每次我在现有数据上运行粘合剂爬虫时,它都会将 Serde 序列化库更改为
我尝试过制作自己的csv分类器,但没有帮助。
如何让爬虫指定用于生成或更新表的特定序列化库?
LazySimpleSerDe,这导致分类不正确(例如对于带逗号的引用字段)。
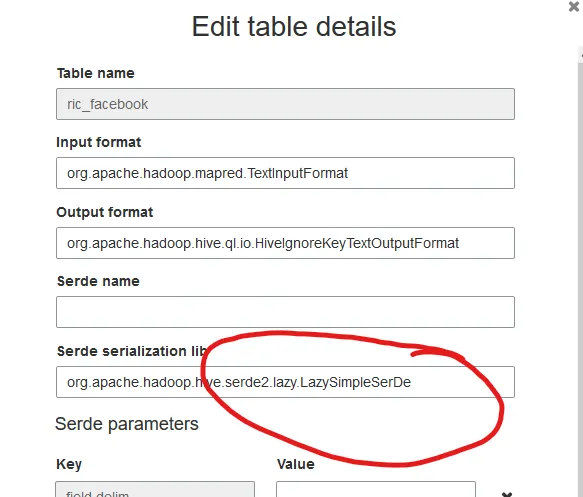
org.apache.hadoop.hive.serde2.OpenCSVSerde。我尝试过制作自己的csv分类器,但没有帮助。
如何让爬虫指定用于生成或更新表的特定序列化库?