这是Windows下R语言的一个令人烦恼的“特性”。到目前为止,我找到的唯一解决方案是临时地通过编程将您的区域设置切换到所需的语言环境以解码相关文本。因此,在上述情况下,您需要使用日语环境。
str <- "ていただけるなら"
Encoding(str)
write.table(str, file="c:/chartest.txt", quote=F, col.names=F, row.names=F)
print(Sys.getlocale(category = "LC_CTYPE"))
original_ctype <- Sys.getlocale(category = "LC_CTYPE")
Sys.setlocale("LC_CTYPE","japanese")
write.table(str, "c:/chartest2.txt", quote = FALSE, col.names = FALSE,
row.names = FALSE, sep = "\t", fileEncoding = "UTF-8")
Sys.setlocale("LC_CTYPE", original_ctype)
上述操作会生成两个文件,如下截图所示。第一个文件显示的是Unicode代码点,而不是您想要的内容,而第二个文件则显示了通常所期望的字形。
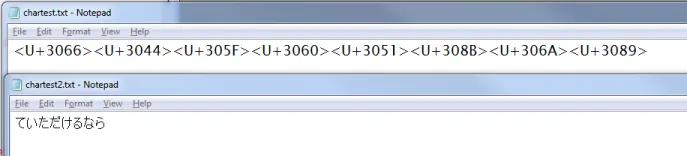
目前还没有人能够解释为什么R会出现这种情况。这不是Windows的不可避免特性,因为正如我在
这篇帖子中提到的那样,Perl以某种方式绕过了此问题。
writeLines(str, "chartest2.txt", useBytes=TRUE)- Montgomery Clift