我有一份类似于以下的数据框:
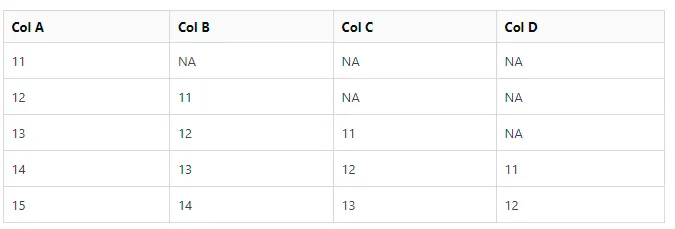
现在,我想把列B的缺失值NA替换为15。列C中第一个NA替换为14,第二个NA替换为15。列D中第一个NA替换为13,第二个NA替换为14,第三个NA替换为15。因此,数字从上到下或从下到上依次递增。
可重复示例数据
structure(list(`Col A` = c(11, 12, 13, 14, 15), `Col B` = c(NA,
11, 12, 13, 14), `Col C` = c(NA, NA, 11, 12, 13), `Col D` = c(NA,
NA, NA, 11, 12)), row.names = c(NA, -5L), class = c("tbl_df",
"tbl", "data.frame"))