构建和部署Spark应用时常见问题有:
java.lang.ClassNotFoundException。object x is not a member of package y编译错误。java.lang.NoSuchMethodError
如何解决这些问题?
构建和部署Spark应用时常见问题有:
java.lang.ClassNotFoundException。object x is not a member of package y 编译错误。java.lang.NoSuchMethodError如何解决这些问题?
SparkSession(或SparkContext)并连接到集群管理器以执行实际工作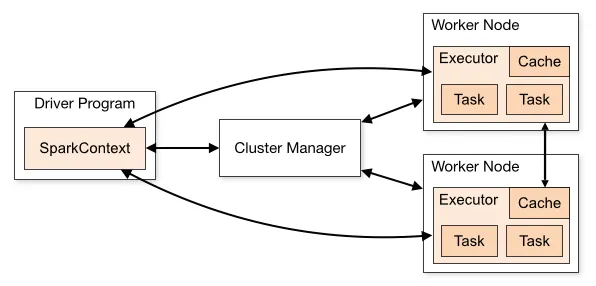
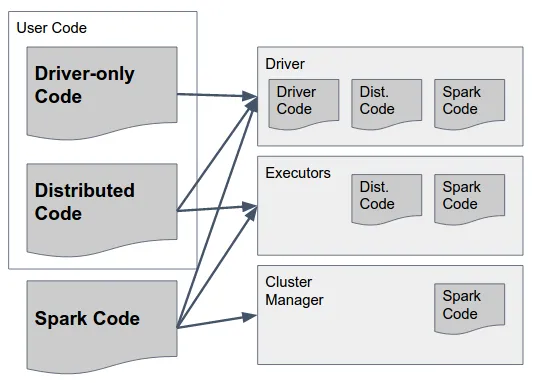
让我们慢慢解析:
Spark Code 是 Spark 的库。它们应该存在于所有三个组件中,因为它们包括让 Spark 在它们之间执行通信的粘合剂。顺便说一句 - Spark 作者做出了一个设计决策,将所有组件的代码都包含在所有组件中(例如,在 Executor 中只应运行的代码也包含在 driver 中),以简化这个过程 - 因此,Spark 的“fat jar”(在版本1.6及以下)或“archive”(在2.0中,下面有详细信息)包含所有组件所需的必要代码,并应在所有组件中可用。
Driver-Only Code 这是用户代码,不包括任何应在 Executors 上使用的内容,即不在 RDD / DataFrame / Dataset 的任何转换中使用的代码。这不一定需要与分布式用户代码分开,但可以这样做。
Distributed Code 这是与 driver 代码一起编译的用户代码,但也必须在 Executors 上执行 - 所有实际变换使用的内容都必须包含在这些 jar 文件中。
Spark代码:正如之前的答案所述,所有组件都必须使用相同的Scala和Spark版本。
1.1 在独立模式下,有一个“预先存在”的Spark安装程序,应用程序(驱动程序)可以连接到该安装程序。这意味着所有驱动程序必须使用运行在主节点和执行器上的相同Spark版本。
1.2 在YARN/Mesos中,每个应用程序可以使用不同的Spark版本,但同一应用程序的所有组件必须使用相同的版本。这意味着,如果您使用版本X编译和打包驱动程序应用程序,则在启动SparkSession时应提供相同的版本(例如,通过spark.yarn.archive或spark.yarn.jars参数使用YARN)。您提供的Jars/Archive应包括所有Spark依赖项(包括传递依赖关系),并且将在应用程序启动时由群集管理器发送到每个执行器。
驱动程序代码:完全由您决定-驱动程序代码可以作为一堆Jar文件或一个“fat Jar”进行传输,只要它包含所有Spark依赖项+所有用户代码即可。
分布式代码:除了驱动程序之外,此代码必须被传输到执行器上(再次与其所有传递性依赖项一起)。这是使用spark.jars参数完成的。
总之,这里提供了一种构建和部署Spark应用程序(在本例中使用YARN)的建议方法:
SparkSession时,将正确版本的分布式代码作为spark.jars参数的值传递。lib/文件夹中的所有jar文件的归档文件(例如gzip)的位置作为spark.yarn.archive参数的值传递。在构建和部署Spark应用程序时,所有依赖项都需要兼容的版本。
Scala版本。所有软件包都必须使用相同的主要(2.10、2.11、2.12)Scala版本。
考虑以下(不正确的)build.sbt:
name := "Simple Project"
version := "1.0"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "2.0.1",
"org.apache.spark" % "spark-streaming_2.10" % "2.0.1",
"org.apache.bahir" % "spark-streaming-twitter_2.11" % "2.0.1"
)
我们在Scala 2.10中使用spark-streaming,而其余包都是为Scala 2.11准备的。一个有效文件可能是:
name := "Simple Project"
version := "1.0"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "2.0.1",
"org.apache.spark" % "spark-streaming_2.11" % "2.0.1",
"org.apache.bahir" % "spark-streaming-twitter_2.11" % "2.0.1"
)
但更好的做法是全局指定版本,然后使用%%(它会自动为您追加Scala版本):
但更好的做法是全局指定版本,然后使用%%(它会自动为您追加Scala版本):
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.0.1",
"org.apache.spark" %% "spark-streaming" % "2.0.1",
"org.apache.bahir" %% "spark-streaming-twitter" % "2.0.1"
)
<project>
<groupId>com.example</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<properties>
<spark.version>2.0.1</spark.version>
</properties>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>spark-streaming-twitter_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
</project>
Spark版本 所有包都必须使用相同的主要Spark版本(1.6、2.0、2.1等)。
考虑以下(不正确的)build.sbt:
name := "Simple Project"
