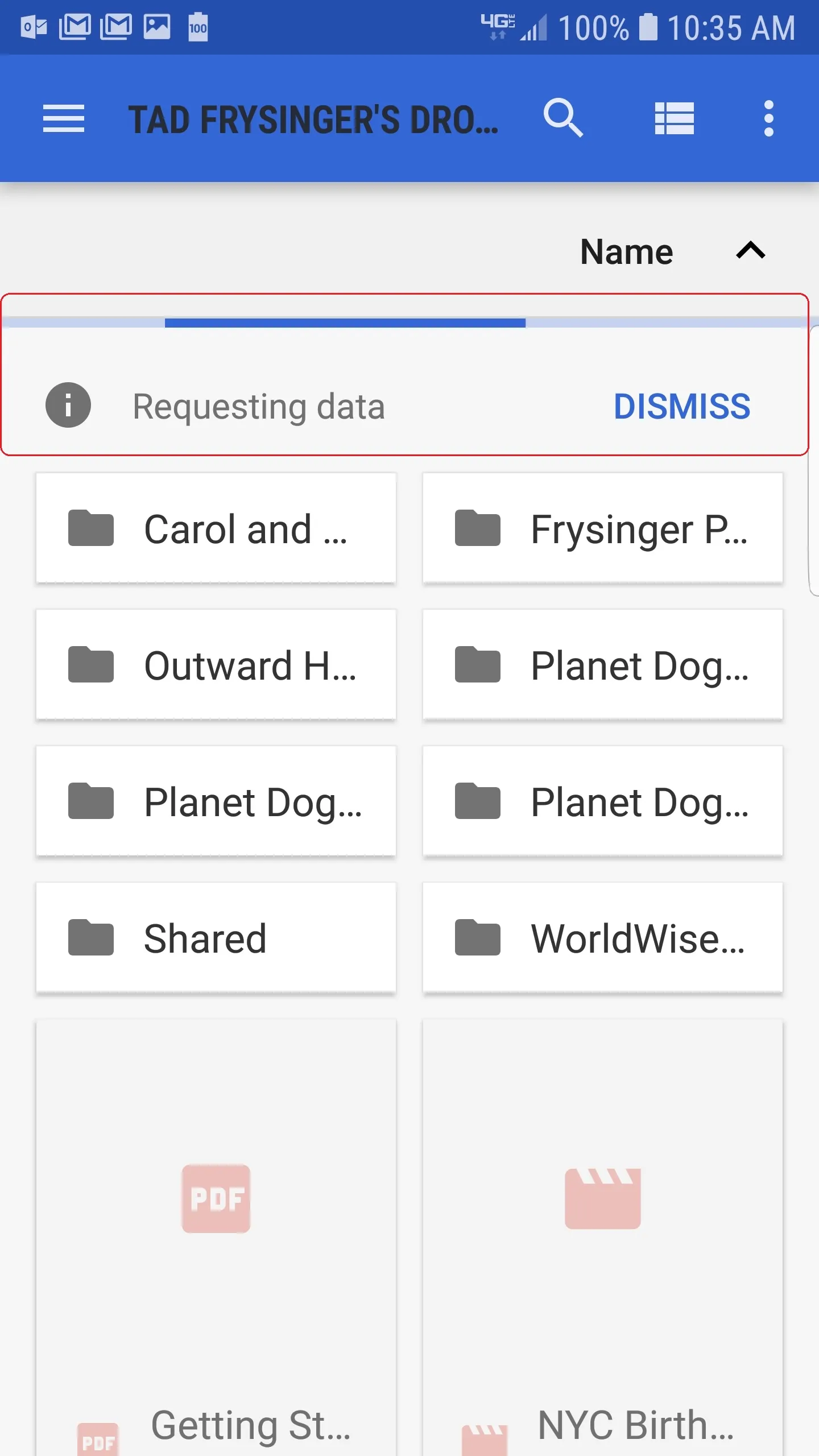
我查阅了com.android.documentsui中的代码以及其他AOSP领域,针对此问题作出以下回答:
1.当Picker中某个目录的内容被显示时,是通过DirectoryFragment实例完成的。
2.DirectoryFragment最终管理DirectoryLoader的一个实例。
3.DirectoryLoader异步调用DocumentsProvider来填充游标(它被封装在DirectoryResult实例中,并由Model实例处理),然后将其传递给DirectoryFragment中RecyclerView的基础数据存储。重要的是,“当它完成时,加载器会保留对该游标的引用”-当我们需要通知加载器进行另一个加载时,这将发挥作用。
4.Model接收DirectoryResult,使用包含的Cursor填充其数据结构,并通过查询Cursor.getExtras()中的EXTRA_LOADING键更新“isLoading”的状态。然后,它还会通知由DirectoryFragment管理的另一个监听器,表明数据已更新。
5.DirectoryFragment通过此监听器检查Model是否指示EXTRA_LOADING设置为TRUE,如果是,则显示进度条,否则删除它。然后,它在与RecyclerView关联的适配器上执行notifyDataSetChanged()。
我们解决方案的关键是,在模型使用加载器返回结果之后才显示或删除进度条。
此外,当Model实例请求更新自身时,它会完全清除先前的数据,并迭代当前游标以再次填充自身。这意味着我们的“第二次获取”应在检索到所有数据后完成,并且需要包括完整的数据集,而不仅仅是“第二次获取”。
最后 - DirectoryLoader基本上在从queryChildDocuments()中返回游标之后,才将一个内部类注册为Cursor的ContentObserver。
因此,我们的解决方案如下:
在DocumentsProvider.queryChildDocuments()中,确定是否可以在一次遍历中满足完整结果集。
如果可以,则只需加载并返回游标即可完成。
如果不能,则:
1.确保初始加载的游标的getExtras()将为EXTRA_LOADING键返回TRUE。
2.收集初始批量数据,并使用内部缓存将其加载到游标中(有关原因请参见下文)。在下一步之后,我们将返回此游标,并且由于EXTRA_LOADING为true,进度条将显示。
3.现在来到棘手的部分。queryChildDocuments()的JavaDoc说:
如果您的提供者是基于云的,并且您在本地缓存或固定了一些数据,则可以立即返回本地数据,并将 DocumentsContract.EXTRA_LOADING 设置在游标上,以表明您仍在获取其他数据。然后,当有网络数据可用时,您可以发送更改通知以触发重新查询并返回完整内容。
问题在于,这个通知从哪里来?此时我们深入到我们的提供者代码中,使用初始加载请求填充游标。提供程序对加载器一无所知——它只是响应 queryChildDocuments() 的调用。而此时,加载器对游标一无所知——它只是执行一个查询() 进入系统,最终调用我们的提供程序。一旦我们将游标返回到加载器,除非有某种外部事件(例如用户单击文件或目录),否则不会再次调用提供程序。从 DirectoryLoader:
if (mFeatures.isContentPagingEnabled()) {
Bundle queryArgs = new Bundle();
mModel.addQuerySortArgs(queryArgs);
DebugFlags.addForcedPagingArgs(queryArgs);
cursor = client.query(mUri, null, queryArgs, mSignal);
} else {
cursor = client.query(
mUri, null, null, null, mModel.getDocumentSortQuery(), mSignal);
}
if (cursor == null) {
throw new RemoteException("Provider returned null");
}
cursor.registerContentObserver(mObserver);
client.query() 方法是在一个最终调用我们提供者的类上执行的。请注意,在返回游标后,Loader 会使用 'mObserver' 将自身作为 ContentObserver 注册到游标上。mObserver 是 Loader 内部类的一个实例,当收到内容更改通知时,它会导致 Loader 再次查询。
