性能分析
解决方案
哪个解决方案最快?有两个明显的答案(以及3个解决方案)获得了大部分票数。
- Patrick Artner的解决方案 - 简称PA。
- jpp的第一个解决方案 - 简称jpp1。
- jpp的第二个解决方案 - 简称jpp2。
这是因为它们声称在O(N)中运行,而其他一些解决方案在O(N^2)中运行,或者不能保证返回列表的顺序。
实验设置
对于这个实验,考虑了3个变量。
- N个元素。函数要搜索的前N个元素的数量。
- 列表长度。列表越长,算法查找最后一个元素的距离就越远。
- 重复限制。一个元素在下一个元素出现之前可以重复多少次。这是在1和重复限制之间均匀分布的。
数据生成的假设如下。这些假设对使用的算法有多严格取决于算法本身,但更多地是关于数据如何生成而不是算法本身的限制。
- 元素在其重复序列首次出现在列表中后不会再次出现。
- 元素是数字且递增的。
- 元素属于int类型。
因此,在列表[1,1,1,2,2,3,4 ....]中,1、2、3永远不会再次出现。 4之后的下一个元素将是5,但在我们看到5之前,可能会有随机数量的4,最多达到重复限制。
为每个变量组合创建了一个新的数据集,并重新生成了20次。使用Python的
timeit函数在每个数据集上对算法进行50次剖析。每种组合的20x50=1000次运行的平均时间在此处报告。由于算法是生成器,因此将它们的输出转换为列表以获取执行时间。
结果
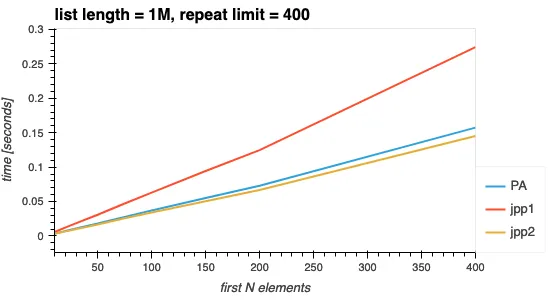
正如预期的那样,搜索的元素越多,所需时间就越长。该图表显示执行时间确实是作者所声称的O(N)(直线证明了这一点)。
英文原文已经是中文了,以下是翻译:
图1. 改变搜索的前N个元素。
所有三种解决方案都不会消耗额外的计算时间。下面的图像显示当列表大小受限,而不是N个元素时会发生什么。长度为10k的列表,元素最多重复100次(因此平均重复50次),平均情况下会在200个元素(10000/50)左右用完所有独特的元素。如果这些图表中任何一个显示出超过200的计算时间增加,这将是一个值得关注的问题。
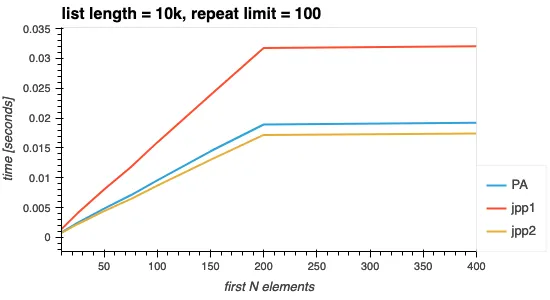
图2. 选择的前N个元素 > 独特元素数量的影响。
下面的图表再次显示,随着算法需要筛选的数据越多,处理时间会增加(以O(N)的速率)。增长率与变化前N个元素时相同。这是因为在两种情况下,遍历列表是常见的执行块,并且最终决定算法速度的执行块。
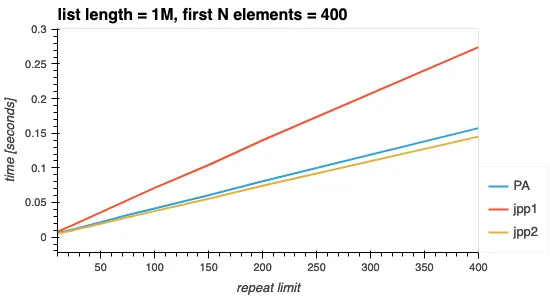
图3. 重复限制的变化。
结论:
在所有情况下,
jpp发布的第二个解决方案是最快的解决方案。该解决方案仅比
Patrick Artner发布的解决方案稍快,并且几乎比
他的第一个解决方案快了一倍。
set(a)[:n]翻译:此代码意图为从列表a中创建一个集合(set),然后选择前n个元素,最终返回这些元素所构成的新的集合。 - Tony Pellerinelement not in itr[:index]不够高效,应该使用集合(set)。 - juanpa.arrivillaga