version := "1.0"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "1.6.1",
"org.apache.spark" % "spark-streaming_2.10" % "2.0.1",
"org.apache.bahir" % "spark-streaming-twitter_2.11" % "2.0.1"
)
我们在使用Spark 2.0的其它组件时,仍然使用spark-core 1.6。一个有效的文件应该是:
name := "Simple Project"
version := "1.0"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "2.0.1",
"org.apache.spark" % "spark-streaming_2.10" % "2.0.1",
"org.apache.bahir" % "spark-streaming-twitter_2.11" % "2.0.1"
)
但更好的做法是使用变量(仍然不正确):
name := "Simple Project"
version := "1.0"
val sparkVersion = "2.0.1"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % sparkVersion,
"org.apache.spark" % "spark-streaming_2.10" % sparkVersion,
"org.apache.bahir" % "spark-streaming-twitter_2.11" % sparkVersion
)
<project>
<groupId>com.example</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<properties>
<spark.version>2.0.1</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>spark-streaming-twitter_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
</project>
Spark依赖中使用的Spark版本必须匹配Spark安装的版本。例如如果您在群集上使用1.6.1,则必须使用1.6.1构建jars。不总是接受小版本不匹配。
用于构建jar的Scala版本必须与部署的Spark使用的Scala版本相匹配。默认情况下(可下载的二进制文件和默认构建):
如果在fat jar中包括了附加包,则这些包应该在工作节点上可访问。有许多选项,包括:
--jars参数用于spark-submit - 分发本地jar文件。--packages参数用于spark-submit - 从Maven存储库获取依赖项。在集群节点中提交时,应将应用程序jar包含在--jars中。
您需要在启动命令的application-jar选项中指定应用程序的依赖类。
更多详情请参考Spark文档。
摘自文档:
application-jar:路径到一个打包的JAR文件,包括您的应用程序和所有依赖项。URL必须在您的集群内全局可见,例如,hdfs://路径或在所有节点上都存在的file://路径
将spark-2.4.0-bin-hadoop2.7\spark-2.4.0-bin-hadoop2.7\jars中的所有jar文件添加到项目中。可以从https://spark.apache.org/downloads.html下载spark-2.4.0-bin-hadoop2.7。
我认为这个问题必须通过一个汇编插件来解决。你需要构建一个fat jar。例如在sbt中:
$PROJECT_ROOT/project/assembly.sbt,其中包含代码addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.0")libraryDependencies ++= Seq("com.some.company" %% "some-lib" % "1.0.0")`如果您需要更多信息,请访问https://github.com/sbt/sbt-assembly
我有以下的 build.sbt 文件
lazy val root = (project in file(".")).
settings(
name := "spark-samples",
version := "1.0",
scalaVersion := "2.11.12",
mainClass in Compile := Some("StreamingExample")
)
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.4.0",
"org.apache.spark" %% "spark-streaming" % "2.4.0",
"org.apache.spark" %% "spark-sql" % "2.4.0",
"com.couchbase.client" %% "spark-connector" % "2.2.0"
)
// META-INF discarding
assemblyMergeStrategy in assembly := {
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case x => MergeStrategy.first
}
java.lang.NoClassDefFoundError: rx/Completable$OnSubscribe
at com.couchbase.spark.connection.CouchbaseConnection.streamClient(CouchbaseConnection.scala:154)
我可以看到这个类存在于我的fat jar中:
jar tf target/scala-2.11/spark-samples-assembly-1.0.jar | grep 'Completable$OnSubscribe'
rx/Completable$OnSubscribe.class
我不确定我在这里缺少了什么,有什么线索吗?
jar tf jar-file的输出,该命令会打印出jar文件中的类。 - Myles Baker