我一直在尝试进行实验,以查看函数中的局部变量是否存储在堆栈上。
因此,我编写了一个小型性能测试。
在进行替代顺序测试时,行为相同。
因此,我编写了一个小型性能测试。
function test(fn, times){
var i = times;
var t = Date.now()
while(i--){
fn()
}
return Date.now() - t;
}
ene
function straight(){
var a = 1
var b = 2
var c = 3
var d = 4
var e = 5
a = a * 5
b = Math.pow(b, 10)
c = Math.pow(c, 11)
d = Math.pow(d, 12)
e = Math.pow(e, 25)
}
function inversed(){
var a = 1
var b = 2
var c = 3
var d = 4
var e = 5
e = Math.pow(e, 25)
d = Math.pow(d, 12)
c = Math.pow(c, 11)
b = Math.pow(b, 10)
a = a * 5
}
我本以为反函数的运行速度会更快,但实际上得到了惊人的结果。
直到我测试其中一个函数时,它的运行速度比测试第二个函数时快10倍。
例子:
> test(straight, 10000000)
30
> test(straight, 10000000)
32
> test(inversed, 10000000)
390
> test(straight, 10000000)
392
> test(inversed, 10000000)
390
在进行替代顺序测试时,行为相同。
> test(inversed, 10000000)
25
> test(straight, 10000000)
392
> test(inversed, 10000000)
394
我在Chrome浏览器和Node.js中进行了测试,但我完全不知道为什么会出现这种情况。该效果持续到我刷新当前页面或重新启动Node REPL。
有什么可能导致性能显着下降(约为12倍)?
PS. 由于它似乎只在某些环境中工作,请写下您用于测试的环境。
我的环境是:
操作系统:Ubuntu 14.04
Node v0.10.37
Chrome 43.0.2357.134(正式版本)(64位)
/编辑
在Firefox 39上,每个测试需要大约5500毫秒,无论顺序如何。它似乎只会发生在特定的引擎上。
/编辑2
将函数内联到测试函数中使其始终以相同的时间运行。
如果参数函数始终相同,是否有可能进行内联优化?
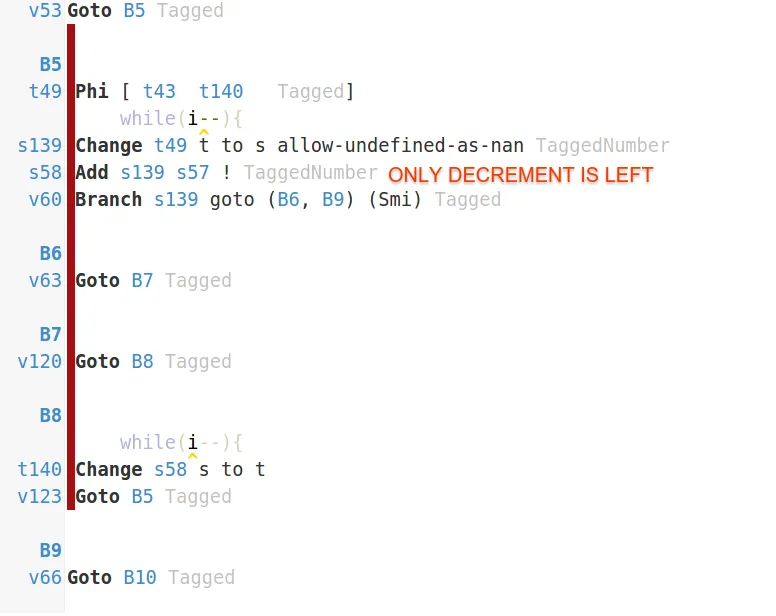
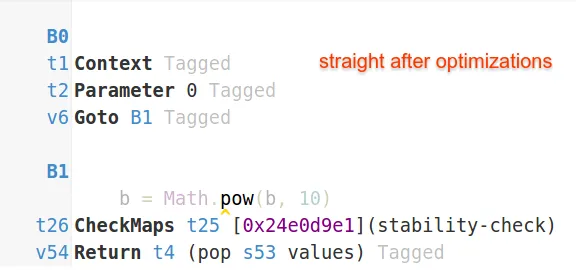
fn会被内联优化,直到它能够承载超过一个值的那一刻。 - 1983