我对Trie数据结构是如何节省空间并以最紧凑的形式存储数据感到困惑!
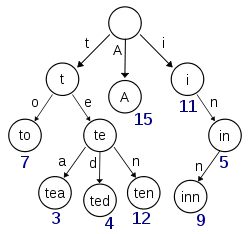
如果你看下面的树。当你在任何节点存储一个字符时,你也需要存储对该字符的引用,因此对于字符串的每个字符,你需要存储它的引用。 当一个常见字符出现时,我们确实可以节省一些空间,但是在存储对该字符节点的引用时,我们失去了更多的空间。
那么难道不需要有很多结构性的开销来维护这个树本身吗?相反,如果使用TreeMap来实现字典,比如说,这将可以节省更多的空间,因为字符串将保持完整,因此不会浪费存储引用的空间,是吗?
我对Trie数据结构是如何节省空间并以最紧凑的形式存储数据感到困惑!
如果你看下面的树。当你在任何节点存储一个字符时,你也需要存储对该字符的引用,因此对于字符串的每个字符,你需要存储它的引用。 当一个常见字符出现时,我们确实可以节省一些空间,但是在存储对该字符节点的引用时,我们失去了更多的空间。
那么难道不需要有很多结构性的开销来维护这个树本身吗?相反,如果使用TreeMap来实现字典,比如说,这将可以节省更多的空间,因为字符串将保持完整,因此不会浪费存储引用的空间,是吗?
请注意,Trie通常用作一组字符串的前缀匹配的高效数据结构。Trie也可以用作关联数组(类似于哈希表),其中键是字符串。
如果您需要用树来表示大量单词,那么使用树可以节省空间。因为许多单词在树中共享相同的路径;您拥有的单词越多,您将节省更多的空间。
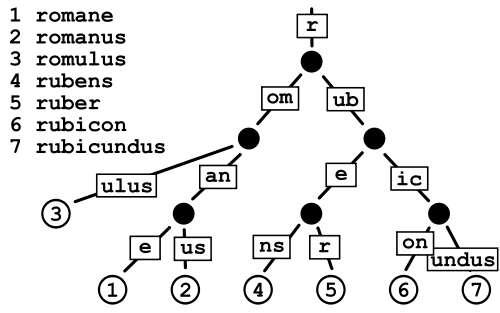
但是,如果您想节省空间,那么有一种更好的数据结构。与Trie不同,有向无环图(DAWG)通过整个结构共享公共节点来节省空间。 维基百科条目详细解释了这一点,请查看。
以下是Trie和DAWG之间的差异(以图形方式):
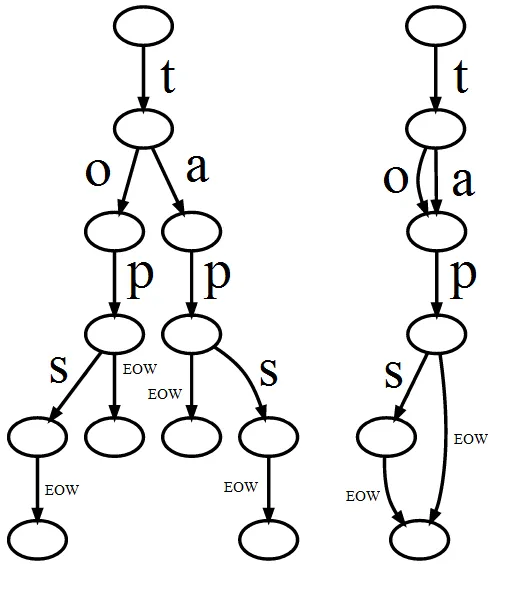
这不仅仅是内存空间的问题,而是文件或通信链路上宝贵空间的问题。通过构建 trie 算法,我们可以用左-右-右三位二进制码发送 “ten”,相比未压缩前需要 24 位二进制码,这将节省大量宝贵的磁盘空间或传输带宽。
Guava 可能确实在每个级别存储键,但要意识到的是,实际上不需要存储键,因为节点的路径完全定义了该节点的键。每个节点实际上只需要存储一个布尔值,指示这是否是叶节点。
Tries(字典树),像任何其他结构一样,擅长存储某些类型的数据。具体来说,Tries 最擅长存储共享公共前缀的字符串。例如,考虑存储完整路径目录列表。