我在MongoDB中有一个聚合查询,当我直接在shell中运行它时可以正常工作。以下是shell查询:
db.MyCollection.aggregate([
{$match: {_id: {$in: ['A', 'B', 'C']}}},
{$project: {"versions": "$nested.field.version"}},
{$unwind: "$versions"},
{$group: {_id: "$_id", "maxVersion": {$max: "$versions"}}}
])
正如您所看到的,它会执行以下操作:
- 仅匹配具有指定ID的某些文档
- 将嵌套字段投影到基本级别字段(有效地从管道中过滤掉所有其他字段,但仍保留ID)
- 展开我们在管道中投影为单个文档的$versions字段的数组元素
- 查找每个ID的$versions的最大值
Aggregation aggregation = newAggregation(
match(Criteria.where("_id").in(listOfIds))
,project().and("versions").nested(bind("versions", "nested.field.version"))
,unwind("versions")
,group("_id").max("versions").as("maxVersion")
);
当我尝试以调试模式运行代码时,我发现在newAggregation上实际上会出现IllegalArgumentException,提示无法评估。如果我注释掉具有$group子句的那一行,则可以看到aggregation变量的toString()表示形式,其中揭示了$project子句存在问题:
{
"aggregate" : "__collection__" ,
"pipeline" : [
{ "$match" : { "_id" : { "$in" : [ "A" , "B" , "C"]}}} ,
{ "$project" : { "versions" : { "versions" : "$nested.field.version"}}} ,
{ "$unwind" : "$versions"}
]
}
显然,这与我的意图不符,所以我没有正确使用语法。但是说实话,我不认为Spring MongoOps的语法很直观,他们的文档也不是很好。
我没有看到任何调用nested()方法的方法,而不先包含对and()的调用。我认为这是主要问题,因为它会使嵌套加倍。有没有Spring MongoOps英雄可以帮助我正确地编写等效的Java代码?
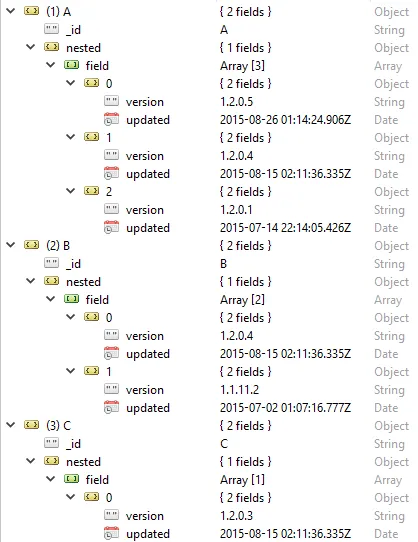
编辑:这是我正在使用的集合的快照: