是否存在一种现有的方法,或者我需要在将数据传递给ZipInputStream之前手动解析并跳过exe块?
4个回答
17
在查看了EXE文件格式和ZIP文件格式并测试了各种选项后,最简单的解决方案似乎是忽略第一个zip局部文件头之前的任何序言。
我编写了一个输入流过滤器来绕过序言,并且它运行得非常完美:
ZipInputStream zis = new ZipInputStream(
new WinZipInputStream(
new FileInputStream("test.exe")));
while ((ze = zis.getNextEntry()) != null) {
. . .
zis.closeEntry();
}
zis.close();
WinZipInputStream.java
import java.io.FilterInputStream;
import java.io.InputStream;
import java.io.IOException;
public class WinZipInputStream extends FilterInputStream {
public static final byte[] ZIP_LOCAL = { 0x50, 0x4b, 0x03, 0x04 };
protected int ip;
protected int op;
public WinZipInputStream(InputStream is) {
super(is);
}
public int read() throws IOException {
while(ip < ZIP_LOCAL.length) {
int c = super.read();
if (c == ZIP_LOCAL[ip]) {
ip++;
}
else ip = 0;
}
if (op < ZIP_LOCAL.length)
return ZIP_LOCAL[op++];
else
return super.read();
}
public int read(byte[] b, int off, int len) throws IOException {
if (op == ZIP_LOCAL.length) return super.read(b, off, len);
int l = 0;
while (l < Math.min(len, ZIP_LOCAL.length)) {
b[l++] = (byte)read();
}
return l;
}
}
- James Allman
1
非常感谢,这对我帮助很大。 - Nagaraj N
7
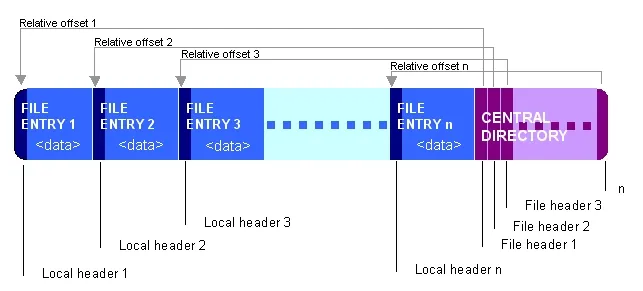
ZIP文件的好处在于其顺序结构:每个条目都是独立的字节块,并且在末尾有一个“中央目录索引”,列出了文件中所有条目及其偏移量。
不好的地方在于,java.util.zip.*类忽略了该索引并开始读取文件,期望第一个条目是一个本地文件头块,而这不适用于自解压缩的ZIP归档(这些以EXE部分开头)。
几年前,我编写了一个自定义的ZIP解析器,用于提取依赖CDI找到文件中的ZIP条目(LFH +数据)的代码。我刚刚检查过它,实际上可以直接列出一个自解压缩ZIP档案的条目并给你偏移量 - 所以,你可以:
使用该代码找到EXE部分后的第一个LFH,并将该偏移量之后的所有内容复制到不同的:File中,然后将该新File馈送到java.util.zip.ZipFile中编辑:跳过EXE部分似乎行不通,
ZipFile仍然不能读取它,我的本机ZIP程序会抱怨新ZIP文件已损坏,并且给出跳过的字节数作为“丢失”的数量(因此它实际上读取了CDI)。我猜一些标题需要被重写,因此下面给出的第二个方法看起来更有前途 - 或- 使用该代码进行完整的ZIP提取(类似于
java.util.zip);这将需要一些额外的管道,因为该代码最初并不是作为替换ZIP库而设计的,而是具有非常特定的用例(在HTTP上差分更新ZIP文件)
该代码托管在SourceForge (项目页面,网站),并在Apache许可证2.0下许可,因此商业使用没问题- AFAIK有一个商业游戏使用它作为其游戏资源的更新程序。
从ZIP文件获取偏移量的有趣部分位于Indexer.parseZipFile中,它返回一个LinkedHashMap<Resource, Long>(因此第一个映射条目在文件中具有最低的偏移量)。以下是我用于列出一个自解压缩的ZIP存档条目(使用Wine在Ubuntu上创建的WinZIP SE创建器从acra发布文件)的代码:
public static void main(String[] args) throws Exception {
File archive = new File("/home/phil/downloads", "acra-4.2.3.exe");
Map<Resource, Long> resources = parseZipFile(archive);
for (Entry<Resource, Long> resource : resources.entrySet()) {
System.out.println(resource.getKey() + ": " + resource.getValue());
}
}
除了包含所有标题解析类的zip包和Indexer类之外,您可能可以剥离大部分代码。
- Philipp Reichart
1
1谢谢提供的信息,让我找到了正确的方向。最终,我编写了一个简单的输入过滤器来忽略第一个本地头块之前的所有内容。 - James Allman
2
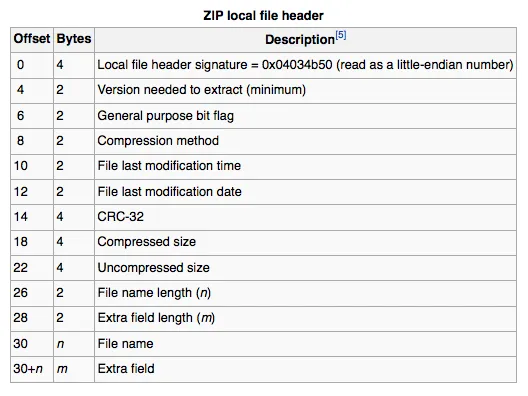
