我正在寻找在不运行完整查询的情况下检索记录的下一个和上一个记录的最佳方法。我已经有了完全实现的解决方案,并想知道是否有更好的方法来完成这个任务。
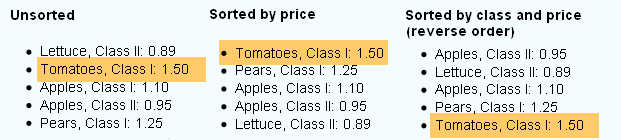
假设我们正在为一个虚构的果蔬商店建立网站。除了HTML页面外,他每周还想在网站上发布特价商品列表。他希望这些报价位于实际的数据库表中,并且用户必须能够以三种方式对报价进行排序。
每个项目还必须有一个详细页面,其中包含有关该优惠更多的文字信息以及“上一个”和“下一个”按钮。根据用户选择的列表排序,“上一个”和“下一个”按钮需要指向相邻的条目。
(source: pekkagaiser.com)
显然,“西红柿,一级”的“下一个”按钮在第一个例子中应该是“苹果,一级”,在第二个例子中应该是“梨,一级”,而在第三个例子中则没有。
在详细视图中的任务是确定下一个和上一个项目,而无需每次运行查询,并且仅有列表的排序顺序可用(假设我们通过GET参数?sort=offeroftheweek_price获得该信息,并忽略安全性问题)。
显然,简单地将下一个和上一个元素的ID作为参数传递是首先想到的解决方案。毕竟,我们已经在这一点上知道了ID。但是,在这里这不是一个选择-它在这个简化的示例中可以工作,但在我的许多真实用例中则无法工作。
我在我的CMS中采用的当前方法是使用我命名为“排序缓存”的东西。当加载列表时,我将项目位置存储在名为“sortingcache”的表中的记录中。
name (VARCHAR) items (TEXT)
offeroftheweek_unsorted Lettuce; Tomatoes; Apples I; Apples II; Pears
offeroftheweek_price Tomatoes;Pears;Apples I; Apples II; Lettuce
offeroftheweek_class_asc Apples II;Lettuce;Apples;Pears;Tomatoes
显然,items列中实际存储的是数字ID。
在详情页中,我现在访问相应的sortingcache记录,获取items列,对其进行拆分,搜索当前项目ID并返回前一个和下一个邻居。
array("current" => "Tomatoes",
"next" => "Pears",
"previous" => null
);
显然,这是一种昂贵的方法,仅适用于有限数量的记录,且会创建冗余数据。但是在现实世界中,创建列表的查询非常耗费时间(确实如此)。在每个详细视图中运行它是不可行的,因此需要进行缓存。
我的问题:
您认为查找变化查询顺序的相邻记录是否是一种好的做法?
您知道在性能和简单性方面是否有更好的做法吗?您知道什么可以使此方法完全过时吗?
在编程理论中,有没有称之为这个问题的名字?
“排序缓存”这个名称是否适合并且易于理解这种技术?
有没有公认的、常见的模式来解决这个问题?他们被称为什么?
注意:我的问题不是关于构建列表或如何显示详细视图的。那些只是例子。我的问题是在无法重新查询时确定记录的相邻项的基本功能,以及最快、最便宜的方法。
如果有什么不清楚的地方,请留言,我会进行澄清。
发起一个悬赏 - 可能还有更多关于这个问题的信息。
{kind=link}