当我在服务层使用一个长的List<Entity>,并调用JpaRepository的saveAll方法时,Hibernate的跟踪日志显示每个实体都发出了单个SQL语句。
我能否强制它执行批量插入(即多行),而不需要手动操作EntityManger、事务等,甚至是原始的SQL语句字符串?
所谓的多行插入是指不仅从以下情况转变而来:
start transaction
INSERT INTO table VALUES (1, 2)
end transaction
start transaction
INSERT INTO table VALUES (3, 4)
end transaction
start transaction
INSERT INTO table VALUES (5, 6)
end transaction
至:
start transaction
INSERT INTO table VALUES (1, 2)
INSERT INTO table VALUES (3, 4)
INSERT INTO table VALUES (5, 6)
end transaction
但是改为:
start transaction
INSERT INTO table VALUES (1, 2), (3, 4), (5, 6)
end transaction
在生产环境中,我正在使用CockroachDB,性能差异显著。
以下是一个最小化的示例,用于重现问题(为简单起见,我们使用H2)。
./src/main/kotlin/ThingService.kt:
package things
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.web.bind.annotation.RestController
import org.springframework.web.bind.annotation.GetMapping
import org.springframework.data.jpa.repository.JpaRepository
import javax.persistence.Entity
import javax.persistence.Id
import javax.persistence.GeneratedValue
interface ThingRepository : JpaRepository<Thing, Long> {
}
@RestController
class ThingController(private val repository: ThingRepository) {
@GetMapping("/test_trigger")
fun trigger() {
val things: MutableList<Thing> = mutableListOf()
for (i in 3000..3013) {
things.add(Thing(i))
}
repository.saveAll(things)
}
}
@Entity
data class Thing (
var value: Int,
@Id
@GeneratedValue
var id: Long = -1
)
@SpringBootApplication
class Application {
}
fun main(args: Array<String>) {
runApplication<Application>(*args)
}
./src/main/resources/application.properties:
jdbc.driverClassName = org.h2.Driver
jdbc.url = jdbc:h2:mem:db
jdbc.username = sa
jdbc.password = sa
hibernate.dialect=org.hibernate.dialect.H2Dialect
hibernate.hbm2ddl.auto=create
spring.jpa.generate-ddl = true
spring.jpa.show-sql = true
spring.jpa.properties.hibernate.jdbc.batch_size = 10
spring.jpa.properties.hibernate.order_inserts = true
spring.jpa.properties.hibernate.order_updates = true
spring.jpa.properties.hibernate.jdbc.batch_versioned_data = true
./build.gradle.kts:
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
plugins {
val kotlinVersion = "1.2.30"
id("org.springframework.boot") version "2.0.2.RELEASE"
id("org.jetbrains.kotlin.jvm") version kotlinVersion
id("org.jetbrains.kotlin.plugin.spring") version kotlinVersion
id("org.jetbrains.kotlin.plugin.jpa") version kotlinVersion
id("io.spring.dependency-management") version "1.0.5.RELEASE"
}
version = "1.0.0-SNAPSHOT"
tasks.withType<KotlinCompile> {
kotlinOptions {
jvmTarget = "1.8"
freeCompilerArgs = listOf("-Xjsr305=strict")
}
}
repositories {
mavenCentral()
}
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.springframework.boot:spring-boot-starter-data-jpa")
compile("org.jetbrains.kotlin:kotlin-stdlib-jdk8")
compile("org.jetbrains.kotlin:kotlin-reflect")
compile("org.hibernate:hibernate-core")
compile("com.h2database:h2")
}
运行:
./gradlew bootRun
触发数据库插入操作:
curl http://localhost:8080/test_trigger
日志输出:
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: select thing0_.id as id1_0_0_, thing0_.value as value2_0_0_ from thing thing0_ where thing0_.id=?
Hibernate: call next value for hibernate_sequence
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
Hibernate: insert into thing (value, id) values (?, ?)
