CROSS APPLY 主要作用是什么?
我了解到,对于分区数据集的选择操作,使用
在大多数
请问有没有人能给出一个很好的例子,在这些情况下
我了解到,对于分区数据集的选择操作,使用
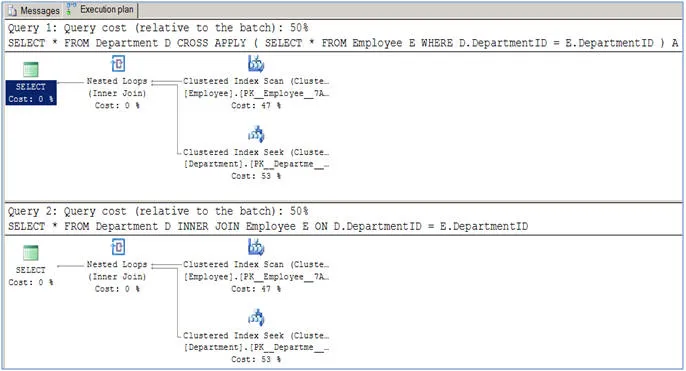
CROSS APPLY 可能会更有效率,尤其是在处理分页场景时。此外,CROSS APPLY 不需要右表为 UDF。在大多数
INNER JOIN 查询中(一对多关系),我可以重写成使用 CROSS APPLY,但它们总是给我等效的执行计划。请问有没有人能给出一个很好的例子,在这些情况下
CROSS APPLY 会产生不同于 INNER JOIN 且更高效的执行计划呢?create table Company (
companyId int identity(1,1)
, companyName varchar(100)
, zipcode varchar(10)
, constraint PK_Company primary key (companyId)
)
GO
create table Person (
personId int identity(1,1)
, personName varchar(100)
, companyId int
, constraint FK_Person_CompanyId foreign key (companyId) references dbo.Company(companyId)
, constraint PK_Person primary key (personId)
)
GO
insert Company
select 'ABC Company', '19808' union
select 'XYZ Company', '08534' union
select '123 Company', '10016'
insert Person
select 'Alan', 1 union
select 'Bobby', 1 union
select 'Chris', 1 union
select 'Xavier', 2 union
select 'Yoshi', 2 union
select 'Zambrano', 2 union
select 'Player 1', 3 union
select 'Player 2', 3 union
select 'Player 3', 3
/* using CROSS APPLY */
select *
from Person p
cross apply (
select *
from Company c
where p.companyid = c.companyId
) Czip
/* the equivalent query using INNER JOIN */
select *
from Person p
inner join Company c on p.companyid = c.companyId