我觉得在tidyverse中可能有比使用for-loop更好的方法。从一个标准的tibble/dataframe开始,创建一个列表,其中列表元素的名称是一列(group_by?)的唯一值,而列表元素则是另一列的所有值。
my_data <- tibble(list_names = c("Ford", "Chevy", "Ford", "Dodge", "Dodge", "Ford"),
list_values = c("Ranger", "Equinox", "F150", "Caravan", "Ram", "Explorer"))
# A tibble: 6 × 2
list_names list_values
<chr> <chr>
1 Ford Ranger
2 Chevy Equinox
3 Ford F150
4 Dodge Caravan
5 Dodge Ram
6 Ford Explorer
这是期望输出:
desired_output <- list(Ford = c("Ranger", "F150", "Explorer"),
Chevy = c("Equinox"),
Dodge = c("Caravan", "Ram"))
$Ford
[1] "Ranger" "F150" "Explorer"
$Chevy
[1] "Equinox"
$Dodge
[1] "Caravan" "Ram"
这可以通过 for-loop 实现,但我敢打赌有一个 tidyverse 函数可以使它更简单/更快,等等。
desired_output <- list()
for(i in seq_along(my_data$list_names)) {
entry <- my_data %>%
filter(list_names == my_data$list_names[i]) %>%
pull(list_values)
desired_output[[my_data$list_names[i]]] <- entry
}
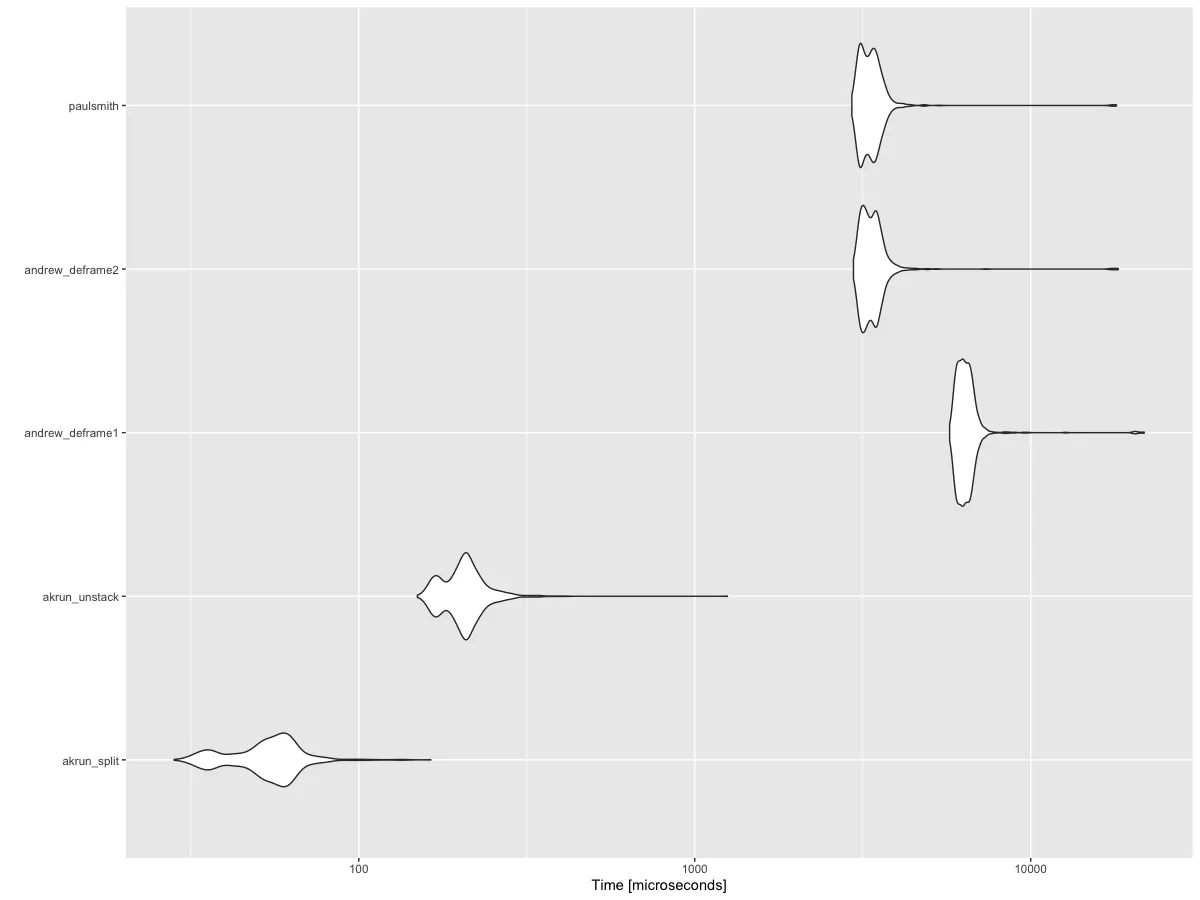
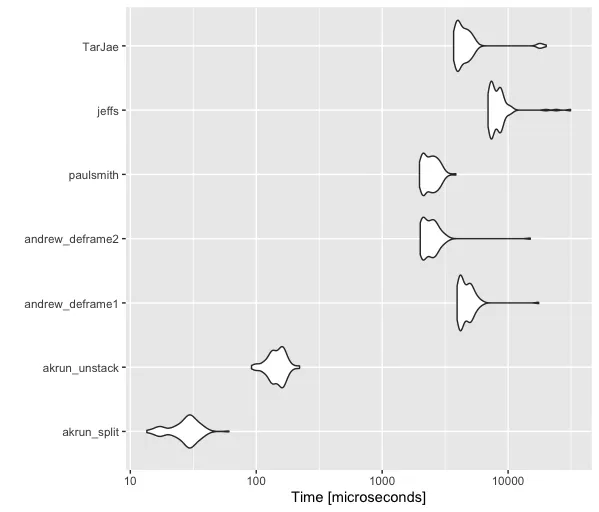
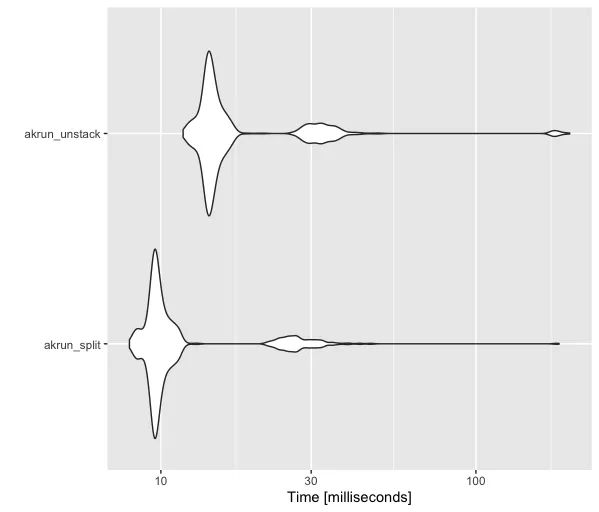
lets列添加为第三列。然后,my_data$lets <- head(letters); my_data %>% summarise(named_vec = list(setNames(list_values, lets)), .by = list_names) %>% deframe- undefined