Template matching在这种应用中往往不够稳健,因为存在光照不一致、方向变化、尺度变化等问题。解决这个问题的典型方法是引入机器学习。通过训练自己的增强分类器来实现你正在尝试的目标是一种可能的方法。然而,我认为你没有正确地进行训练。你提到给了它1个带有正标志的训练图像和5个不包含标志的负样本?通常情况下,你需要的训练样本数量应该是数百或数千甚至更多。你不可能只用6个训练样本来进行训练并期望它能工作。
如果你对机器学习不熟悉,以下是你应该做的大致步骤:
1)你需要收集许多正样本(从几百个开始,但通常越多越好)以便训练检测对象。如果你想检测图像中的单个字符,则需获取单个字符的裁剪图像。你可以从MNIST数据库开始。更好的方法是,为了针对你特定的问题训练分类器,请从照片中获得公交车上的许多字符的裁剪图像。如果你想检测整个长方形LED面板,则使用它们的图像作为你的正样本。
2) 您需要收集许多负面训练样本。它们的数量应与您拥有的正面训练样本相同。这些可以是出现在您检测器运行的图像中的其他对象的图像。例如,您可以裁剪公共汽车前部、路面、路边树木等图像,并将其用作负面示例。这有助于分类器在您运行检测器的图像中排除这些对象。因此,负面示例
不仅仅是包含您不想检测的对象的任何图像。它们应该是在您运行检测器的图像中可能被误认为是您要检测的对象的对象(至少对于您的情况而言)。
请参见以下链接,了解如何训练级联分类器并生成XML模型文件:
http://note.sonots.com/SciSoftware/haartraining.html
尽管您提到您只想检测公交车上的单个字符而非整个LED面板,但我建议先检测LED面板以定位包含所需字符的区域。之后,可以在该较小区域内执行模板匹配,或者使用滑动窗口方法获取该区域中像素块上训练过识别单个字符的分类器,并可能在多个比例下运行。 (注意:您上面提到的haarcascade boosting分类器将检测字符,但除非您仅训练它以检测特定字符,否则它不会告诉您检测到了哪个字符...)以滑动窗口方式在此区域中检测字符将给您字符出现的顺序,因此您可以将它们组合成单词等等。
希望这能有所帮助。
编辑:
我刚好在另外发现了OpenCV 3中提到的场景文本模块,并在单独的帖子中看到了我的旧帖子。
对于那些感兴趣的人,这是在OP给出的示例图像上运行该检测器的结果。请注意,该检测器能够定位文本区域,即使它返回了多个边界框。

请注意,这种方法并非百分之百可靠(
至少在OpenCV默认参数下的实现)。它倾向于产生错误的正面反应,特别是当输入图像包含许多“干扰因素”时。以下是在Google Street View数据集上使用此OpenCV 3文本检测器获取的更多示例:



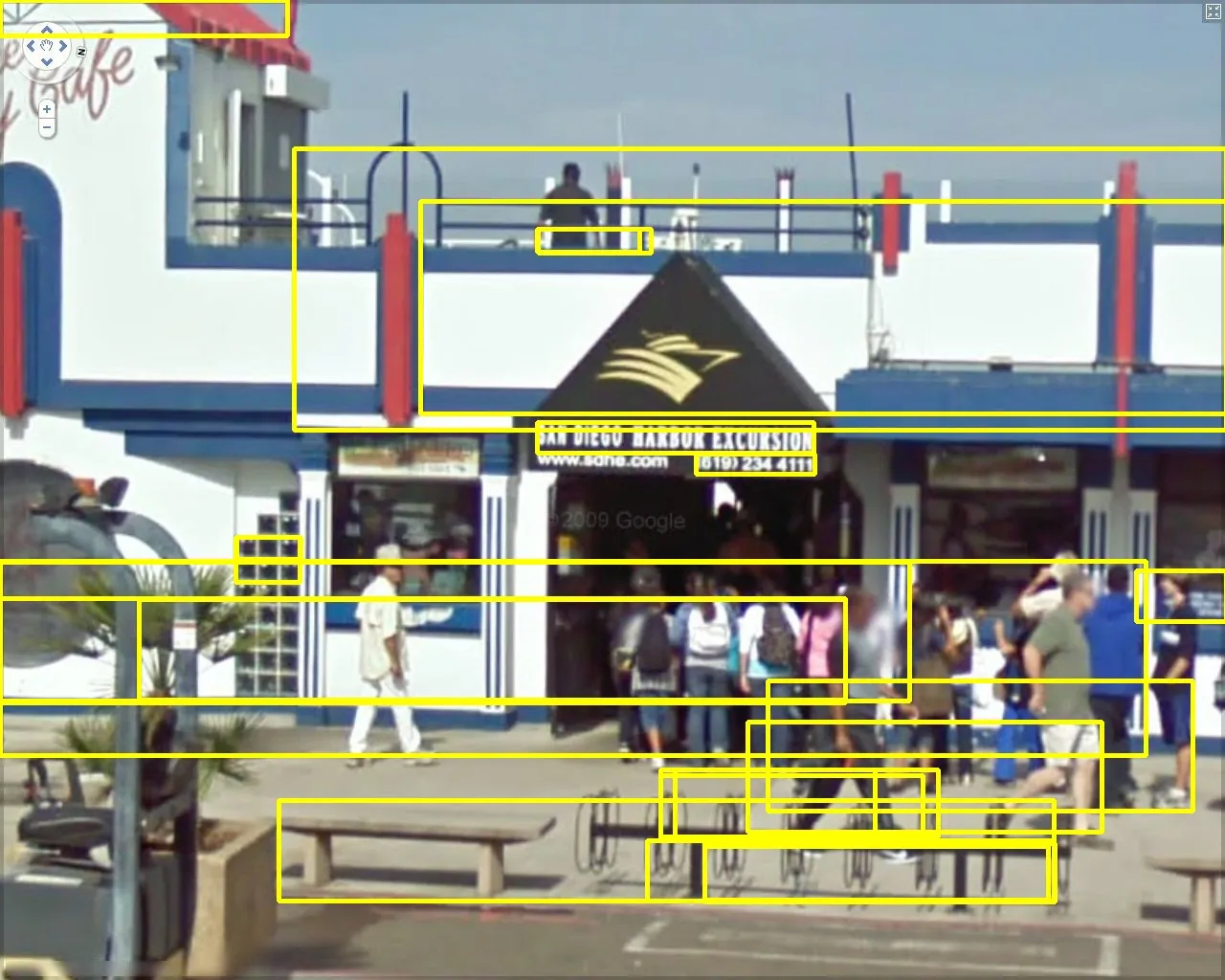
请注意,它有一个倾向于在平行线之间(例如窗户、墙壁等)找到“文本”的趋势。由于OP的输入图像可能包含室外场景,如果他/她不将感兴趣的区域限制在LED标志周围的较小区域内,则这将是一个问题。
看起来,如果您能够定位包含文本的“粗略”区域(例如OP样本图像中的LED标志),那么运行此算法可以帮助您获得更紧密的边界框。但是您将不得不处理假阳性(也许舍弃小区域或使用基于关于字母出现方式的知识的启发式方法在重叠的边界框之间选择)。
以下是有关文本检测的更多资源(讨论+代码+数据集)。
代码
数据集
您可以在此处找到Google Streetview和MSRA数据集。尽管这些数据集中的图像与公交车上LED标志的图像不完全相同,但它们可能有助于从多个竞争算法中选择“最佳”性能算法,或从头开始训练机器学习算法。
http://www.iapr-tc11.org/mediawiki/index.php/Datasets_List