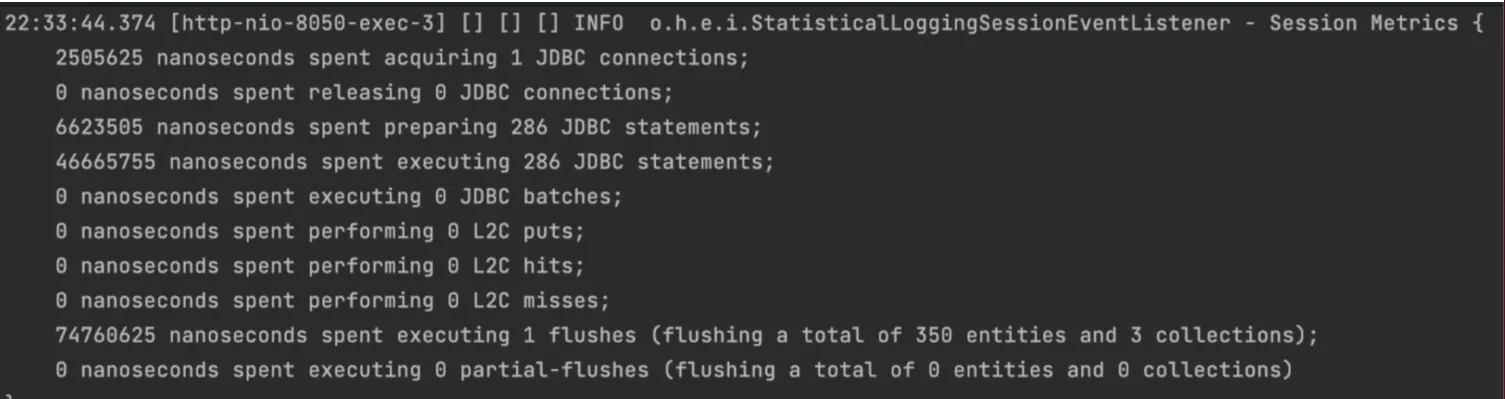
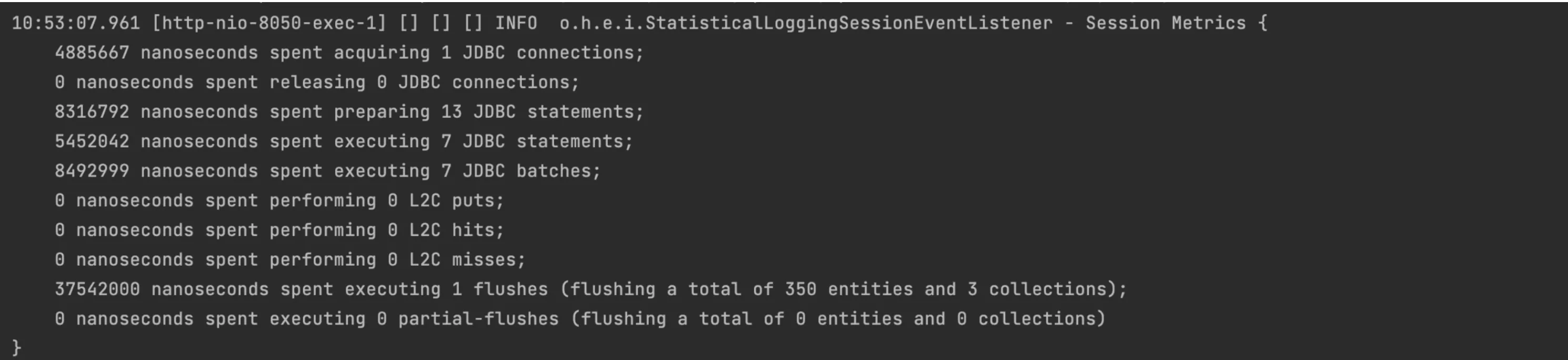
saveAll)。我只是添加了一个最小的代码示例来重现问题。 - Tobias Hermannhibernate.jdbc.batch_size属性吗? - Cepr0spring.jpa.properties.hibernate.jdbc.batch_size。 - Cepr0