我正在使用ftplib在Python中下载文件,直到最近一切似乎都很顺利。我是这样下载文件的:
ftpSession = ftplib.FTP(host,username,password)
ftpSession.cwd('rlmfiles')
ftpFileList = filter(lambda x: 'PEDI' in x, ftpSession.nlst())
ftpFileList.sort()
for f in ftpFileList:
tempFile = open(os.path.join(localDirectory,f),'wb')
ftpSession.retrbinary('RETR '+f,tempFile.write)
tempFile.close()
ftpSession.quit()
sys.exit(0)
最近我需要下载一些文件,一开始下载得很好,跟预期一样。但现在,我下载的文件都是损坏的,只包含了一长串垃圾ASCII码。我知道这不是文件上传到FTP上的问题,因为我还有一个Perl脚本也从同一个FTP上成功地下载了这些文件。
如果还需要其他信息,下面是调试器在命令提示符中下载文件时输出的内容:
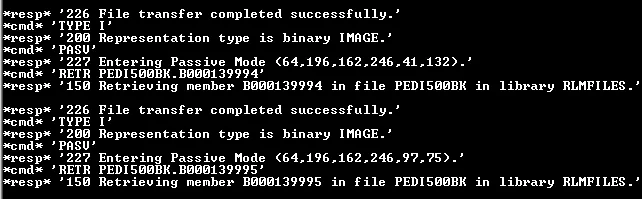
有没有人在使用Python的ftplib库中的retrbinary()函数下载文件时遇到过文件内容损坏的问题?
我真的卡住了/感到沮丧,没有找到任何与可能的损坏相关的信息。谢谢帮忙。