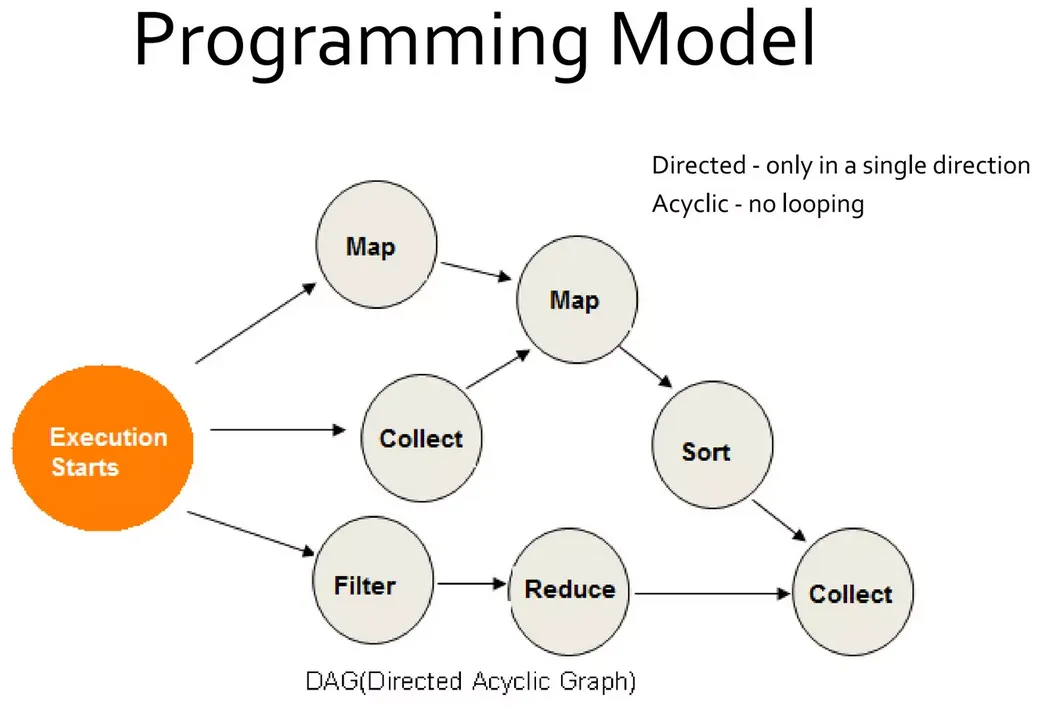
Spark Transformations是惰性评估的 - 当我们调用操作时,它会根据血统图执行所有转换。
什么是惰性评估的优点?
与急切评估相比,它是否会提高性能并减少内存消耗的数量?
惰性评估转换有什么缺点吗?
Spark Transformations是惰性评估的 - 当我们调用操作时,它会根据血统图执行所有转换。
什么是惰性评估的优点?
与急切评估相比,它是否会提高性能并减少内存消耗的数量?
惰性评估转换有什么缺点吗?
对于转换,Spark将其添加到计算DAG中,只有当驱动程序请求一些数据时,该DAG才会实际执行。
这种方法的一个优点是,Spark可以在完整查看DAG后做出许多优化决策。如果它在收到一切就立即执行所有操作,这是不可能的。
例如 - 如果您急切地执行每个转换,那意味着什么?嗯,这意味着您必须在内存中材料化许多中间数据集。这显然是不高效的 - 首先,它会增加GC成本。(因为您实际上并不关心那些中间结果。那些只是您编写程序时方便的抽象。) 所以,您需要告诉Spark您感兴趣的最终答案,并找出到达那里的最佳方式。
来自 https://www.mapr.com/blog/5-minute-guide-understanding-significance-apache-spark
惰性评估意味着如果您告诉Spark操作一组数据,它会听取您要求它执行的操作,为此写下一些简写以便不会忘记,然后什么都不做。它将继续什么都不做,直到您要求它给出最终答案为止。[...]
它会等待您完成所有操作符的输入,只有在您请求最终答案时才进行评估,并且它总是尽量减少其需要完成的工作量。
这可以节省时间和不必要的处理能力。
考虑Spark不是惰性的情况...
例如:我们从HDFS加载了1GB文件到内存中,然后进行转换。
rdd1 = load file from HDFS
rdd1.println(line1)
rdd1 = load file from HDFS
rdd1.println(line1)
优点:
描述:
(根据“ Apache Spark 上的大数据分析”[SA16] 和 [Khan15])
reduce(func), collect(), count(), first(), take(n), ... [APACHE]
map(func), filter(func), filterMap(func), groupByKey([numPartitions]), reduceByKey(func, [numPartitions]), ... [APACHE]