因此,我们需要采取两个步骤。首先,由于 Loader 不会销毁从初始 query() 中接收到的游标,在调用 queryChildDocuments() 时,提供者需要使用 Cursor.setNotificationUri() 方法将游标注册到 ContentResolver 中,并传递表示当前子目录(传入 queryChildDocuments() 的 parentDocumentId)的 Uri:
cursor.setNotificationUri(getContext().getContentResolver(),
DocumentsContract.buildChildDocumentsUri(, parentDocumentId));
然后,为了重新启动 Loader 并收集其余数据,需要生成一个单独的线程来执行循环:a)获取数据,b)将其连接到用于填充第一次查询中的游标的缓存结果中(这就是为什么我在步骤 2 中说要保存它),以及 c)通知游标数据已更改。
从初始查询中返回游标。由于 EXTRA_LOADING 设置为 true,进度条将出现。
由于 Loader 注册了自身以在内容更改时收到通知,因此当通过步骤 7 在提供者中生成的线程完成获取时,它需要使用与在步骤(6)中注册在游标上的相同 Uri 值调用 Resolver 上的 notifyChange():
getContext().getContentResolver().notifyChange(DocumentsContract.buildChildDocumentsUri(, parentDocumentId), null);
游标从 Resolver 收到通知,并通知 Loader,导致它重新查询。这次当 Loader 查询我的提供者时,提供者会注意到它是重新查询,并使用当前缓存集填充游标。它还必须注意在获取缓存的当前快照时线程是否仍在运行 - 如果是,则将 getExtras() 设置为指示仍在进行加载。如果不是,则将 getExtras() 设置为指示未进行加载,以便移除进度条。
在线程获取数据后,数据集将加载到 Model 中,并且 RecyclerView 将刷新。当线程在其最后一批获取后死亡时,进度条将被移除。
我学习过程中获得的一些重要提示:
- 在调用 queryChildDocuments() 时,提供者必须决定是否可以在一个获取中获取所有条目,并相应地调整 Cursor.getExtras() 的结果。文档建议采用以下方法:
MatrixCursor result = new MatrixCursor(projection != null ?
projection : DEFAULT_DOCUMENT_PROJECTION) {
@Override
public Bundle getExtras() {
Bundle bundle = new Bundle();
bundle.putBoolean(DocumentsContract.EXTRA_LOADING, true);
return bundle;
}
};
如果您在创建Cursor时知道是否一次性获取所有内容,那么这样做就没问题。
如果您需要先创建Cursor、填充数据,然后进行调整,则需要采用不同的模式,例如:
private final Bundle b = new Bundle()
MatrixCursor result = new MatrixCursor(projection != null ?
projection : DEFAULT_DOCUMENT_PROJECTION) {
@Override
public Bundle getExtras() {
return b;
}
};
然后你可以这样做:
result.getExtras().putBoolean(DocumentsContract.EXTRA_LOADING, true);
如果您需要修改从getExtras()返回的Bundle,就像上面的例子一样,您必须编写getExtras()以使其返回可以像上面的例子中那样更新的内容。否则,您无法修改默认情况下从getExtras()返回的Bundle实例。这是因为默认情况下,getExtras()将返回一个Bundle.EMPTY实例,它本身由ArrayMap.EMPTY支持,而ArrayMap类定义了一种使ArrayMap不可变的方式,因此,如果尝试更改它,则会出现运行时异常。
我知道在启动填充其余内容的线程和将初始游标返回给加载器之间有非常短的时间窗口。从理论上讲,线程可能在加载器注册自身到游标之前完成。如果发生这种情况,即使线程通知解析器发生了更改,由于游标尚未被注册为侦听器,它也不会收到消息,加载器也不会重新启动。我希望能找到一种方法确保这种情况不会发生,但我还没有研究过除了延迟线程250毫秒之类的东西之外的其他方法。
另一个问题是在获取进度仍在进行时用户导航离开当前目录的情况。可以通过提供程序每次跟踪传递给queryChildDocuments()的parentDocumentId来检查。当它们相同时,它是重新查询。当不同时,它是新查询。在新查询中,如果线程处于活动状态,则取消线程并清除缓存,然后处理查询。
