使用 document.querySelector 的主要优点是可以更轻松地处理复杂的 CSS 查询。
const loginFields = document.querySelector("form.login input");
if (loginFields.some((field) => field.value.trim() === "") {
alert("Please fill in all fields");
}
另一种选择是使用 document.getElementsByClassName 和 Element.getElementsByTagName。
const loginFields = document.getElementsByClassName(".login")[0]
.getElementsByTagName("input");
if (loginFields.some((field) => field.value.trim() === "") {
alert("Please fill in all fields");
}
如您所见,通常会将返回结果存储在常量/变量中。您不应该在for/while循环中调用此函数。
关于(已归档)性能测试,它看起来有些不公平,因为除了类测试之外的所有测试都会运行两个查询。
所以我决定进行更多测试。在那个页面的HTML中,我将"id codeOne"添加到第一个具有"class code"的元素中。
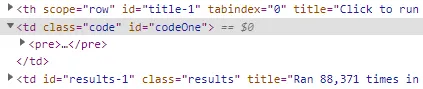
然后我运行了四个测试。
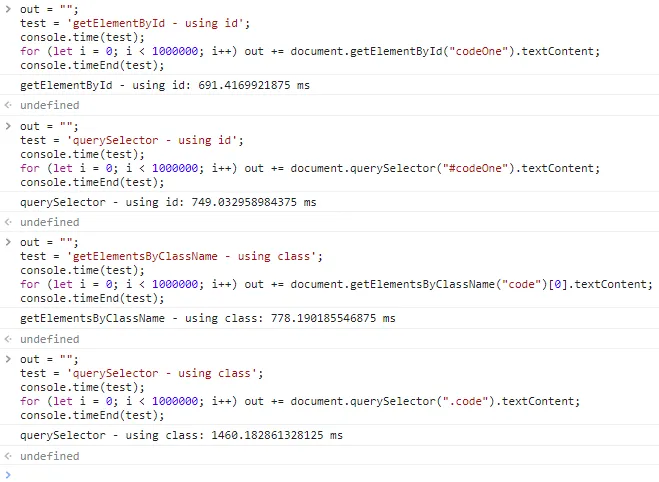
从这些测试结果中,我可以得出结论,使用id的getElementById(691毫秒)是明显的赢家,querySelector使用id(749毫秒)排名第二。这是因为ids很容易查找,因为浏览器从最主流的浏览器Internet Explorer中复制了这个特性。您甚至可以像使用变量一样使用id。
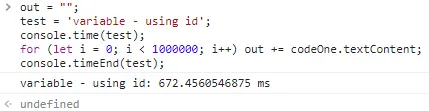
请不要这样做,因为它不够易读。而且这样做也不会更快。
当我们看一下使用类的测试时,我们可以看到getElementByClassName(778毫秒)和querySelector(1460毫秒)之间存在巨大的性能差异。这是因为前者只会查找className,而后者会进行一些额外的检查,因为它可以使用复杂的查询,例如'#id.class[attr="value"]'或"form > input"。
最终的结论是,您可以仅为简单起见使用document.querySelector来获取一个元素,使用document.querySelectorAll来获取多个元素,因为任何CSS查询都可以工作。getElementById和getElementsByClassName函数(以及未包含的getElementsByTagName)理论上应该始终更快,但在实践中,这不应影响您网站的性能。您(可能)不会在循环中调用这些函数,因此可以将结果存储在变量中。
getElementById更快?可能是你做错了什么。getElementById只是一次表格查询,是无可争议的赢家。但是,你为什么要费心呢?你真的有 DOM 选择方面的瓶颈吗? - KaiidogetElementsByClassName返回一个实时的节点列表,而querySelector(All)和getElementById不会。 - AndygetElementsByClassName时,它将返回相同的Javascript对象(集合)。我不知道 jsperf 测试是否考虑了这一点。 - CertainPerformancequerySelector更受欢迎,因为它更简单,并且不返回实时集合。 - BergigetElementById更快(但只在性能测试中才能注意到),因为自从早期的Internet Explorer时代,浏览器为所有ID值创建全局变量。正如Kaiido在第一条评论中所说,“getElementById”只是一个表查找。许多月亮前,所有浏览器供应商都复制了这种行为,因为微软拥有90%的浏览器市场份额,并且所有浏览器都必须支持基于此(Microsoft)ID行为编写的Web应用程序。今天,除了FireFox之外,所有浏览器仍然为重复的ID创建完全有效的“IDname”全局数组。 - Danny '365CSI' Engelman