我要如何获得以下用黄色突出显示的结果?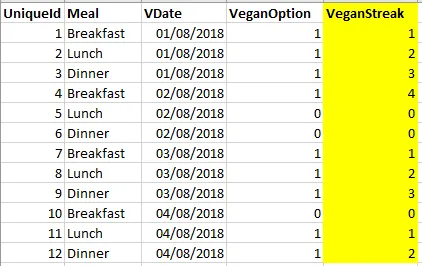
本质上,我想要一个计算字段,在VeganOption = 1时递增1,在VeganOption = 0时为零。
我尝试使用以下查询,但使用分区后继续在零之后递增。对此我有点困惑。
SELECT [UniqueId]
,[Meal]
,[VDate]
,[VeganOption]
, row_number() over (partition by [VeganOption] order by [UniqueId])
FROM [Control]
order by [UniqueId]
表格数据:
CREATE TABLE Control
([UniqueId] int, [Meal] varchar(10), [VDate] datetime, [VeganOption] int);
INSERT INTO Control ([UniqueId], [Meal], [VDate], [VeganOption])
VALUES
('1', 'Breakfast',' 2018-08-01 00:00:00', 1),
('2', 'Lunch',' 2018-08-01 00:00:00', 1),
('3', 'Dinner',' 2018-08-01 00:00:00', 1),
('4', 'Breakfast',' 2018-08-02 00:00:00', 1),
('5', 'Lunch',' 2018-08-02 00:00:00', 0),
('6', 'Dinner',' 2018-08-02 00:00:00', 0),
('7', 'Breakfast',' 2018-08-03 00:00:00', 1),
('8', 'Lunch',' 2018-08-03 00:00:00', 1),
('9', 'Dinner',' 2018-08-03 00:00:00', 1),
('10', 'Breakfast',' 2018-08-04 00:00:00', 0),
('11', 'Lunch',' 2018-08-04 00:00:00', 1),
('12', 'Dinner',' 2018-08-04 00:00:00', 1)
;
这适用于 SQL Server 2016 及以上版本
CREATE和INSERT语句。谢谢。 :) - Thom A