我使用此处指定的代码合并了两个Excel文件。
一切都按预期运行,生成我的XSSFWorkbook时进展顺利。
当我尝试打开它时出现问题:
我看到以下错误。
http://www.coderanch.com/t/614715/Web-Services/java/merge-excel-files
这是应用于合并单元格的样式块
if (styleMap != null)
{
if (oldCell.getSheet().getWorkbook() == newCell.getSheet().getWorkbook())
{
newCell.setCellStyle(oldCell.getCellStyle());
}
else
{
int stHashCode = oldCell.getCellStyle().hashCode();
XSSFCellStyle newCellStyle = styleMap.get(stHashCode);
if (newCellStyle == null)
{
newCellStyle = newCell.getSheet().getWorkbook().createCellStyle();
newCellStyle.cloneStyleFrom(oldCell.getCellStyle());
styleMap.put(stHashCode, newCellStyle);
}
newCell.setCellStyle(newCellStyle);
}
}
一切都按预期运行,生成我的XSSFWorkbook时进展顺利。
当我尝试打开它时出现问题:
我看到以下错误。

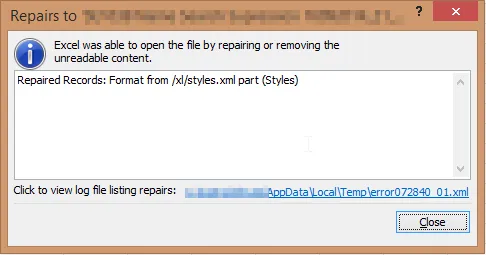
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<recoveryLog xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
<logFileName>error072840_01.xml</logFileName>
<summary>Errors were detected in file 'XYZ.xlsx'</summary>
<repairedRecords summary="Following is a list of repairs:">
<repairedRecord>Repaired Records: Format from /xl/styles.xml part (Styles)</repairedRecord>
</repairedRecords>
</recoveryLog>
经过这一切,我的表格打开得很好,但没有样式。我知道有一个创建样式数量的限制,并且已经计算了被创建的样式数量,我几乎只看到了4个被创建。我甚至知道这个问题是由于太多的样式引起的。
不幸的是,POI仅支持优化HSSFWorkbook(Apache POI删除工作簿中的CellStyle)
如果有任何帮助来缓解这个问题将是很棒的。