在我的Neo4J数据库中,我使用双向链表实现了一系列卡片队列。数据结构显示在以下图中(使用Alistair Jones的Arrows在线工具生成的SVG图形队列):
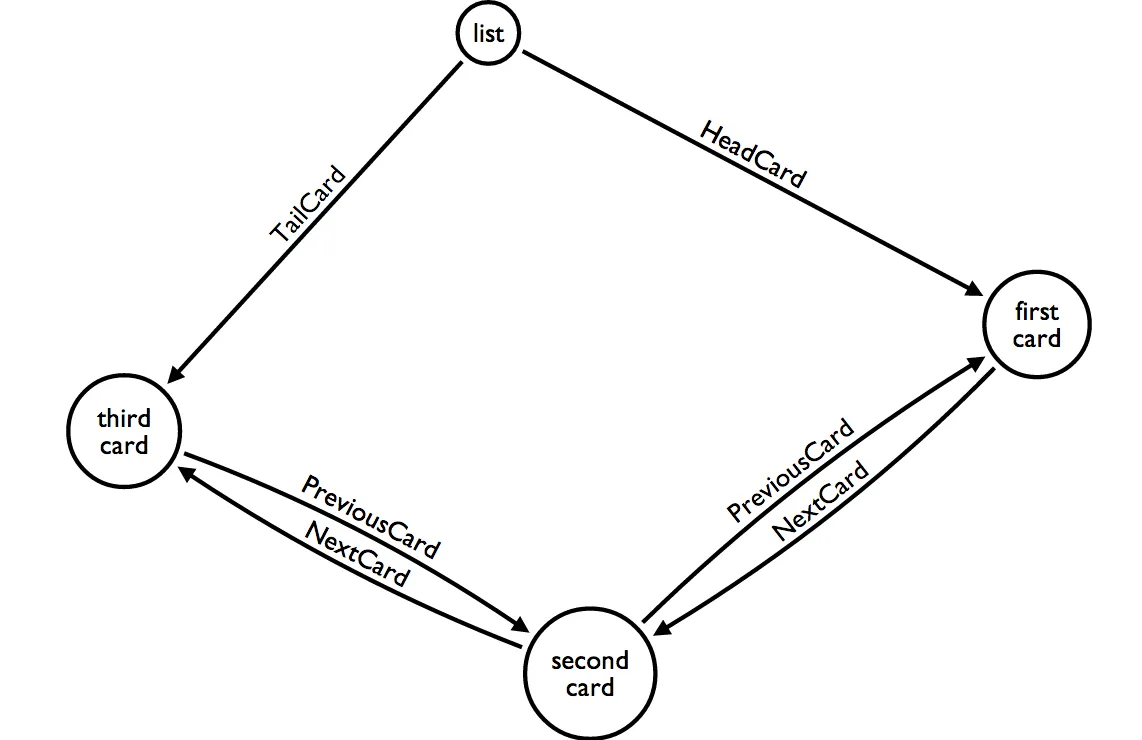
由于这些是队列,我总是从队列的尾部添加新项目。我知道双重关系(下一个/上一个)并不是必要的,但它们可以简化双向遍历,因此我更喜欢保留它们。
插入新节点
以下是我用来插入新“卡片”的查询:
MATCH (currentList:List)-[currentTailRel:TailCard]->(currentTail:Card) WHERE ID(currentList) = {{LIST_ID}}
CREATE (currentList)-[newTailRel:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (newCard)-[newPrevRel:PreviousCard]->(currentTail)
CREATE (currentTail)-[newNextRel:NextCard]->(newCard)
DELETE currentTailRel
WITH count(newCard) as countNewCard
WHERE countNewCard = 0
MATCH (emptyList:List)-[fakeTailRel:TailCard]->(emptyList),
(emptyList)-[fakeHeadRel:HeadCard]->(emptyList)
WHERE ID(emptyList) = {{LIST_ID}}
WITH emptyList, fakeTailRel, fakeHeadRel
CREATE (emptyList)-[:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (emptyList)-[:HeadCard]->(newCard)
DELETE fakeTailRel, fakeHeadRel
RETURN true
查询可以分为两个部分。第一部分:
MATCH (currentList:List)-[currentTailRel:TailCard]->(currentTail:Card) WHERE ID(currentList) = {{LIST_ID}}
CREATE (currentList)-[newTailRel:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (newCard)-[newPrevRel:PreviousCard]->(currentTail)
CREATE (currentTail)-[newNextRel:NextCard]->(newCard)
DELETE currentTailRel
我负责处理将卡片添加到已有其他卡片的队列中的一般情况。 在第二部分:
WITH count(newCard) as countNewCard
WHERE countNewCard = 0
MATCH (emptyList:List)-[fakeTailRel:TailCard]->(emptyList),
(emptyList)-[fakeHeadRel:HeadCard]->(emptyList)
WHERE ID(emptyList) = {{LIST_ID}}
WITH emptyList, fakeTailRel, fakeHeadRel
CREATE (emptyList)-[:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (emptyList)-[:HeadCard]->(newCard)
DELETE fakeTailRel, fakeHeadRel
RETURN true
我处理队列中没有卡片的情况。在这种情况下,(emptyList)节点有两个关系类型为HeadCard和TailCard指向自身的关系(我称之为伪尾和伪头)。
这似乎是有效的。虽然我是一个新手,但我感觉我可能想得太多了,可能有更优雅和简单的方法来实现这一点。例如,我想更好/更简单地理解如何分离这两个子查询。如果可能的话,我也想能够在两种情况下返回新创建的节点。
存档现有节点
以下是我如何从队列中删除节点。我永远不想简单地删除节点,我宁愿将它们添加到存档节点中,以便在需要时可以恢复它们。 我已经确定了这些情况:
当要存档的节点处于队列的中间时
// archive a node in the middle of a doubly-linked list
MATCH (before:Card)-[n1:NextCard]->(middle:Card)-[n2:NextCard]->(after:Card)
WHERE ID(middle)=48
CREATE (before)-[:NextCard]->(after)
CREATE (after)-[:PreviousCard]->(before)
WITH middle, before, after
MATCH (middle)-[r]-(n)
DELETE r
WITH middle, before, after
MATCH (before)<-[:NextCard*]-(c:Card)<-[:HeadCard]-(l:List)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(middle)
