我很快就要创建一个多线程项目,但我看到了一些实验(delphitools.info/2011/10/13/memory-manager-investigations)表明默认的Delphi内存管理器在多线程方面存在问题。
因此,我找到了这个SynScaleMM。有人可以对它或类似的内存管理器提供一些反馈吗?
谢谢
我很快就要创建一个多线程项目,但我看到了一些实验(delphitools.info/2011/10/13/memory-manager-investigations)表明默认的Delphi内存管理器在多线程方面存在问题。
因此,我找到了这个SynScaleMM。有人可以对它或类似的内存管理器提供一些反馈吗?
谢谢
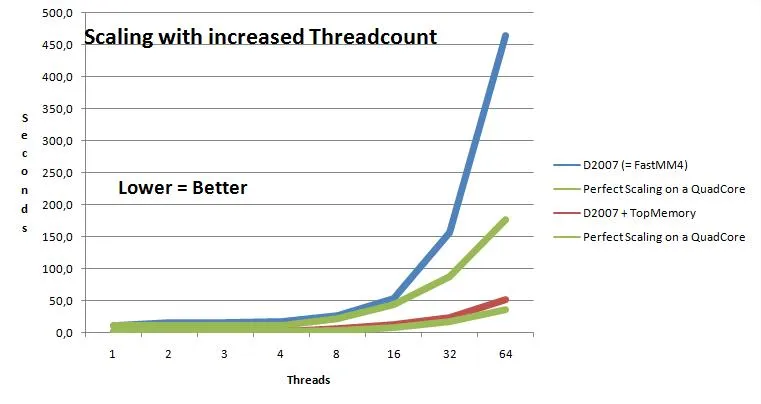
我们的 SynScaleMM 目前仍处于实验阶段。
编辑:请参考更稳定的ScaleMM2 和全新的SAPMM。但是我下面的评论仍然值得关注:你分配的资源越少,扩展性就会越好!
在多线程服务器环境中,它按预期工作。在某些关键测试中,扩展性比 FastMM4 更好。
但是,在多线程应用程序中,内存管理器可能不是最大的瓶颈。如果不过度使用,FastMM4 可能表现良好。
以下是一些建议(并非教条主义,只是来自实验和对 Delphi RTL 低级别知识的了解),以编写快速的多线程 Delphi 应用程序:
const,例如:MyFunc(const aString: String),以避免每次调用时分配临时字符串;s := s+'Blabla'+IntToStr(i)),而依赖于缓冲写入(例如最新版本的 Delphi 中提供的 TStringBuilder);TStringBuilder 也不完美:例如,它将为附加一些数字数据创建大量临时字符串,并在添加某些 integer 值时使用非常缓慢的SysUtils.IntToStr()函数。我不得不重写许多低级别函数,以避免我们在SynCommons.pas中定义的 TTextWriter 类中的大多数字符串分配。InterlockedIncrement / InterlockedExchangeAdd;InterlockedExchange(来自SysUtils.pas)是更新缓冲区或共享对象的好方法。您在线程中创建了某些内容的更新版本,然后在一个低级CPU操作中交换了指向数据的共享指针(例如TObject实例)。它将通过非常好的多线程扩展性向其他线程通知更改。你必须注意数据完整性,但实际上它很有效。PosEx();AnsiString / UnicodeString类型的变量/函数,并通过Alt-F2检查生成的汇编代码以跟踪任何隐藏的不必要转换(例如call UStrFromPCharLen);procedure中使用var参数,而不是返回字符串的function(返回string的函数会添加一个UStrAsg/LStrAsg调用,它具有LOCK,会刷新所有CPU核心);TMemoryStream,而是依赖于类中的一个私有实例,已经分配足够内存大小,在其中使用Position写入数据以检索数据结尾,而不改变其Size(这将是MM分配的内存块);record/object指针,将数据映射而不将其复制到临时内存中;我在我们的Open Source框架中尝试遵循这些规则,如果您查看我们的代码,您将找到许多实际的样例代码。
String。因此,这里将有更多的内存分配。自Delphi 2009以来,您将失去Unicode功能。在某些情况下,ShortString可能很方便(用于处理数字数据或代码级标识符),但您必须仅使用ShortString方法以避免所有这些隐藏的转换为string。因此,在我看来,这不是一个通用的建议规则-它可能会减慢您的应用程序。 - Arnaud Bouchezunit msvcrtMM;
interface
implementation
type
size_t = Cardinal;
const
msvcrtDLL = 'msvcrt.dll';
function malloc(Size: size_t): Pointer; cdecl; external msvcrtDLL;
function realloc(P: Pointer; Size: size_t): Pointer; cdecl; external msvcrtDLL;
procedure free(P: Pointer); cdecl; external msvcrtDLL;
function GetMem(Size: Integer): Pointer;
begin
Result := malloc(size);
end;
function FreeMem(P: Pointer): Integer;
begin
free(P);
Result := 0;
end;
function ReallocMem(P: Pointer; Size: Integer): Pointer;
begin
Result := realloc(P, Size);
end;
function AllocMem(Size: Cardinal): Pointer;
begin
Result := GetMem(Size);
if Assigned(Result) then begin
FillChar(Result^, Size, 0);
end;
end;
function RegisterUnregisterExpectedMemoryLeak(P: Pointer): Boolean;
begin
Result := False;
end;
const
MemoryManager: TMemoryManagerEx = (
GetMem: GetMem;
FreeMem: FreeMem;
ReallocMem: ReallocMem;
AllocMem: AllocMem;
RegisterExpectedMemoryLeak: RegisterUnregisterExpectedMemoryLeak;
UnregisterExpectedMemoryLeak: RegisterUnregisterExpectedMemoryLeak
);
initialization
SetMemoryManager(MemoryManager);
end.
