实际上,自从C++11以来,在大多数情况下,复制std::vector的成本已经消失。
然而,应该记住,构造新向量(然后销毁它)的成本仍然存在,并且在希望重复使用向量容量时,使用输出参数而不是按值返回仍然很有用。这在C ++核心指南的F.20中被记录为一种例外情况。
让我们比较一下:
std::vector<int> BuildLargeVector1(size_t vecSize) {
return std::vector<int>(vecSize, 1);
}
使用:
void BuildLargeVector2( std::vector<int>& v, size_t vecSize) {
v.assign(vecSize, 1);
}
现在,假设我们需要在一个紧密的循环中调用这些方法
numIter次,并执行一些操作。例如,让我们计算所有元素的总和。
使用
BuildLargeVector1,您将执行以下操作:
size_t sum1 = 0;
for (int i = 0; i < numIter; ++i) {
std::vector<int> v = BuildLargeVector1(vecSize);
sum1 = std::accumulate(v.begin(), v.end(), sum1);
}
使用
BuildLargeVector2,您需要执行以下操作:
size_t sum2 = 0;
std::vector<int> v;
for (int i = 0; i < numIter; ++i) {
BuildLargeVector2( v, vecSize);
sum2 = std::accumulate(v.begin(), v.end(), sum2);
}
在第一个例子中,发生了许多不必要的动态分配/释放,而在第二个例子中通过使用旧的方式输出参数,可以重复使用已经分配的内存来防止这种情况。是否值得进行此优化取决于分配/释放与计算/变异值的相对成本。
基准测试
让我们玩一下
vecSize和
numIter的值。我们将保持vecSize*numIter不变,以便“理论上”,它应该花费相同的时间(=有相同数量的赋值和加法,具有完全相同的值),时间差只能来自于分配、释放和更好地使用缓存的成本。
更具体地说,让我们使用vecSize*numIter = 2^31 = 2147483648,因为我有16GB的RAM,并且这个数字确保不会分配超过8GB(sizeof(int) = 4),从而确保我没有交换到磁盘(所有其他程序都已关闭,运行测试时我有大约15GB可用)。
以下是代码:
#include <chrono>
#include <iomanip>
#include <iostream>
#include <numeric>
#include <vector>
class Timer {
using clock = std::chrono::steady_clock;
using seconds = std::chrono::duration<double>;
clock::time_point t_;
public:
void tic() { t_ = clock::now(); }
double toc() const { return seconds(clock::now() - t_).count(); }
};
std::vector<int> BuildLargeVector1(size_t vecSize) {
return std::vector<int>(vecSize, 1);
}
void BuildLargeVector2( std::vector<int>& v, size_t vecSize) {
v.assign(vecSize, 1);
}
int main() {
Timer t;
size_t vecSize = size_t(1) << 31;
size_t numIter = 1;
std::cout << std::setw(10) << "vecSize" << ", "
<< std::setw(10) << "numIter" << ", "
<< std::setw(10) << "time1" << ", "
<< std::setw(10) << "time2" << ", "
<< std::setw(10) << "sum1" << ", "
<< std::setw(10) << "sum2" << "\n";
while (vecSize > 0) {
t.tic();
size_t sum1 = 0;
{
for (int i = 0; i < numIter; ++i) {
std::vector<int> v = BuildLargeVector1(vecSize);
sum1 = std::accumulate(v.begin(), v.end(), sum1);
}
}
double time1 = t.toc();
t.tic();
size_t sum2 = 0;
{
std::vector<int> v;
for (int i = 0; i < numIter; ++i) {
BuildLargeVector2( v, vecSize);
sum2 = std::accumulate(v.begin(), v.end(), sum2);
}
}
double time2 = t.toc();
std::cout << std::setw(10) << vecSize << ", "
<< std::setw(10) << numIter << ", "