RETURN middle
当需要归档的节点是队列的头部时
// archive the head node of a doubly-linked list
MATCH (list:List)-[h1:HeadCard]->(head:Card)-[n1:NextCard]->(second:Card)
WHERE ID(head)=48
CREATE (list)-[:HeadCard]->(second)
WITH head, list
MATCH (head)-[r]-(n)
DELETE r
WITH head, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(head)
RETURN head
当要归档的节点是队列的尾部时
// archive the tail node of a doubly-linked list
MATCH (list:List)-[t1:TailCard]->(tail:Card)-[p1:PreviousCard]->(nextToLast:Card)
WHERE ID(tail)=48
CREATE (list)-[:TailCard]->(nextToLast)
WITH tail, list
MATCH (tail)-[r]-(n)
DELETE r
WITH tail, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(tail)
RETURN tail
当要归档的节点是队列中唯一的节点时
// archive the one and only node in the doubly-linked list
MATCH (list:List)-[tc:TailCard]->(only:Card)<-[hc:HeadCard]-(list:List)
WHERE ID(only)=48
CREATE (list)-[:TailCard]->(list)
CREATE (list)-[:HeadCard]->(list)
WITH only, list
MATCH (only)-[r]-(n)
DELETE r
WITH only, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(only)
RETURN only
我已经尝试了很多种方法将以下密码查询组合成一个,使用WITH语句,但是都没有成功。我的当前计划是依次运行所有4个查询中的一个(即归档节点)。
有什么建议可以使这个过程更好、更简洁?我甚至可以重构数据结构,因为这是我为自己创建的沙盒项目,用于学习Angular和Neo4J,因此最终目标是学会如何更好地做事 :)
也许数据结构本身可以改进?考虑到在队列末尾插入/归档节点有多么复杂,我只能想象移动队列中的元素有多难(我的自我项目要求能够在需要时重新排序队列中的元素)。
编辑:
仍在努力尝试合并这4个查询。 我已经整理好了这个:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
RETURN theCard, before, btc, tca, after, listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
当未找到内容时,该函数返回NULL;当找到内容时,返回节点/关系信息。考虑这可能是一个不错的起点,因此我添加了以下内容:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
WITH theCard,
CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList,
before, btc, tca, after,
listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
FOREACH (value IN beforeList | CREATE (before)-[:NEXT_CARD]->(after))
FOREACH (value IN beforeList | CREATE (after)-[:PREV_CARD]->(before))
FOREACH (value IN beforeList | DELETE btc)
FOREACH (value IN beforeList | DELETE tca)
RETURN theCard
当我执行这个(选择一个ID使
before=NULL),我的笔记本风扇开始疯狂旋转,查询永远没有返回,最终neo4j浏览器显示已经与服务器失去连接。唯一结束查询的方法是停止服务器。所以我改变了查询为较简单的:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
RETURN theCard,
CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList,
before, btc, tca, after,
listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
我仍然陷入了一个无限循环或者类似的情况...所以我猜这一行代码
CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList不是一个好主意...你有任何其他建议吗?我走错了方向吗?
