你将会获得一个区间集合
起初我想到 interval tree,但我认为它在这里不适用,因为区间树用于获取与给定区间重叠的所有区间。
S。你需要在最小时间复杂度内找到所有被给定区间 (a, b) 包含的区间 S 。通过暴力可以用 O(n) 的时间完成,其中 n 是集合 S 中的区间数。但是,如果我允许做一些预处理,能否在 less than O(n) 的时间内完成,例如 O(log n) 时间?起初我想到 interval tree,但我认为它在这里不适用,因为区间树用于获取与给定区间重叠的所有区间。
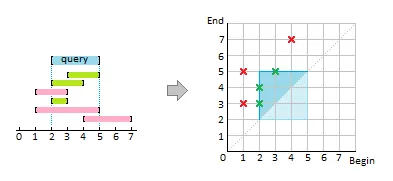
O(n),因为在最坏的情况下,必须将S的所有元素都复制到输出中。 - Patricia ShanahanO(logn)+O(m) = O(n),因为m可能与n一样大。预处理时间也包括在运行时间内,因为如果您想要对区间进行排序或使用某些数据结构进行排列,则这些都是算法的一部分。 - Fallen