一些自解压缩的ZIP文件中存在虚假的本地文件头标记。我认为最好是反向扫描文件以找到中央目录结束符记录。EOCD记录包含中央目录的偏移量,而CD包含第一个本地文件头的偏移量。如果从本地文件头的第一个字节开始读取,
ZipInputStream可以正常工作。
显然下面的代码不是最快的解决方案。如果要处理大型文件,应该实现某种缓冲或使用内存映射文件。
import org.apache.commons.io.EndianUtils;
...
public class ZipHandler {
private static final byte[] EOCD_MARKER = { 0x06, 0x05, 0x4b, 0x50 };
public InputStream openExecutableZipFile(Path zipFilePath) throws IOException {
try (RandomAccessFile raf = new RandomAccessFile(zipFilePath.toFile(), "r")) {
long position = raf.length() - 1;
int markerIndex = 0;
byte[] buffer = new byte[4];
while (position > EOCD_MARKER.length) {
raf.seek(position);
raf.read(buffer, 0 ,1);
if (buffer[0] == EOCD_MARKER[markerIndex]) {
markerIndex++;
} else {
markerIndex = 0;
}
if (markerIndex == EOCD_MARKER.length) {
raf.skipBytes(15);
raf.read(buffer, 0, 4);
int centralDirectoryOffset = EndianUtils.readSwappedInteger(buffer, 0);
raf.seek(centralDirectoryOffset);
raf.skipBytes(42);
raf.read(buffer, 0, 4);
int localFileHeaderOffset = EndianUtils.readSwappedInteger(buffer, 0);
return new SkippingInputStream(Files.newInputStream(zipFilePath), localFileHeaderOffset);
}
position--;
}
throw new IOException("No EOCD marker found");
}
}
}
public class SkippingInputStream extends FilterInputStream {
private int bytesToSkip;
private int bytesAlreadySkipped;
public SkippingInputStream(InputStream inputStream, int bytesToSkip) {
super(inputStream);
this.bytesToSkip = bytesToSkip;
this.bytesAlreadySkipped = 0;
}
@Override
public int read() throws IOException {
while (bytesAlreadySkipped < bytesToSkip) {
int c = super.read();
if (c == -1) {
return -1;
}
bytesAlreadySkipped++;
}
return super.read();
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
if (bytesAlreadySkipped == bytesToSkip) {
return super.read(b, off, len);
}
int count = 0;
while (count < len) {
int c = read();
if (c == -1) {
break;
}
b[count++] = (byte) c;
}
return count;
}
}
- skuzniarz
-1
在这种情况下,TrueZip效果最好。(至少在我的情况下)
自解压缩zip的格式为code1 header1 file1(而普通zip的格式为header1 file1)...代码告诉如何提取zip文件。
尽管Truezip提取工具会抱怨额外的字节并抛出异常
以下是代码:
private void Extract(String src, String dst, String incPath) {
TFile srcFile = new TFile(src, incPath);
TFile dstFile = new TFile(dst);
try {
TFile.cp_rp(srcFile, dstFile, TArchiveDetector.NULL);
}
catch (IOException e) {
//Handle Exception
}
}
你可以像这样调用该方法:Extract(new String("C:\2006Production.exe"), new String("c:\") , "");
文件将会被提取到C盘中,您可以对其进行自己的操作。希望这能帮到您。
谢谢。
- jaysun
1
1你为什么不处理异常?而且当它只能是true时,为什么要返回一个布尔值? - Robin Salih
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接