一个解决方案?
经过大量研究,我终于找到了一种编写单个查询解决所有可能情况的方法。我不知道这是否是实现我想要实现的最佳方式,但它对我来说似乎既优雅又紧凑。你觉得呢?
// first let's get a hold of the card we want to archive
MATCH (theCard:Card) WHERE ID(theCard)=44
// next, let's get a hold of the correspondent archive list node, since we need to move the card in that list
OPTIONAL MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD*]-(theList:List)<-[:NEXT_LIST|HEAD_LIST*]-(theProject:Project)-[:ARCHIVE_LIST]->(theArchive:List)
// let's check if we are in the case where the card to be archived is in the middle of a list
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (next:Card)-[ntc:PREV_CARD]->(theCard:Card)-[tcp:PREV_CARD]->(previous:Card)
// let's check if the card to be archived is the only card in the list
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
// let's check if the card to be archived is at the head of the list
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)-[stc:PREV_CARD]->(theCard:Card)
// let's check if the card to be archived is at the tail of the list
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)-[ntltc:NEXT_CARD]->(theCard:Card)
WITH
theCard, theList, theProject, theArchive,
CASE WHEN theArchive IS NULL THEN [] ELSE [(theArchive)] END AS archives,
CASE WHEN before IS NULL THEN [] ELSE [(before)] END AS befores,
before, btc, tca, after,
CASE WHEN next IS NULL THEN [] ELSE [(next)] END AS nexts,
next, ntc, tcp, previous,
CASE WHEN listOfOne IS NULL THEN [] ELSE [(listOfOne)] END AS listsOfOne,
listOfOne, lootc, tcloo,
CASE WHEN listToHead IS NULL THEN [] ELSE [(listToHead)] END AS listsToHead,
listToHead, lthtc, tcs, second, stc,
CASE WHEN listToTail IS NULL THEN [] ELSE [(listToTail)] END AS listsToTail,
listToTail, ltttc, tcntl, nextToLast, ntltc
// let's handle the case in which the archived card was in the middle of a list
FOREACH (value IN befores |
CREATE (before)-[:NEXT_CARD]->(after)
