内聚性和耦合度有何区别?
耦合度和内聚性如何影响软件设计的好坏?
可以举一些例子来说明它们之间的区别以及对代码质量的整体影响。
内聚性和耦合度有何区别?
耦合度和内聚性如何影响软件设计的好坏?
可以举一些例子来说明它们之间的区别以及对代码质量的整体影响。
内聚性(Cohesion)指的是一个类(或模块)可以做什么。低内聚性意味着该类执行多种操作,即它是广泛的,不专注于应该做什么。高内聚性意味着该类专注于应该做什么,即只包含与类意图相关的方法。
低内聚性的示例:
-------------------
| Staff |
-------------------
| checkEmail() |
| sendEmail() |
| emailValidate() |
| PrintLetter() |
-------------------
高内聚的例子:
----------------------------
| Staff |
----------------------------
| -salary |
| -emailAddr |
----------------------------
| setSalary(newSalary) |
| getSalary() |
| setEmailAddr(newEmail) |
| getEmailAddr() |
----------------------------
就耦合而言,它指的是两个类/模块之间相关或依赖性的程度。低耦合的类别,在一个类中做出重大改变不应该影响另一个类。高耦合会使更改和维护代码变得困难;因为类之间紧密相连,所以进行更改可能需要整个系统重新设计。
良好的软件设计具有高内聚性和低耦合度。
模块内高内聚,模块间低耦合常被认为与面向对象编程语言的高质量相关。
例如,每个Java类中的代码必须具有高内部内聚性,但与其他Java类中的代码松散耦合。
Meyer的面向对象软件构造(第二版)的第三章对这些问题进行了很好的描述。
内聚性(Cohesion)是软件元素的责任相关和重心集中程度的指示。
耦合度(Coupling)则指软件元素与其他元素连接的强度。
这些软件元素可以是类、包、组件、子系统或系统。在设计系统时,建议选择具有高内聚和支持低耦合的软件元素。
低内聚会导致大而松散的类,难以维护、理解和减少可重用性。同样,高耦合会导致紧密耦合的类,改动可能不局限于本地,难以更改并减少重用。