值得指出的是,在FastMM中线程争用成为性能障碍之前,您的应用程序必须相当频繁地使用堆分配器。根据我的经验,这通常发生在应用程序进行大量字符串处理时。
对于任何遭受堆分配线程争用问题的人,我的主要建议是重新设计代码,以避免频繁使用堆。这样不仅可以避免争用,还可以避免堆分配的开销-一举两得!
重点在于锁定!
需要注意的两个问题:
LOCK前缀的情况;LOCK前缀的情况Borland Delphi 5于1999年发布,引入了字符串操作中的lock前缀。如您所知,当您将一个字符串赋值给另一个字符串时,它不会复制整个字符串,而只是增加字符串内部的引用计数器。如果您修改该字符串,它将取消引用,减少引用计数器并为修改后的字符串分配单独的空间。
function AssignStringThreadSafe(const Src: string): string;
var
L: Integer;
begin
L := Length(Src);
if L <= 0 then Result := '' else
begin
SetString(Result, nil, L);
Move(PChar(Src)^, PChar(Result)^, L*SizeOf(Src[1]));
end;
end;
但是在Delphi 5中,Borland为字符串操作添加了LOCK前缀后,即使对于单线程应用程序,它们也变得非常缓慢,与Delphi 4相比。
为了克服这种缓慢,程序员开始使用“单线程”SYSTEM.PAS补丁文件,并注释掉锁定。
请参见https://synopse.info/forum/viewtopic.php?id=57&p=1获取更多信息。
您可以修改FastMM4源代码以获得更好的锁定机制,或使用任何现有的FastMM4分支,例如https://github.com/maximmasiutin/FastMM4
在多核操作中,FastMM4不是最快的,特别是当线程数大于物理插槽数时,因为默认情况下在线程争用(即一个线程无法获取由另一个线程锁定的数据时),它会调用Windows API函数Sleep(0),然后如果锁仍然不可用,则在每次检查锁之后调用Sleep(1)进入循环。
每次调用Sleep(0)都经历昂贵的上下文切换成本,可以达到10000个以上的周期;它还承受着从Ring 3到Ring 0的转换成本,可以达到1000个以上的周期。至于Sleep(1) - 除了与Sleep(0)相关的成本之外 - 它还至少延迟执行1毫秒,将控制权让给其他线程,并且如果没有线程等待被物理CPU核心执行,则将核心置于休眠状态,有效降低CPU使用率和功耗。
这就是为什么在使用FastMM进行多线程工作时,CPU使用率从未达到100% - 因为FastMM4发出了Sleep(1)。这种获取锁的方式并不是最优的。更好的方式是使用大约5000个pause指令的自旋锁,如果锁仍然忙碌,则调用SwitchToThread() API调用。如果pause不可用(在没有SSE2支持的非常旧的处理器上)或SwitchToThread() API调用不可用(在早于Windows 2000的旧版Windows上),最好的解决方案是利用EnterCriticalSection/LeaveCriticalSection,它们不会伴随着Sleep(1)的延迟,并且可以非常有效地将CPU核心控制权移交给其他线程。pause+SwitchToThread()的自旋循环,如果其中任何一个不可用:使用CriticalSection代替Sleep()。使用这些选项,将永远不会使用Sleep(),而是改用EnterCriticalSection/LeaveCriticalSection。测试表明,在与内存管理器一起工作的线程数与物理核心数相同或更高的情况下,使用CriticalSection而不是Sleep(在FastMM4中默认使用)的方法提供了显着的收益。在具有多个物理CPU和非统一内存访问(NUMA)的计算机上,这种收益更为明显。我已经实现了编译时选项,以取代使用Sleep(InitialSleepTime)然后使用Sleep(AdditionalSleepTime)(或Sleep(0)和Sleep(1))的原始FastMM4方法,并使用EnterCriticalSection/LeaveCriticalSection来节省宝贵的CPU周期,避免由Sleep(0)浪费的时间并提高速度(降低延迟),每次Sleep(1)至少受到1毫秒的影响,因为关键部分比Sleep(1)更适合CPU,延迟肯定更低。这指的是在英特尔Pentium 4处理器和英特尔Xeon处理器上使用自旋循环应用笔记。
你也可以在stackoverflow上找到一个非常好的自旋循环实现。
它还会加载普通的负载来检查,然后再发出lock存储,在循环中不要洪水般地进行锁定操作,否则会锁定总线。
FastMM4本身非常优秀。只需改进锁定,就可以获得出色的多线程内存管理器。
请注意,FastMM4中每个小块类型都是单独锁定的。
您可以在小块控制区之间放置填充,使每个区域具有自己的缓存行,不与其他块大小共享,并确保它以缓存行大小边界开始。您可以使用CPUID来确定CPU缓存行的大小。
因此,如果正确实现了适合您需求的锁定(即无论您是否需要NUMA,是否使用lock释放等),您可以获得内存分配例程的结果会快几倍,并且不会受到线程争用的严重影响。
FastMM对多线程处理非常好。它是Delphi 2006及以上版本的默认内存管理器。
如果您正在使用较旧的Delphi版本(Delphi 5及以上),您仍然可以使用FastMM。它可以在SourceForge上获取。
Delphi 6 的内存管理器已经过时且非常糟糕。我们在高负载生产服务器和多线程桌面应用程序上都使用了 RecyclerMM,并且没有遇到任何问题:它快速、可靠,不会导致过度碎片化。(碎片化是 Delphi 内存管理器最严重的问题)。
RecyclerMM 唯一的缺点是它不能直接与 MemCheck 兼容。但是,进行小的源代码修改就足以使其兼容。