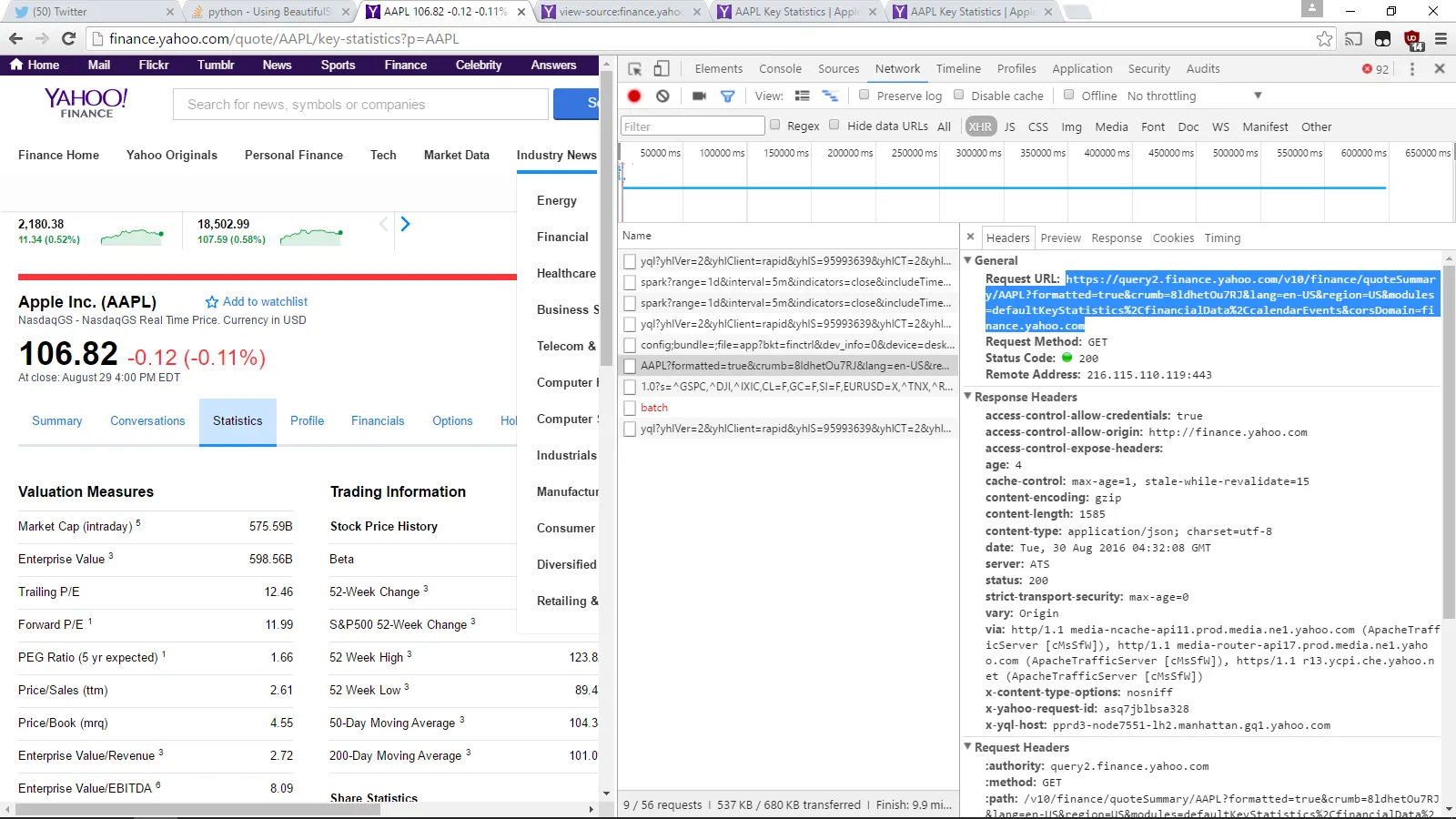
我正在尝试从Yahoo的“关键统计”页面中获取股票代码的信息(因为Pandas库不支持此功能)。
AAPL的示例:
from bs4 import BeautifulSoup
import requests
url = 'http://finance.yahoo.com/quote/AAPL/key-statistics?p=AAPL'
page = requests.get(url)
soup = BeautifulSoup(page.text, 'lxml')
enterpriseValue = soup.findAll('$ENTERPRISE_VALUE', attrs={'class': 'yfnc_tablehead1'}) #HTML tag for where enterprise value is located
print(enterpriseValue)
编辑:谢谢Andy!
问题:这将打印一个空数组。如何更改我的findAll以返回598.56B?