目前,我正在学习并行化,并在探究我编写的测试程序为何缩放效果不佳。我有一个简单的程序,通过L次迭代进行CPU限制计算,并将这些迭代分散到测试中的线程数上(从1到8个)。虽然我不期望完美的比例尺(8个线程比1个线程快8倍),但我看到的扩展效果似乎很糟糕,我认为一定是有什么问题我没发现。
我假设要么我的代码有问题,要么存在我没有理解的并行化方面。
我认为可以排除以下事情:
- 所做的工作仅使用局部变量,因此我不认为内存带宽或缓存问题是个问题。
- 我已经尝试了将每个线程固定到不同的内核并没有看到任何性能改善。
硬件:
Lenovo T495
Operating System: Fedora 32
KDE Plasma Version: 5.18.5
KDE Frameworks Version: 5.75.0
Qt Version: 5.14.2
Kernel Version: 5.11.13-100.fc32.x86_64
OS Type: 64-bit
Processors: 8 × AMD Ryzen 5 PRO 3500U w/ Radeon Vega Mobile Gfx
Memory: 21.5 GiB of RAM
这是我写的代码:
use std::thread;
use std::time::Instant;
fn main() {
let loops = 10_000_000_000;
for threads in 1..=8 {
// As threads are added to the test, evenly split the total number of iterations
// across all threads, so that 1 thread test can be compared to 4 thread test.
// For `threads` that are not divisors of `loops` some threads may have one more
// iteration than the others but that will be 1 out of 10,000,000 and should have
// negligible effect on the run time.
n_threads(threads, loops / threads);
}
}
/// Have `num_threads` threads each run a function that will
/// iterate a computation `loops` times.
fn n_threads(num_threads: usize, loops: usize) {
let sw = Instant::now();
let mut threads = Vec::new();
for _ in 0..num_threads {
let t = thread::spawn(move || {
let sw = Instant::now();
let v = work(loops);
(v, sw.elapsed().as_millis())
});
threads.push(t);
}
let mut durations = vec![0; num_threads];
let mut idx = 0;
for t in threads.into_iter() {
let (_, dur) = t.join().unwrap();
durations[idx] = dur;
idx += 1;
}
let time = sw.elapsed();
let avg = durations.iter().sum::<u128>() as f64 / num_threads as f64;
println!("{}, {}, {}", num_threads, time.as_millis(), avg);
}
fn work(loops: usize) -> f64 {
let mut x = 0.5;
for i in 0..loops {
x += (i as f64 / 10000.).sin();
}
x
}
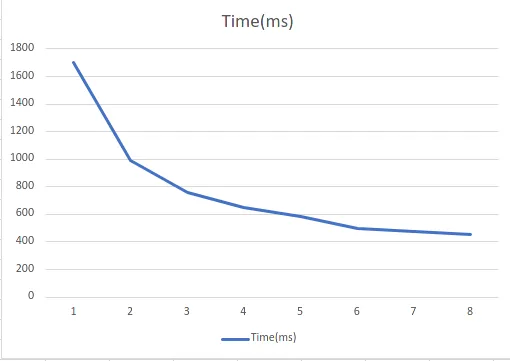
当我运行我的测试时,我得到了以下结果:
| Threads | Time (ms) | Scale Factor |
| -------:| ---------:| ------------:|
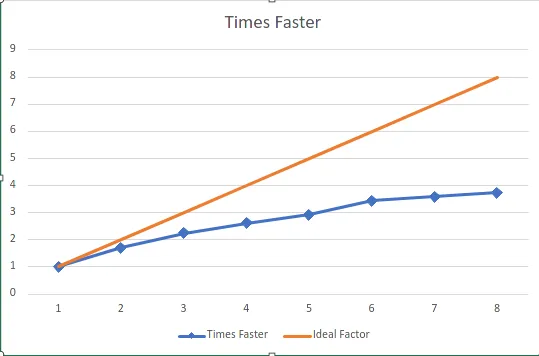
| 1 | 1702 | 1 |
| 2 | 993 | 1.713997986 |
| 3 | 757 | 2.248348745 |
| 4 | 650 | 2.618461538 |
| 5 | 582 | 2.924398625 |
| 6 | 495 | 3.438383838 |
| 7 | 475 | 3.583157895 |
| 8 | 455 | 3.740659341 |
这里有一个图表显示了运行测试的时间与计算线程数之间的变化:
 这里还有一个图表,显示了性能乘数与线程数以及完美乘数之间的关系:
这里还有一个图表,显示了性能乘数与线程数以及完美乘数之间的关系:
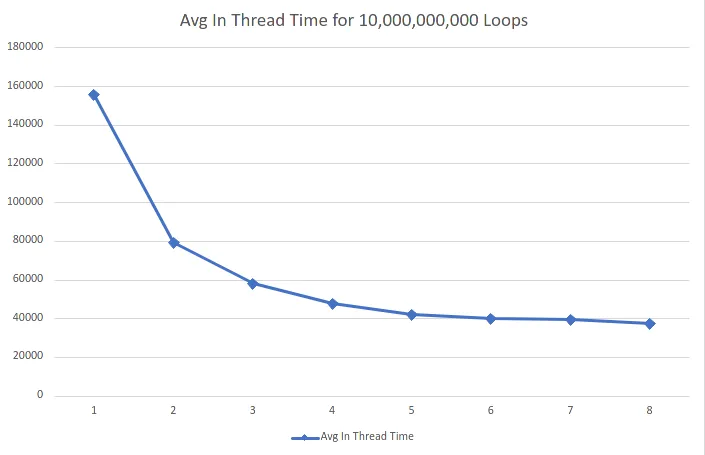
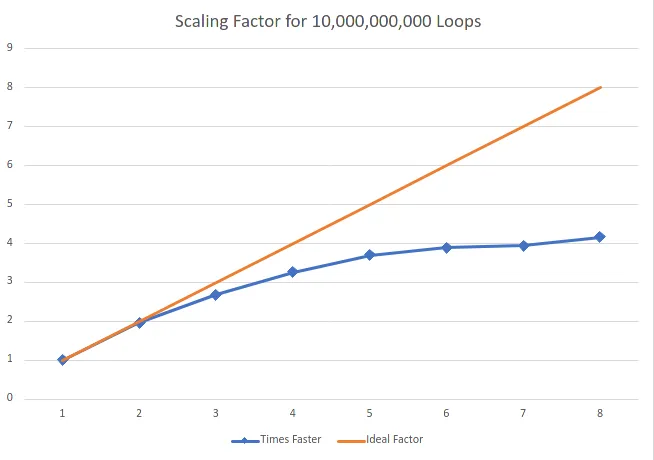
使用10亿次迭代的更新测试分布在线程中
按照要求进行更长时间的测试,我增加了100倍的迭代次数。同时,我也将计时移至线程内部(并更新了上面的代码)。Thread | Avg In Thread Time | Times Faster
1 | 155564 | 1
2 | 79400.5 | 1.959232
3 | 57965 | 2.683757
4 | 47753.25 | 3.257663
5 | 42054.6 | 3.699096
6 | 40028.66667 | 3.886315
7 | 39479.28571 | 3.940396
8 | 37376.625 | 4.162067
loops再增加一个0,这个趋势是否仍然存在?没有更多的信息很难知道这是否正常。你有多少个CPU? - trent