另一个要处理的问题是可能有多个源重新查询同一目录的情况。第一个是当线程在获取目录条目后通过Uri通知触发它时。其他的是当请求加载器进行刷新时,可以通过几种方式实现(例如,用户向下滑动屏幕)。要检查的关键是如果为相同的目录调用了queryChildDocuments()且线程尚未完成,则我们已经收到了从某种刷新请求重新加载的请求-我们通过从缓存的当前状态对游标执行同步加载来尊重这一点,但预计当线程完成时我们将再次被调用。
在我的测试中,从未出现过同时调用同一提供程序的情况-随着用户浏览目录,一次只会请求一个目录。因此,我们可以使用单个线程满足我们的“批量获取”,并且当检测到请求新目录时(例如,用户移动离需要长时间加载的目录),我们可以取消线程并根据需要在新目录上启动一个新实例。
我发布了代码的相关部分以展示我是如何做到的,以下是一些注意事项:
- 我的应用程序支持多种提供程序类型,因此我创建了一个抽象类“AbstractStorageProvider”,它扩展了DocumentsProvider,以封装提供程序从系统中获取的常见调用(例如queryRoots、queryChildDocuments等)。这些再委托给每个服务的类来支持(本地存储、Dropbox、Spotify、Instagram等),以填充游标。我还在这里放置了一个标准方法来检查并确保用户没有在应用程序外更改了Android权限设置,否则会引发异常。
- 同步访问内部缓存非常重要,因为线程将在后台工作,同时不断请求更多数据。
- 我发布了一个相对简洁的版本的代码,以便更清晰易懂。在生产代码中需要多个处理程序来处理网络故障、配置更改等。
我的抽象提供程序类中的queryChildDocuments()方法调用一个createDocumentMatrixCursor()方法,该方法可以根据提供程序子类的不同实现而有所不同:
@Override
public Cursor queryChildDocuments(final String parentDocumentId,
final String[] projection,
final String sortOrder) {
if (selfPermissionsFailed(getContext())) {
return null;
}
Log.d(TAG, "queryChildDocuments called for: " + parentDocumentId + ", calling createDocumentMatrixCursor");
final MatrixCursor cursor = createDocumentMatrixCursor(projection != null ? projection : getDefaultDocumentProjection(), parentDocumentId);
addRowsToQueryChildDocumentsCursor(cursor, parentDocumentId, projection, sortOrder);
return cursor;
}
接下来是我的DropboxProvider实现中的createDocumentMatrixCursor方法:
@Override
protected MatrixCursor createDocumentMatrixCursor(String[] projection, final String parentDocumentId) {
MatrixCursor cursor = null;
final Bundle b = new Bundle();
cursor = new MatrixCursor(projection != null ? projection : getDefaultDocumentProjection()){
@Override
public Bundle getExtras() {
return b;
}
};
Log.d(TAG, "Creating Document MatrixCursor" );
if ( !(parentDocumentId.equals(oldParentDocumentId)) ) {
Log.d(TAG, "New query detected for sub-directory with Id: " + parentDocumentId + " old Id was: " + oldParentDocumentId );
oldParentDocumentId = parentDocumentId;
cancelBatchFetcher();
metadataCache.clear();
} else {
Log.d(TAG, "Requery detected for sub-directory with Id: " + parentDocumentId );
}
return cursor;
}
