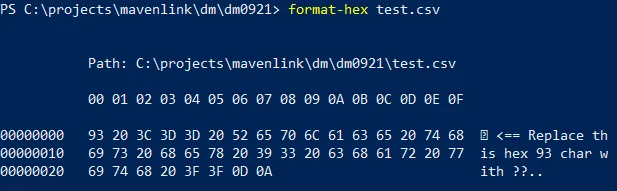
在 Windows PowerShell 中,读取/写入文件时的默认字符编码为“ANSI”,即活动系统语言环境所隐含的旧的8位代码页。
(相比之下,PowerShell Core 的默认编码为 UTF-8。)
例如,在美式英语系统上与系统语言环境相关联的代码页是 1252,即 Windows-1252,其中代码点0x93是非ASCII的引号符“。
但是,一旦将文本文件的内容读入内存中,内存中 字符串的字符以 UTF-16LE 代码单元表示,也就是 .NET [string] 实例。
作为一个 Unicode 字符,“的”有代码点U+201c,在UTF-16LE中表示为 0x201c。
因此,你需要替换的是 [char] 0x201c:
$q1 = [char] 0x201c
Get-ChildItem *.csv -Recurse | ForEach-Object {
(Get-Content $_.FullName) -replace $q1, '""' | Set-Content $_.FullName
}
请注意,
Set-Content也使用默认字符编码,因此重写的文件也将使用“ANSI”编码 - 如果需要更改输出编码,请使用
-Encoding参数。
还要注意
Get-Content调用周围的
(...),这确保输入文件被完全读入内存,从而使在同一管道中向同一文件写回成为可能。虽然这种方法很方便,但请注意,在完成之前如果写回输入文件操作被中断,存在轻微数据丢失的风险。
将“ANSI”代码点转换为Unicode代码点
以下显示了如何将“ANSI”(8位)代码点(例如
0x93)转换为其等效的UTF-16代码点
0x201c:
$str = [Text.Encoding]::Default.GetString([byte[]] 0x93)
$codePoints = [int[]] [char[]] $str
'0x{0:x}' -f $codePoints[0]
[1] 使用Set-Content编写文件,即使用Out-File / >则创建UTF-16LE(“Unicode”)文件。Windows PowerShell中的cmdlets显示了各种不同的编码:请参见此答案。幸运的是,PowerShell Core现在默认使用(无BOM)UTF-8。