我们可以使用一个虚构的场景来说明,我们正在设计一个可监视的ConnectionPool,其需求如下所示。请注意,对于像ConnectionPool这样的简单类来说,这似乎太多了,但基本意图只是通过一些简单的例子演示低耦合和高内聚,我认为这应该有所帮助。
使用低内聚性,我们可以通过将所有这些功能/责任强制塞入单个类中来设计ConnectionPool类,如下所示。我们可以看到,这个单一类负责连接管理、与数据库交互以及维护连接统计信息。

使用高内聚性,我们可以将这些责任分配到不同的类中,使其更易于维护和重复使用。
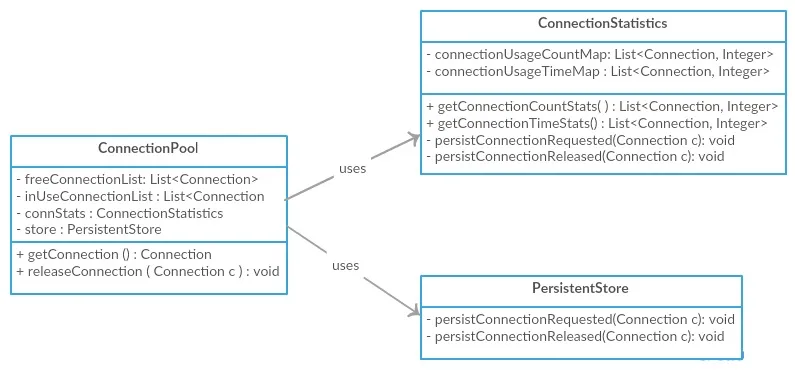
为了展示低耦合,我们将继续使用上面的高内聚ConnectionPool图。如果我们看一下上面的图表,虽然它支持高内聚,但是ConnectionPool与ConnectionStatistics类和PersistentStore紧密耦合,直接与它们交互。为了减少耦合,我们可以引入一个ConnectionListener接口,并让这两个类实现该接口,并让它们在ConnectionPool类中注册。然后ConnectionPool将遍历这些监听器并通知它们连接获取和释放事件,从而实现更少的耦合。
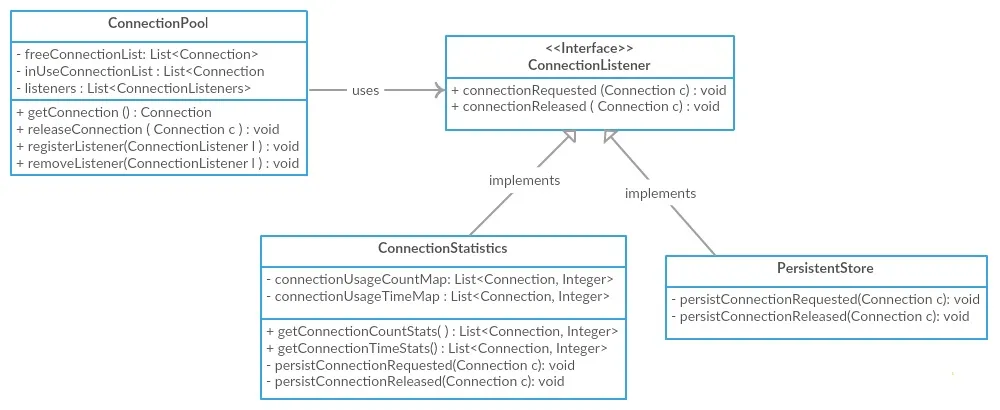
注意/警告:对于这种简单的情况,看起来可能有点过度设计,但是如果我们想象一个实时场景,其中我们的应用程序需要与多个第三方服务交互以完成事务:直接将我们的代码与第三方服务耦合在一起意味着任何第三方服务的更改都可能导致我们的代码在多个地方发生更改,而不是这样,我们可以有一个Facade,它在内部与这些多个服务进行交互,并且对服务的任何更改都将局限于Facade中,并强制实现与第三方服务的低耦合。
简单来说,内聚度表示代码库中的某个部分是否形成逻辑上的单一、原子单位。而耦合度则表示一个单元对其他单元的依赖程度。换句话说,它是两个或多个单元之间连接的数量。连接数越少,耦合度就越低。
本质上,高内聚意味着将相互关联的代码部分放在一个地方。同时,低耦合是指尽可能地将不相关的代码部分分开。
从内聚度和耦合度的角度来看,代码有以下类型:
理想的代码遵循这些准则。它松散耦合且高度内聚。我们可以用这张图片来说明这种代码: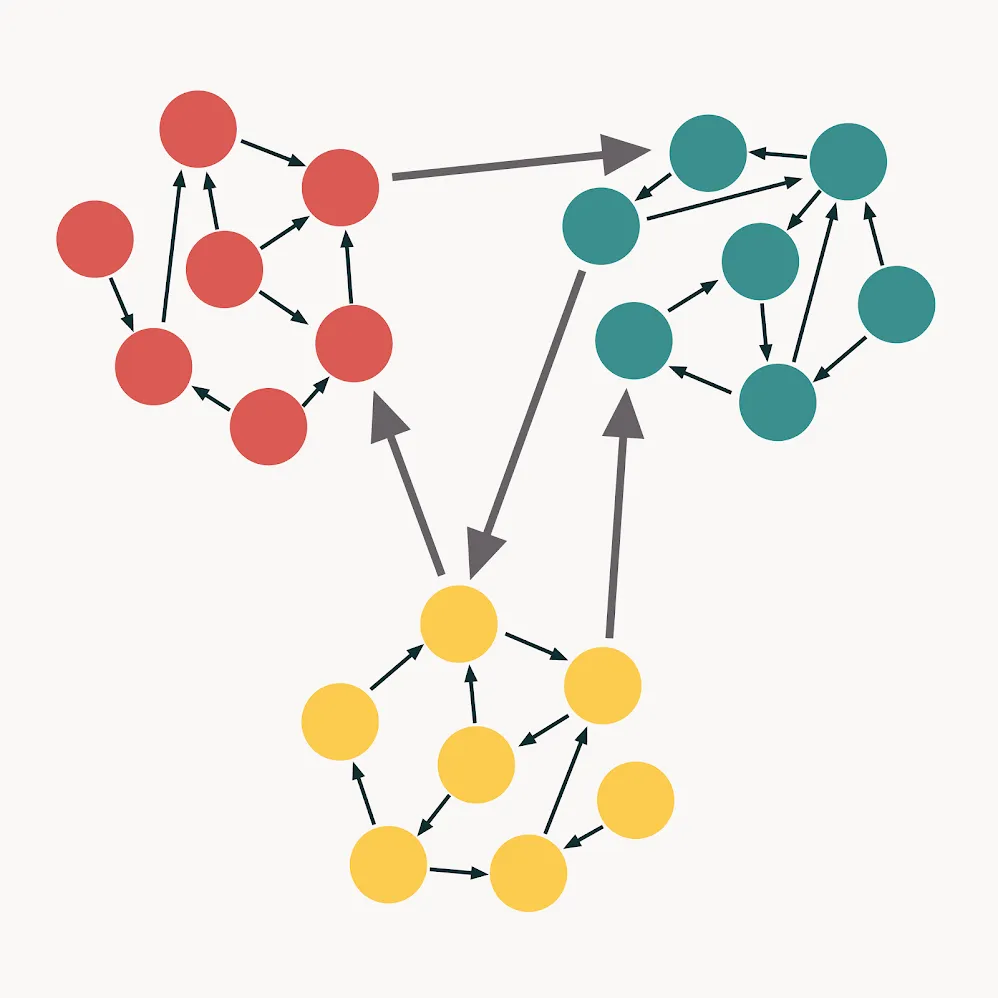