addrowsToQueryChildDocumentsCursor()方法是我抽象提供程序类在调用其queryChildDocuments()方法时调用的方法,也是子类实现并批量获取大型目录内容的地方。例如,我的Dropbox提供程序子类利用Dropbox API获取所需数据,代码如下:
protected void addRowsToQueryChildDocumentsCursor(MatrixCursor cursor,
final String parentDocumentId,
String[] projection,
String sortOrder) {
Log.d(TAG, "addRowstoQueryChildDocumentsCursor called for: " + parentDocumentId);
try {
if ( DropboxClientFactory.needsInit()) {
Log.d(TAG, "In addRowsToQueryChildDocumentsCursor, initializing DropboxClientFactory");
DropboxClientFactory.init(accessToken);
}
final ListFolderResult dropBoxQueryResult;
DbxClientV2 mDbxClient = DropboxClientFactory.getClient();
if ( isReQuery() ) {
boolean fetcherIsLoading = false;
synchronized(this) {
populateResultsToCursor(metadataCache, cursor);
fetcherIsLoading = fetcherIsLoading();
}
if (!fetcherIsLoading) {
Log.d(TAG, "I believe batchFetcher is no longer loading any data, so clearing the cache");
metadataCache.clear();
clearCursorLoadingNotification(cursor);
} else {
Log.d(TAG, "I believe batchFetcher is still loading data, so leaving the cache alone.");
setCursorForLoadingNotification(cursor, parentDocumentId);
}
} else {
if (parentDocumentId.equals(accessToken)) {
dropBoxQueryResult = mDbxClient.files().listFolderBuilder("").withLimit(batchSize).start();
} else {
dropBoxQueryResult = mDbxClient.files().listFolderBuilder(parentDocumentId).withLimit(batchSize).start();
}
Log.d(TAG, "New query fetch got " + dropBoxQueryResult.getEntries().size() + " entries.");
if (dropBoxQueryResult.getEntries().size() == 0) {
Log.d(TAG, "I called mDbxClient.files().listFolder() but nothing was there!");
return;
}
if (!dropBoxQueryResult.getHasMore()) {
populateResultsToCursor(dropBoxQueryResult.getEntries(), cursor);
Log.d(TAG, "First fetch got all entries so I'm clearing the cache");
metadataCache.clear();
clearCursorLoadingNotification(cursor);
Log.d(TAG, "Directory retrieval is complete for parentDocumentId: " + parentDocumentId);
} else {
Log.d(TAG, "Fetched a batch and need to load more for parentDocumentId: " + parentDocumentId);
populateResultsToCacheAndCursor(dropBoxQueryResult.getEntries(), cursor);