CREATE (after)-[:PREV_CARD]->(before)
DELETE btc, tca)
FOREACH (value IN nexts | DELETE ntc, tcp)
// let's handle the case in which the archived card was the one and only card in the list
FOREACH (value IN listsOfOne |
CREATE (listOfOne)-[:HEAD_CARD]->(listOfOne)
CREATE (listOfOne)-[:TAIL_CARD]->(listOfOne)
DELETE lootc, tcloo)
// let's handle the case in which the archived card was at the head of the list
FOREACH (value IN listsToHead |
CREATE (listToHead)-[:HEAD_CARD]->(second)
DELETE lthtc, tcs, stc)
// let's handle the case in which the archived card was at the tail of the list
FOREACH (value IN listsToTail |
CREATE (listToTail)-[:TAIL_CARD]->(nextToLast)
DELETE ltttc, tcntl, ntltc)
// finally, let's move the card in the archive
// first get a hold of the archive list to which we want to add the card
WITH
theCard,
theArchive
// first get a hold of the list to which we want to add the new card
OPTIONAL MATCH (theArchive)-[tact:TAIL_CARD]->(currentTail:Card)
// check if the list is empty
OPTIONAL MATCH (theArchive)-[tata1:TAIL_CARD]->(theArchive)-[tata2:HEAD_CARD]->(theArchive)
WITH
theArchive, theCard,
CASE WHEN currentTail IS NULL THEN [] ELSE [(currentTail)] END AS currentTails,
currentTail, tact,
CASE WHEN tata1 IS NULL THEN [] ELSE [(theArchive)] END AS emptyLists,
tata1, tata2
// handle the case in which the list already had at least one card
FOREACH (value IN currentTails |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theCard)-[:PREV_CARD]->(currentTail)
CREATE (currentTail)-[:NEXT_CARD]->(theCard)
DELETE tact)
// handle the case in which the list was empty
FOREACH (value IN emptyLists |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theArchive)-[:HEAD_CARD]->(theCard)
DELETE tata1, tata2)
RETURN theCard
最后编辑时间
根据Wes的建议,我决定改变应用程序中每个队列的处理方式,添加两个额外的节点,即头部和尾部。
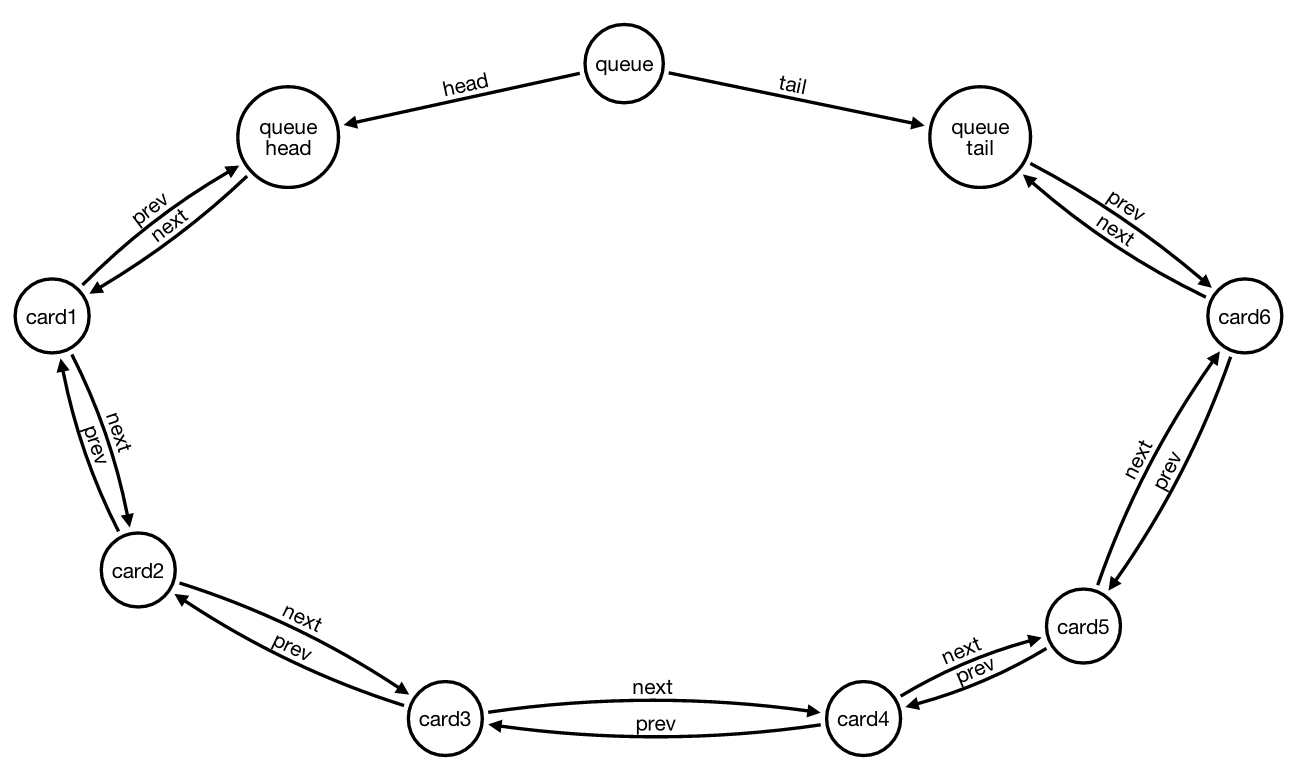
插入新卡片
将“头”和“尾”的概念从简单的关系移动到节点,可以在插入新卡片时只有一个情况。即使是空队列的特殊情况...
