vhaddps指令以一种非常特殊的方式进行加法操作:
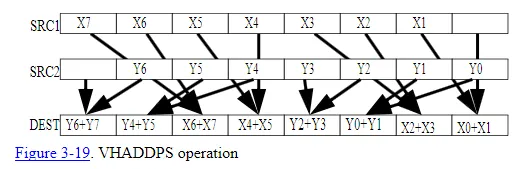
vhaddps指令以一种非常特殊的方式进行加法操作:
vhaddps ymm ymm ymm 的上128位只是复制粘贴了128位宽的vhaddps xmm xmm xmm指令。以下示例表明以这种方式定义vhaddps xmm xmm xmm是有意义的:使用此指令两次可获得4个xmm寄存器的水平总和。"最初的回答"/* gcc -m64 -O3 hadd_ex.c -march=sandybridge */
#include<immintrin.h>
#include<stdio.h>
int main(){
float tmp[4];
__m128 a = _mm_set_ps(1.0, 2.0, 3.0, 4.0);
__m128 b = _mm_set_ps(10.0, 20.0, 30.0, 40.0);
__m128 c = _mm_set_ps(100.0, 200.0, 300.0, 400.0);
__m128 d = _mm_set_ps(1000.0, 2000.0, 3000.0, 4000.0);
__m128 sum1 = _mm_hadd_ps(a, b);
__m128 sum2 = _mm_hadd_ps(c, d);
__m128 sum = _mm_hadd_ps(sum1, sum2);
_mm_storeu_ps(tmp,sum);
printf("sum = %f %f %f %f\n", tmp[0], tmp[1], tmp[2], tmp[3]);
return 0;
}
输出:
sum = 10.000000 100.000000 1000.000000 10000.000000
vhaddps zmm)仍在通道内。另请参见在AVX512中进行128位跨通道操作是否会提高性能?
AVX2的一系列vpack*通常需要使用vpermq来进行通道交错修复,除非您打算再次在通道内进行解包。因此,在大多数情况下,两个通道内洗牌比一个完整的256位宽度操作更差,但这并不是我们从AVX得到的。即使需要额外的洗牌来纠正通道内行为,从128位向量转换为256位向量通常仍然可以加速,但这通常意味着即使没有内存瓶颈,它也不是2倍加速。(v)haddps的使用情况非常有限也许英特尔计划在引入SSE3之后的某个时候将haddps变为单一uop指令,但这从未发生。
使用案例包括转置和添加类型的操作,其中您需要对垂直addps的两个输入进行重排。例如: 8个源__m256向量的水平总和最有效的方法包括vhaddps。(另外还需要AVX1 vperm2f128来纠正车道内行为。)
(v)haddps 都是好的选择,但实际上它们都需要2个洗牌操作来准备输入向量以进行竖直的 (v)addps 操作。对于水平求和,每个加法只需要1个洗牌操作。(参见x86 上执行浮点向量水平求和的最快方法)