<< std::setw(10) << std::fixed << time1 << ", "
<< std::setw(10) << std::fixed << time2 << ", "
<< std::setw(10) << sum1 << ", "
<< std::setw(10) << sum2 << "\n";
vecSize /= 2;
numIter *= 2;
}
return 0;
}
这是结果:
$ g++ -std=c++11 -O3 main.cpp && ./a.out
vecSize, numIter, time1, time2, sum1, sum2
2147483648, 1, 2.360384, 2.356355, 2147483648, 2147483648
1073741824, 2, 2.365807, 1.732609, 2147483648, 2147483648
536870912, 4, 2.373231, 1.420104, 2147483648, 2147483648
268435456, 8, 2.383480, 1.261789, 2147483648, 2147483648
134217728, 16, 2.395904, 1.179340, 2147483648, 2147483648
67108864, 32, 2.408513, 1.131662, 2147483648, 2147483648
33554432, 64, 2.416114, 1.097719, 2147483648, 2147483648
16777216, 128, 2.431061, 1.060238, 2147483648, 2147483648
8388608, 256, 2.448200, 0.998743, 2147483648, 2147483648
4194304, 512, 0.884540, 0.875196, 2147483648, 2147483648
2097152, 1024, 0.712911, 0.716124, 2147483648, 2147483648
1048576, 2048, 0.552157, 0.603028, 2147483648, 2147483648
524288, 4096, 0.549749, 0.602881, 2147483648, 2147483648
262144, 8192, 0.547767, 0.604248, 2147483648, 2147483648
131072, 16384, 0.537548, 0.603802, 2147483648, 2147483648
65536, 32768, 0.524037, 0.600768, 2147483648, 2147483648
32768, 65536, 0.526727, 0.598521, 2147483648, 2147483648
16384, 131072, 0.515227, 0.599254, 2147483648, 2147483648
8192, 262144, 0.540541, 0.600642, 2147483648, 2147483648
4096, 524288, 0.495638, 0.603396, 2147483648, 2147483648
2048, 1048576, 0.512905, 0.609594, 2147483648, 2147483648
1024, 2097152, 0.548257, 0.622393, 2147483648, 2147483648
512, 4194304, 0.616906, 0.647442, 2147483648, 2147483648
256, 8388608, 0.571628, 0.629563, 2147483648, 2147483648
128, 16777216, 0.846666, 0.657051, 2147483648, 2147483648
64, 33554432, 0.853286, 0.724897, 2147483648, 2147483648
32, 67108864, 1.232520, 0.851337, 2147483648, 2147483648
16, 134217728, 1.982755, 1.079628, 2147483648, 2147483648
8, 268435456, 3.483588, 1.673199, 2147483648, 2147483648
4, 536870912, 5.724022, 2.150334, 2147483648, 2147483648
2, 1073741824, 10.285453, 3.583777, 2147483648, 2147483648
1, 2147483648, 20.552860, 6.214054, 2147483648, 2147483648
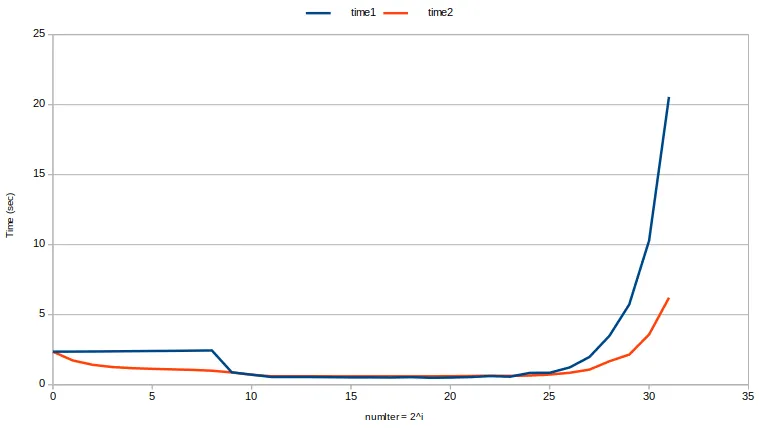
(Intel i7-7700K @ 4.20GHz; 16GB DDR4 2400Mhz; Kubuntu 18.04)
注:mem(v) = v.size() * sizeof(int) = v.size() * 4 在我的平台上。
不出所料,当 numIter = 1(即 mem(v) = 8GB)时,时间完全相同。事实上,在这两种情况下,我们都只分配了一次巨大的8GB内存向量。这也证明在使用BuildLargeVector1()时没有发生复制:我没有足够的RAM来进行复制!