万能对象是高内聚和高耦合的结果。它是反模式,基本上是指一段代码同时完成所有工作:

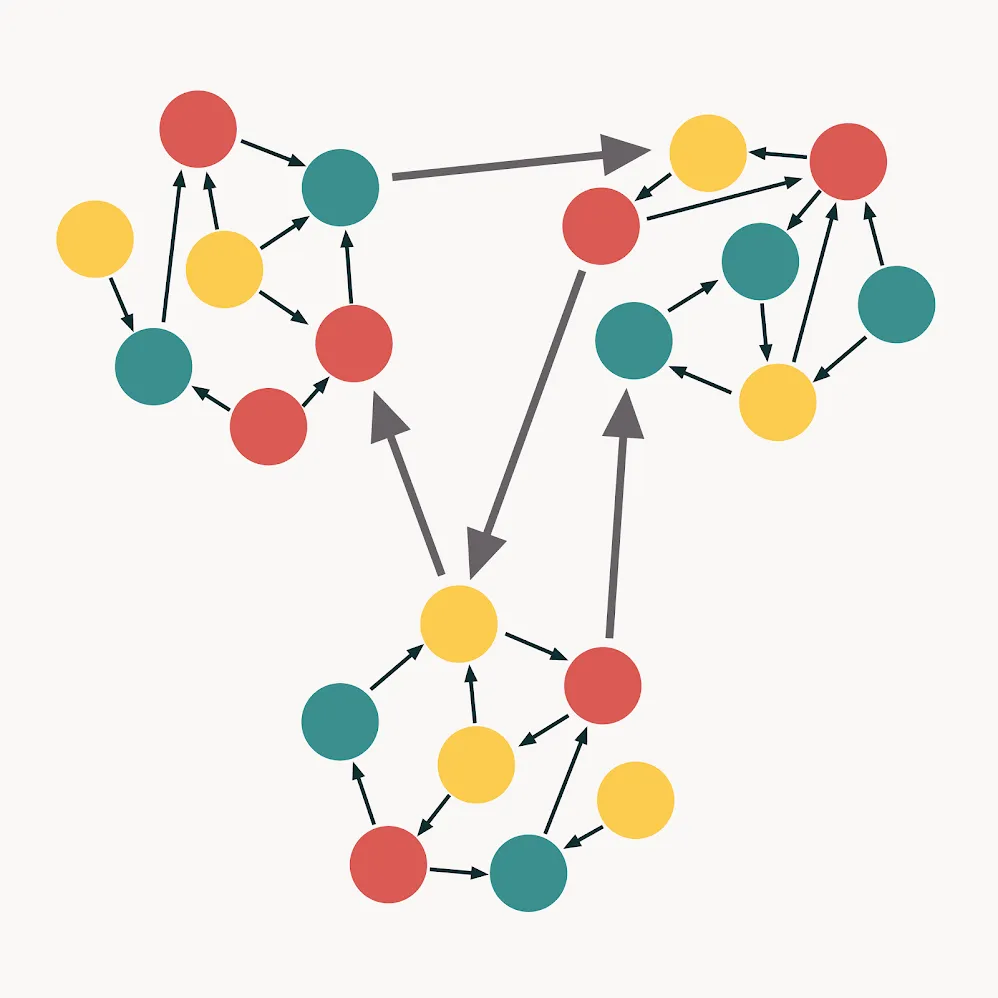
破坏性解耦是最有趣的一种情况。它有时会在程序员试图过度解耦代码库以至于代码完全失去焦点时发生:
在这里了解更多信息。
增强内聚性和减少耦合确实会导致良好的软件设计。
内聚性将您的功能划分为紧凑的部分,并使其最接近与其相关的数据,而解耦确保功能实现与系统的其余部分隔离。
解耦允许您更改实现而不影响软件的其他部分。
内聚性确保实现更加专注于功能,并且同时更易于维护。
减少耦合并增加内聚性的最有效方法是通过接口进行设计。
也就是说,主要的功能对象只能通过它们实现的接口之间'了解'彼此。
接口的实现自然地引入了内聚性。
虽然在某些场景中不太现实,但应该把这作为设计目标来工作。
示例(非常简略):
public interface IStackoverFlowQuestion
void SetAnswered(IUserProfile user);
void VoteUp(IUserProfile user);
void VoteDown(IUserProfile user);
}
public class NormalQuestion implements IStackoverflowQuestion {
protected Integer vote_ = new Integer(0);
protected IUserProfile user_ = null;
protected IUserProfile answered_ = null;
public void VoteUp(IUserProfile user) {
vote_++;
// code to ... add to user profile
}
public void VoteDown(IUserProfile user) {
decrement and update profile
}
public SetAnswered(IUserProfile answer) {
answered_ = answer
// update u
}
}
public class CommunityWikiQuestion implements IStackoverflowQuestion {
