当我在查询中添加'distinct'时,查询时间从0.015秒增加到超过6秒。
我想要连接多个表格,这些表格通过外键链接,并从中获取一个不同的列:
select distinct table3.idtable3 from
table1
join table2 on table1.idtable1 = table2.fkey
join table3 on table2.idtable2 = table3.fkey
where table1.idtable1 = 1
这个distinct查询需要6秒的时间,我认为可以进行优化。
使用select语句:
持续时间: 0.015秒 / 获取:5.532秒 (5.760.434行)
解释:
id, select_type, table, partitions, type, possible_keys, key, key_len, ref, rows, filtered, Extra
1 SIMPLE table1 index asd asd 137 10 10.00 Using where; Using index
1 SIMPLE table2 ALL idtable2 200 25.00 Using where; Using join buffer (Block Nested Loop)
1 SIMPLE table3 ref fkey_table2_table_3_idx fkey_table2_table_3_idx 138 mydb.table2.idtable2 66641 100.00
使用distinct选择:
时长:6.625秒 / 获取时间:0.000秒(1000行)
说明:
id, select_type, table, partitions, type, possible_keys, key, key_len, ref, rows, filtered, Extra
1 SIMPLE table1 index asd asd 137 10 10.00 Using where; Using index; Using temporary
1 SIMPLE table2 ALL idtable2 200 25.00 Using where; Using join buffer (Block Nested Loop)
1 SIMPLE table3 ref fkey_table2_table_3_idx fkey_table2_table_3_idx 138 mydb.table2.idtable2 66641 100.00
数据库: 数据库片段
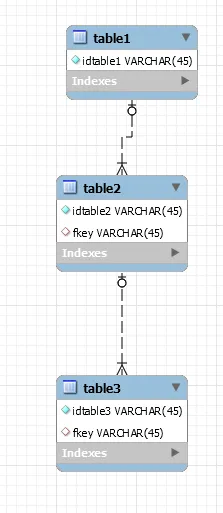{kind=link}
用于测试/ MCRE的代码:
import mysql.connector
import time
import numpy as np
"""
-- MySQL Script generated by MySQL Workbench
-- Fri Jan 17 12:19:26 2020
-- Model: New Model Version: 1.0
-- MySQL Workbench Forward Engineering
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0;
SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0;
SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
-- -----------------------------------------------------
-- Schema mydb
-- -----------------------------------------------------
-- -----------------------------------------------------
-- Schema mydb
-- -----------------------------------------------------
CREATE SCHEMA IF NOT EXISTS `mydb` DEFAULT CHARACTER SET utf8 ;
USE `mydb` ;
-- -----------------------------------------------------
-- Table `mydb`.`table1`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`table1` (
`idtable1` VARCHAR(45) NOT NULL,
INDEX `asd` (`idtable1` ASC) VISIBLE)
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`table2`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`table2` (
`idtable2` VARCHAR(45) NOT NULL,
`fkey` VARCHAR(45) NULL,
INDEX `link_table1_table2_idx` (`fkey` ASC) INVISIBLE,
INDEX `idtable2` (`idtable2` ASC) VISIBLE,
CONSTRAINT `link_table1_table2`
FOREIGN KEY (`fkey`)
REFERENCES `mydb`.`table1` (`idtable1`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`table3`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`table3` (
`idtable3` VARCHAR(45) NOT NULL,
`fkey` VARCHAR(45) NULL,
INDEX `fkey_table2_table_3_idx` (`fkey` ASC) VISIBLE,
CONSTRAINT `fkey_table2_table_3`
FOREIGN KEY (`fkey`)
REFERENCES `mydb`.`table2` (`idtable2`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
SET SQL_MODE=@OLD_SQL_MODE;
SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS;
SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;
"""
def insertData():
for i in range(2):
num_distinct_table1_values = 5
num_distinct_table2_values = 10
num_distinct_table3_values = 1000
num_entries_table1 = int(num_distinct_table1_values)
num_entries_table2 = int(num_distinct_table2_values * 10)
num_entries_table3 = int(num_distinct_table3_values * 300)
random_numbers_table1_id = range(num_distinct_table1_values)
random_numbers_table2_id = np.random.randint(num_distinct_table2_values, size=int(num_entries_table2))
random_numbers_table2_fkey = np.random.randint(num_distinct_table1_values, size=int(num_entries_table2))
random_numbers_table3_id = np.random.randint(num_distinct_table3_values, size=int(num_entries_table3))
random_numbers_table3_fkey = np.random.randint(num_distinct_table2_values, size=int(num_entries_table3))
value_string_table1 = ','.join([f"('{i_name}')" for i_name in random_numbers_table1_id])
value_string_table2=""
for i in range(num_entries_table2):
value_string_table2 = value_string_table2+','.join(
["('{id}','{fkey}'),".format(id=random_numbers_table2_id[i], fkey=random_numbers_table2_fkey[i])])
value_string_table3=""
for i in range(num_entries_table3):
value_string_table3 = value_string_table3+','.join(
["('{id}','{fkey}'),".format(id=random_numbers_table3_id[i], fkey=random_numbers_table3_fkey[i])])
# fill table 1
mySql_insert_query = f"INSERT INTO table1 (idtable1) VALUES {value_string_table1}"
cursor.execute(mySql_insert_query)
conn.commit()
print("Done table 1")
# fill table 2
mySql_insert_query = f"INSERT INTO table2 (idtable2, fkey) VALUES {value_string_table2}"
mySql_insert_query=mySql_insert_query[0:-1]
cursor.execute(mySql_insert_query)
print("Done table 2")
# fill table 3
mySql_insert_query = f"INSERT INTO table3 (idtable3, fkey) VALUES {value_string_table3}"
mySql_insert_query = mySql_insert_query[0:- 1]
cursor.execute(mySql_insert_query)
print("Done table 3")
conn.commit()
conn = mysql.connector.connect(user='root', password='admin', host='127.0.0.1',
database='mydb', raise_on_warnings=True, autocommit=False)
cursor = conn.cursor()
insertData()
conn.close()