当 numIter = 2 时,重用向量容量而不是重新分配第二个向量要快1.37倍。
当 numIter = 256 时,重用向量容量(而不是反复分配/释放256次向量…)要快2.45倍 :)
我们可以注意到,从 numIter = 1 到 numIter = 256,time1几乎是恒定的,这意味着分配一个8GB的巨大向量与分配256个32MB的向量成本几乎相同。然而,分配一个8GB的巨大向量肯定比分配一个32MB的向量更昂贵,因此重用向量的容量提供了性能增益。
从
numIter = 512(mem(v)= 16MB)到
numIter = 8M(mem(v)= 1kB)是最佳的选择:两种方法的速度完全相同,并且比所有其他numIter和vecSize组合更快。这可能与我的处理器的L3缓存大小为8MB有关,因此向量几乎完全适合缓存。我没有真正解释为什么
time1的突然跳跃是在mem(v)= 16MB时,似乎更合理的是在mem(v)= 8MB之后发生。请注意,令人惊讶的是,在这个最佳状态下,不重复使用容量实际上略微更快!我没有真正解释这一点。
当
numIter> 8M时,情况开始变得丑陋。两种方法都变慢,但通过值返回向量变得更慢。在最坏的情况下,仅包含一个单独的
int的向量,重用容量而不是按值返回,速度要快3.3倍。这可能是由于malloc()的固定成本开始占主导地位。
请注意,time2的曲线比time1的曲线更平滑:不仅重新使用向量容量通常更快,而且更重要的是,它更可预测。
请注意,在优化点上,我们能够在约0.5秒内执行20亿次64位整数的加法,在4.2Ghz 64位处理器上是相当理想的。通过并行计算以使用所有8个核心,我们可以做得更好(上面的测试一次只使用一个核心,我通过重新运行测试并监视CPU使用情况进行了验证)。当 mem(v) = 16kB 时,即L1缓存的数量级(i7-7700K的L1数据缓存为4x32kB)获得最佳性能。
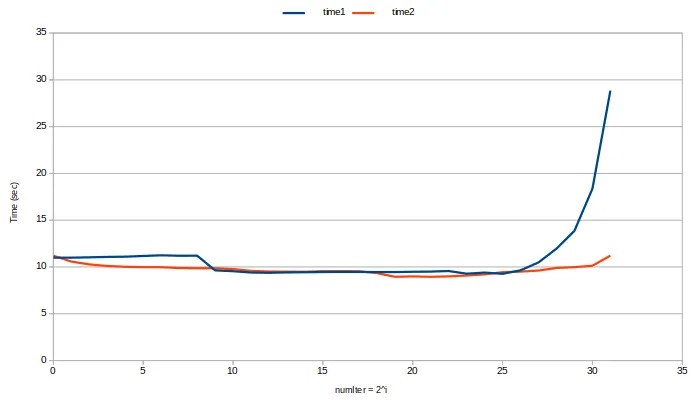
当你需要对数据进行更多的计算时,这些差异变得越来越不相关。如果我们将
sum = std::accumulate(v.begin(), v.end(), sum);替换为
for (int k : v) sum += std::sqrt(2.0*k);,则以下是结果:
结论
- 使用输出参数而不是通过值返回可能通过重复使用容量提供性能收益。
- 在现代台式电脑上,这似乎只适用于大型向量(>16MB)和小型向量(<1kB)。
- 避免分配数百万/数十亿个小向量(<1kB)。如果可能的话,请重复使用容量,或者更好的是,以不同的架构设计您的体系结构。
在其他平台上,结果可能有所不同。通常情况下,如果性能很重要,请为您特定的用例编写基准测试。