setCursorForLoadingNotification(cursor, parentDocumentId);
Log.d(TAG, "registering cursor for notificationUri on: " + getChildDocumentsUri(parentDocumentId).toString() + " and starting BatchFetcher");
cursor.setNotificationUri(getContext().getContentResolver(),getChildDocumentsUri(parentDocumentId));
batchFetcher = new BatchFetcher(parentDocumentId, dropBoxQueryResult);
batchFetcher.start();
}
}
} catch (Exception e) {
Log.d(TAG, "In addRowsToQueryChildDocumentsCursor got exception, message was: " + e.getMessage());
}
线程(“BatchFetcher”)处理缓存填充,并在每次获取后通知解析器:
private class BatchFetcher extends Thread {
String mParentDocumentId;
ListFolderResult mListFolderResult;
boolean keepFetchin = true;
BatchFetcher(String parentDocumentId, ListFolderResult listFolderResult) {
mParentDocumentId = parentDocumentId;
mListFolderResult = listFolderResult;
}
@Override
public void interrupt() {
keepFetchin = false;
super.interrupt();
}
public void run() {
Log.d(TAG, "Starting run() method of BatchFetcher");
DbxClientV2 mDbxClient = DropboxClientFactory.getClient();
try {
mListFolderResult = mDbxClient.files().listFolderContinue(mListFolderResult.getCursor());
if ( mListFolderResult.getEntries().size() == 0) {
getContext().getContentResolver().notifyChange(getChildDocumentsUri(mParentDocumentId), null);
return;
}
while (keepFetchin) {
populateResultsToCache(mListFolderResult.getEntries());
if (!mListFolderResult.getHasMore()) {
keepFetchin = false;
} else {
mListFolderResult = mDbxClient.files().listFolderContinue(mListFolderResult.getCursor());
if ( mListFolderResult.getEntries().size() == 0) {
getContext().getContentResolver().notifyChange(getChildDocumentsUri(mParentDocumentId), null);
return;
}
}
Log.d(TAG, "BatchFetcher calling contentResolver to notify a change using notificationUri of: " + getChildDocumentsUri(mParentDocumentId).toString());
getContext().getContentResolver().notifyChange(getChildDocumentsUri(mParentDocumentId), null);
}
Log.d(TAG, "Ending run() method of BatchFetcher");
} catch (DbxException e) {
Log.d(TAG, "In BatchFetcher for parentDocumentId: " + mParentDocumentId + " got error, message was; " + e.getMessage());
}
}
}