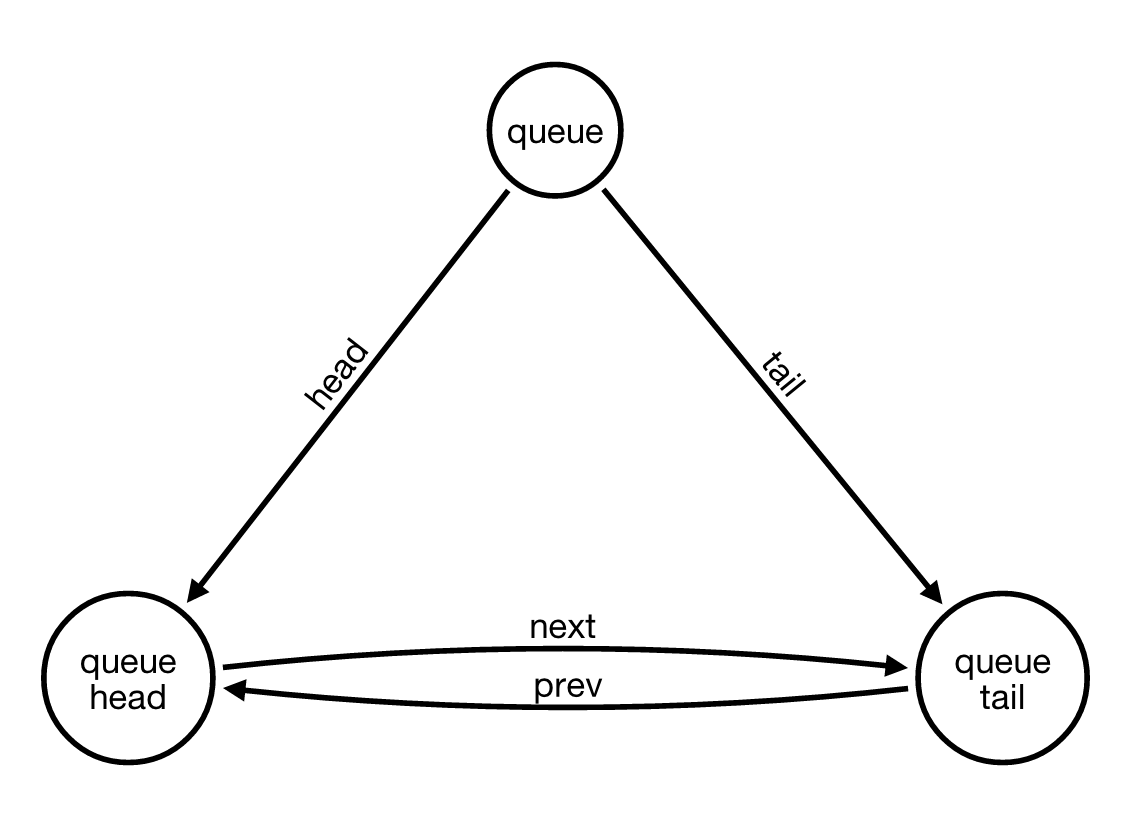
如果我们想在队列的尾部添加一个新卡片,需要执行以下步骤:
- 找到由[PREV_CARD]和[NEXT_CARD]关系连接到队列尾节点的(上一个)节点
- 创建一个(newCard)节点
- 用[PREV_CARD]和[NEXT_CARD]关系将(newCard)节点连接到(tail)节点
- 用[PREV_CARD]和[NEXT_CARD]关系将(newCard)节点连接到(previous)节点
- 最后删除连接(上一个)节点与队列尾节点之间的原始[PREV_CARD]和[NEXT_CARD]关系
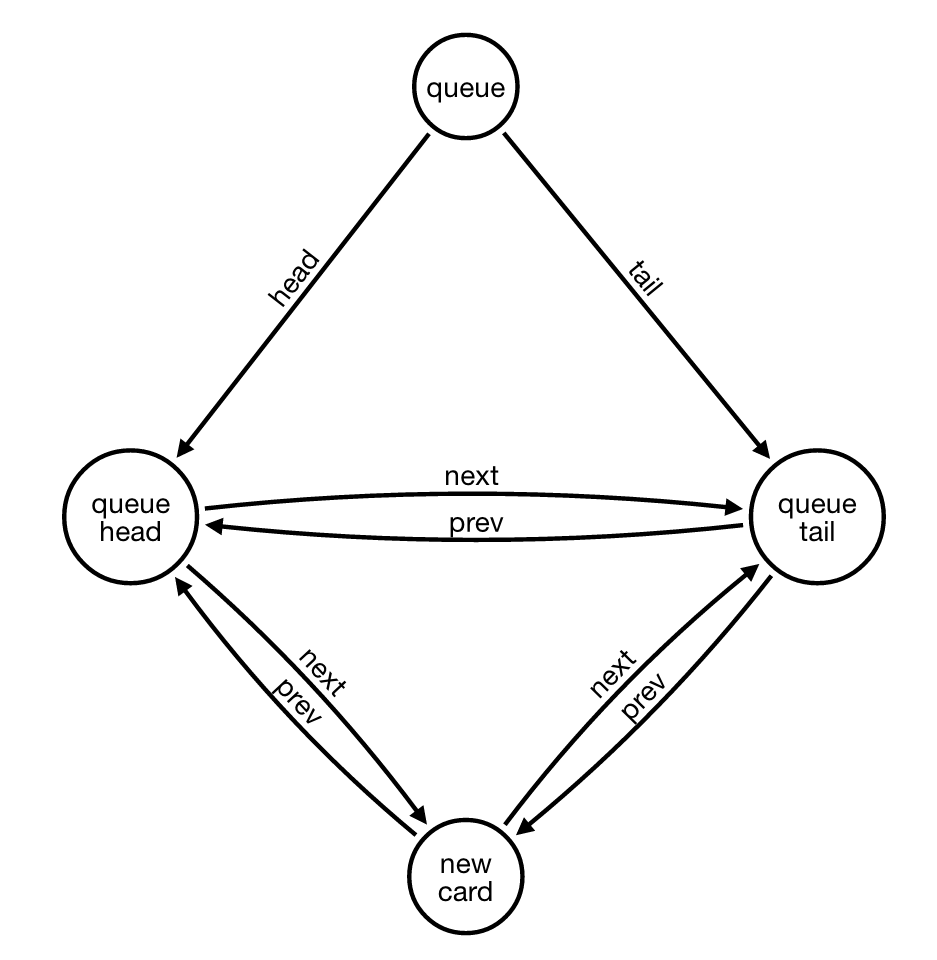
这转化为以下密码查询:
MATCH (theList:List)-[tlt:TAIL_CARD]->(tail)-[tp:PREV_CARD]->(previous)-[pt:NEXT_CARD]->(tail)
WHERE ID(theList)={{listId}}
WITH theList, tail, tp, pt, previous
CREATE (newCard:Card { title: "Card Title", description: "" })
CREATE (tail)-[:PREV_CARD]->(newCard)-[:NEXT_CARD]->(tail)
CREATE (newCard)-[:PREV_CARD]->(previous)-[:NEXT_CARD]->(newCard)
DELETE tp,pt
