import pandas as pd
import numpy as np
import cv2
from torch.utils.data.dataset import Dataset
class CustomDatasetFromCSV(Dataset):
def __init__(self, csv_path, transform=None):
self.data = pd.read_csv(csv_path)
self.labels = pd.get_dummies(self.data['emotion']).as_matrix()
self.height = 48
self.width = 48
self.transform = transform
def __getitem__(self, index):
pixels = self.data['pixels'].tolist()
faces = []
for pixel_sequence in pixels:
face = [int(pixel) for pixel in pixel_sequence.split(' ')]
# print(np.asarray(face).shape)
face = np.asarray(face).reshape(self.width, self.height)
face = cv2.resize(face.astype('uint8'), (self.width, self.height))
faces.append(face.astype('float32'))
faces = np.asarray(faces)
faces = np.expand_dims(faces, -1)
return faces, self.labels
def __len__(self):
return len(self.data)
这是我通过使用其他存储库的参考所能完成的。然而,我想将此数据集拆分为训练集和测试集。
我应该如何在这个类中实现它?还是说我需要创建一个单独的类来完成这项工作?
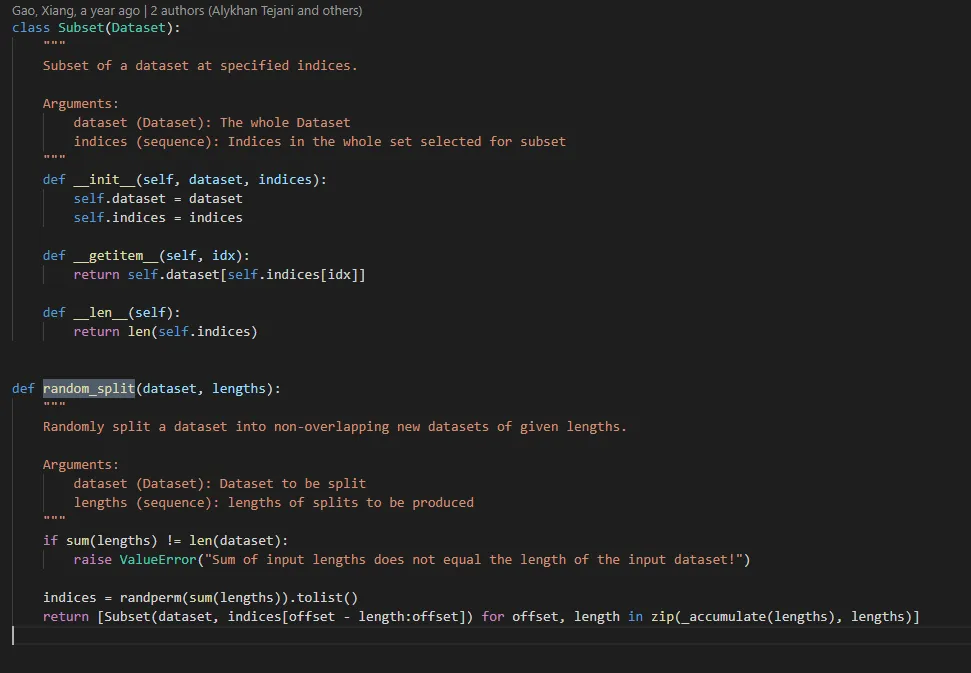
train_loader时出现了这个问题:https://dev59.com/3LDma4cB1Zd3GeqPALOS - joeAttributeError: 'Subset' object has no attribute 'targets'how can I access targets of only one of the subsets? I want to print something like this for train and test data separately{0: 111, 1: 722, 2: 813, 3: 175, 4: 283, 5: 2846, 6: 290, 7: 106}- Amin BashiriTypeError 'DataLoader' object is not subscriptable的错误,你可能也想看一下 https://dev59.com/3rnoa4cB1Zd3GeqPLSlT#60150673 - trujello