数表示接下来有多少行,因此这里的file.txt将会有100,001行。
问题:我是否误用了subprocess.run()?
编辑:
考虑到注释(换行符和rb),我的Python代码如下:
import subprocess
import sys
import os
def main(argv):
base_dir = os.path.dirname(__file__)
exe_path = os.path.join(base_dir, 'dummy.exe')
file_path = os.path.join(base_dir, 'infile.txt')
out_path = os.path.join(base_dir, 'outfile.txt')
with open(file_path, 'rb') as test_file:
stdin = test_file.read().strip()
p = subprocess.run([exe_path], input=stdin, stdout=subprocess.PIPE)
out = p.stdout.strip()
if stdin == out:
print('OK')
else:
with open(out_path, "wb") as text_file:
text_file.write(out)
if __name__ == "__main__":
main(sys.argv[1:])
这是第一个差异:
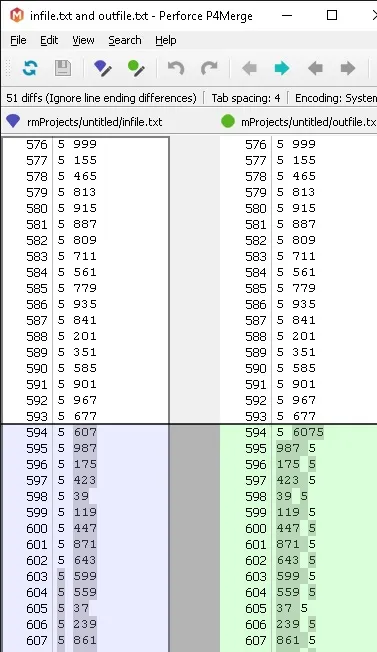
这是输入文件: https://drive.google.com/open?id=0B--mU_EsNUGTR3VKaktvQVNtLTQ
sys.stdout.flush()。这个文件的长度多长才算太长? - Chrispresso