RETURN newCard
归档卡片
现在让我们重新考虑需要归档卡片的使用情况。让我们回顾一下架构:
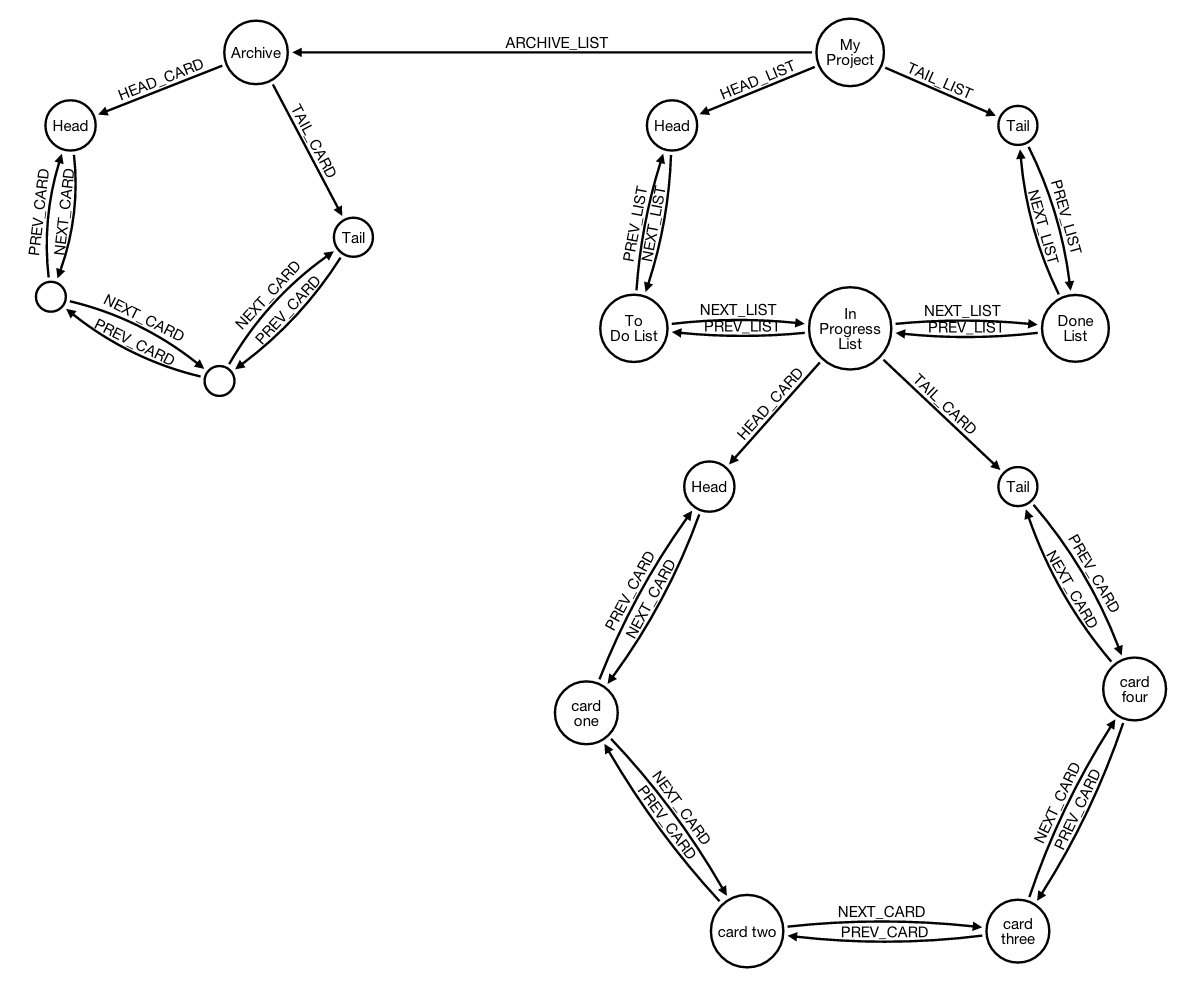
我们有:
- 每个项目都有一个列表队列
- 每个项目都有一个存档队列,用于存储所有已归档的卡片
- 每个列表都有一个卡片队列
在以前的队列架构中,我有4种不同的情况,具体取决于要归档的卡片是头部、尾部、中间的卡片还是队列中剩下的最后一张卡片。
现在,随着头部和尾部节点的引入,只有一种情况,因为头部和尾部节点将一直存在,即使队列为空:
- 我们需要找到(theCard)节点之前和之后立即的(previous)和(next)节点,这是我们想要归档的节点
- 然后,我们需要使用[NEXT_CARD]和[PREV_CARD]关系将(previous)和(next)连接起来
- 然后,我们需要删除将(theCard)与(previous)和(next)节点连接的所有关系
MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD*]-(l:List)<-[:NEXT_LIST*]-(h)<-[:HEAD_LIST]-(p:Project)-[:ARCHIVE]->(theArchive:Archive)
WHERE ID(theCard)={{cardId}}
接下来,我们执行我之前描述的逻辑:
WITH theCard, theArchive