public void VoteUp(IUserProfile user) { // do not update profile }
public void VoteDown(IUserProfile user) { // do not update profile }
public void SetAnswered(IUserProfile user) { // do not update profile }
}
在你的代码库中的其他地方,可能会有一个模块来处理问题,不论这些问题是什么:
public class OtherModuleProcessor {
public void Process(List<IStackoverflowQuestion> questions) {
... process each question.
}
}
内聚性在软件工程中是指一个模块的元素彼此之间关联程度的度量。因此,它是通过软件模块源代码表达的每个功能块之间相关性的度量。
耦合性简而言之,是一个组件(再想象一下一个类,虽然不一定)对另一个组件的内部工作或内部元素了解程度的度量,即它对另一个组件的了解程度。
我在博客中写了一篇文章,如果您想详细了解一些例子和图示,请阅读该文章。我认为它能回答你大部分的问题。
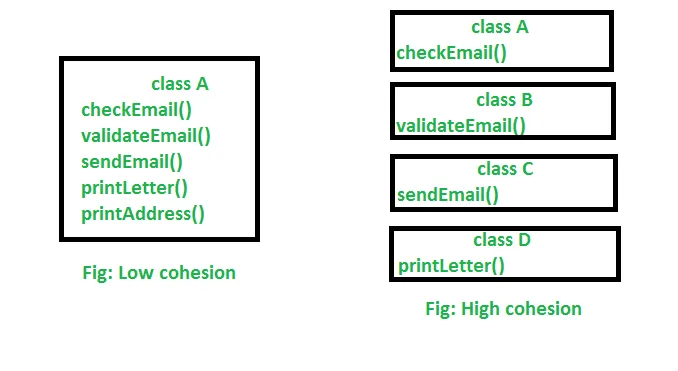
内聚是指单个类的设计如何。内聚是面向对象的原则中与确保一个类具有单一、明确目的最密切相关的原则。
一个类的内聚性越强,它就越专注于特定目标。高内聚度的优点是这样的类比低内聚度的类更容易维护(并且不需要频繁地更改)。另一个好处是,具有明确目的的类往往比其他类更容易重用。
在上图中,我们可以看到,在低内聚度中,只有一个类负责执行许多不常见的任务,这降低了重用和维护的机会。但在高内聚度中,每个任务都有一个独立的类来执行特定的任务,从而实现更好的可用性和维护性。
传统观点:
模块的“专一性”
面向对象的观点:
内聚意味着组件或类仅封装与其自身及其彼此紧密相关的属性和操作。
内聚性级别
功能性
层次结构
通信
顺序
过程
时间
实用
耦合性取决于模块之间的接口复杂性、对模块进行入口或引用的位置以及跨接口传输的数据。
传统观点:
组件与其他组件及外部世界之间的连接程度
面向对象的观点:
类相互连接的定性度量
耦合性级别
内容耦合
公共耦合
控制耦合
标记耦合
数据耦合
例程调用
类型使用
包含或导入
外部 #
