我发现在SVM(支持向量机)问题中进行缩放确实可以提高其性能。
我已阅读了这个解释:
缩放的主要优点是避免具有较大数值范围的属性支配具有较小数值范围的属性。
不幸的是,这没有帮助我。能否有人提供更好的解释?
我发现在SVM(支持向量机)问题中进行缩放确实可以提高其性能。
我已阅读了这个解释:
缩放的主要优点是避免具有较大数值范围的属性支配具有较小数值范围的属性。
不幸的是,这没有帮助我。能否有人提供更好的解释?
特征缩放是应用于优化问题(不仅是 SVM)的一种常见技巧。解决 SVM 优化问题的基本算法是梯度下降。Andrew Ng 在他的 Coursera 视频这里中有很好的解释。
我将在此说明核心思想(借用了 Andrew 的幻灯片)。假设您只有两个参数,其中一个参数可以取相对较大的值范围。那么代价函数的轮廓可能看起来像非常高而瘦的椭圆形(请参见下面的蓝色椭圆形)。您的梯度(梯度路径以红色绘制)可能需要很长时间前后移动才能找到最佳解。
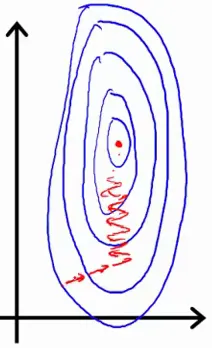
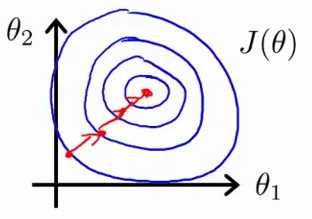
相反,如果您缩放了特征,则代价函数的轮廓可能看起来像圆形;然后梯度可以采用更加直接的路径并更快地实现最优点。
╔═════╦════════╗
║ sex ║ height ║
╠═════╬════════╣
║ 1 ║ 150 ║
╠═════╬════════╣
║ 1 ║ 160 ║
╠═════╬════════╣
║ 1 ║ 170 ║
╠═════╬════════╣
║ 0 ║ 180 ║
╠═════╬════════╣
║ 0 ║ 190 ║
╠═════╬════════╣
║ 0 ║ 200 ║
╚═════╩════════╝
让我们做点儿傻事。训练它来预测人的性别,因此我们试图学习 f(x,y)=x(忽略第二个参数)。
很容易看出,对于这样的数据,最大间隔分类器将在高度“175”左右水平“切割”平面,因此当我们得到新的样本“0 178”(一个身高为178厘米的女性)时,我们会得到她是男性的分类。
然而,如果我们将所有内容缩小到 [0,1] 范围内,我们会得到类似以下结果:
╔═════╦════════╗
║ sex ║ height ║
╠═════╬════════╣
║ 1 ║ 0.0 ║
╠═════╬════════╣
║ 1 ║ 0.2 ║
╠═════╬════════╣
║ 1 ║ 0.4 ║
╠═════╬════════╣
║ 0 ║ 0.6 ║
╠═════╬════════╣
║ 0 ║ 0.8 ║
╠═════╬════════╣
║ 0 ║ 1.0 ║
╚═════╩════════╝
现在,最大间隔分类器“切割”平面几乎是垂直的(正如预期的那样),因此给定一个新样本“0 178”,它也被缩放到大约“0 0.56”,我们得出它是一个女人(正确!)
总的来说,缩放确保仅仅因为某些特征很大而不会将它们用作主要预测因子。
从另一个角度来看的个人想法。
1. 为什么特征缩放会影响结果?
在应用机器学习算法时,有一句话叫做“垃圾进,垃圾出”。您的特征越真实反映数据,算法的准确性就越高。这也适用于机器学习算法如何处理特征之间的关系。与人类大脑不同,当机器学习算法进行分类时,所有特征都由相同的坐标系表达和计算,这在某种程度上建立了特征之间的先验假设(并不是数据本身的真实反映)。此外,大多数算法的本质是找到最合适的权重百分比,以最适合数据。因此,当这些算法的输入是未经缩放的特征时,大规模数据对权重的影响更大。实际上,这并不是数据本身的反映。
2. 为什么通常情况下特征缩放可以提高准确性?
无监督机器学习算法中关于超参数(或超-超参数)选择(例如,层次狄利克雷过程、hLDA)的普遍做法是,您不应该添加任何个人主观假设关于数据。最好的方法只是假设它们具有相等的出现概率。我认为这也适用于这里。特征缩放只是试图假设所有特征具有平等的影响权重的机会,这更真实地反映了您对数据所知道的信息/知识。通常也会导致更好的准确性。
顺便说一下,关于仿射变换不变和更快收敛的问题,这里有一个有趣的链接(英文)在stats.stackexchange.com上。
如果没有归一化,轮廓会很细,因此需要进行归一化: