看似不起眼,但却不容易。我为每个字符生成了32x32的png图片,并添加了白噪声。视频的背景是移动的,并且像8和6这样的字符并没有太大的区别。
这是我目前的代码:
cap = cv2.VideoCapture("rtsp:...")
time.sleep(2)
templates = {}
w=[]
h=[]
for i in range(0,11):
templates["template_"+str(i)]=cv2.imread(str(i)+'.bmp',0)
tmp_w,tmp_h=templates["template_"+str(i)].shape[::-1]
w.append(tmp_w)
h.append(tmp_h)
threshold = 0.70
while(True):
les_points=[[],[],[],[],[],[],[],[],[],[],[]]
ret, frame = cap.read()
if frame==None:
break
crop_image=frame[38:70,11:364]
gray=cv2.cvtColor(crop_image,cv2.COLOR_BGR2GRAY)
for i in range(0,11):
res= cv2.matchTemplate(gray,templates["template_"+str(i)],cv2.TM_CCOEFF_NORMED)
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
les_points[i].append(pt[0])
cv2.rectangle(crop_image, pt, (pt[0] + w[i], pt[1] + h[i]), (0,i*10,255), 2)
print les_points
cv2.imshow('normal',crop_image)
if cv2.waitKey(1)& 0xFF == ord('p'):
threshold=threshold+0.01
print threshold
if cv2.waitKey(1)& 0xFF == ord('m'):
threshold=threshold-0.01
print threshold
if cv2.waitKey(1) & 0xFF == ord('q'):
break
我正在通过将图像分割为与模板中字符完全相同的大小来进行其他测试,但是这并没有产生良好的结果。
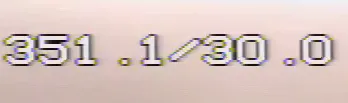 似乎字符没有分开,这就是我从相机中获得的最大分辨率。然后我尝试按颜色进行过滤,但是由于这是视频,并且背景总是在移动,所以没有结果。我将使用任何建议的可以工作的Python模块。
似乎字符没有分开,这就是我从相机中获得的最大分辨率。然后我尝试按颜色进行过滤,但是由于这是视频,并且背景总是在移动,所以没有结果。我将使用任何建议的可以工作的Python模块。