MATCH (previous)-[ptc:NEXT_CARD]->(theCard)-[tcn:NEXT_CARD]->(next)-[ntc:PREV_CARD]->(theCard)-[tcp:PREV_CARD]->(previous)
WITH theCard, theArchive, previous, next, ptc, tcn, ntc, tcp
CREATE (previous)-[:NEXT_CARD]->(next)-[:PREV_CARD]->(previous)
DELETE ptc, tcn, ntc, tcp
最后,我们将(theCard)插入到归档队列的尾部:
WITH theCard, theArchive
MATCH (theArchive)-[tat:TAIL_CARD]->(archiveTail)-[tp:PREV_CARD]->(archivePrevious)-[pt:NEXT_CARD]->(archiveTail)
WITH theCard, theArchive, archiveTail, tp, pt, archivePrevious
CREATE (archiveTail)-[:PREV_CARD]->(theCard)-[:NEXT_CARD]->(archiveTail)
CREATE (theCard)-[:PREV_CARD]->(archivePrevious)-[:NEXT_CARD]->(theCard)
DELETE tp,pt
RETURN theCard
我希望您会像我在完成这个练习时一样,对最后的修改感到有趣。我想再次感谢Wes通过Twitter和Stack Overflow远程提供的帮助,在这个(至少对我来说)有趣的实验中。