我有一个包含大约16k行的视图,获取所有数据需要约5秒钟。
我决定在应用程序中实现“加载”,以便GUI不会冻结,用户可以在DataGridView中工作/查看提供的数据。
我注意到,如果我使用SQL分页来获取所有数据,需要约90秒(1.5分钟),因此这是适得其反的。
现在我想知道这是否正常,为什么有人要使用它?
我尝试了3种SQL分页的方法: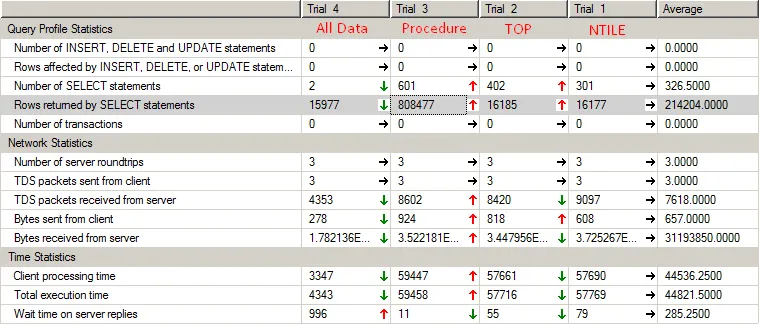
我决定在应用程序中实现“加载”,以便GUI不会冻结,用户可以在DataGridView中工作/查看提供的数据。
我注意到,如果我使用SQL分页来获取所有数据,需要约90秒(1.5分钟),因此这是适得其反的。
现在我想知道这是否正常,为什么有人要使用它?
我尝试了3种SQL分页的方法:
我正在使用160进行测试!
DECLARE @int_percentage AS INT = 1
WHILE @int_percentage <= 100
BEGIN
SELECT O.*, P.Percentage
FROM vAppointmentDetailsWithComments O
LEFT JOIN (SELECT AppointmentID, NTILE(100) OVER(ORDER BY AppointmentID) Percentage
FROM vAppointmentDetailsWithoutComments) P ON P.AppointmentID = O.AppointmentID
WHERE P.Percentage = @int_percentage
SET @int_percentage = @int_percentage + 1
END
---------------------------------------------------------------------------------------------------
DECLARE @int_percentage AS INT = 1, @int_appointmentID AS INT = 0
WHILE @int_percentage <= 100
BEGIN
SELECT TOP 160 *
FROM vAppointmentDetailsWithComments
WHERE AppointmentID > @int_appointmentID
SET @int_percentage = @int_percentage + 1
SET @int_appointmentID = @int_appointmentID + 161
END
---------------------------------------------------------------------------------------------------
DECLARE @int_percentage AS INT = 1, @int_currentStartingRowIndex AS INT = 1
WHILE @int_percentage <= 100
BEGIN
EXEC spGetRows @int_startingRowIndex = @int_currentStartingRowIndex, @int_maxRows = 160
SET @int_percentage = @int_percentage + 1
SET @int_currentStartingRowIndex = @int_currentStartingRowIndex + 160
END
---------------------------------------------------------------------------------------------------
SELECT *
FROM vAppointmentDetailsWithComments
步骤:
CREATE PROCEDURE [dbo].[spGetRows]
(
@int_startingRowIndex INT,
@int_maxRows INT
)
AS
DECLARE @int_firstID INT
-- Getting 1'st ID
SET ROWCOUNT @int_startingRowIndex
SELECT @int_firstID = AppointmentID FROM vAppointmentDetailsWithoutComments ORDER BY AppointmentID
-- Setting ROWCOUNT to MAX
SET ROWCOUNT @int_maxRows
-- Getting all data >= @int_firstID
SELECT *
FROM vAppointmentDetailsWithComments
WHERE AppointmentID >= @int_firstID
SET ROWCOUNT 0
GO
带有结果的内容:
表和视图的创建和填充数据:
"vAppointmentDetailsWithComments" 中的
FOR XML PATH是主要的性能问题。
CREATE TABLE [dbo].[Appointment](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Number] [int] NOT NULL,
CONSTRAINT [PK_Appointment] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Appointment] ADD CONSTRAINT [DF_Appointment_Number] DEFAULT ((0)) FOR [Number]
GO
---------------------------------------------------------------------------------------------------
CREATE TABLE [dbo].[Comment](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Appointment_ID] [int] NOT NULL,
[Text] [nvarchar](max) NOT NULL,
[Time] [datetime] NOT NULL,
CONSTRAINT [PK_Comment] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Comment] WITH CHECK ADD CONSTRAINT [FK_Comment_Appointment] FOREIGN KEY([Appointment_ID])
REFERENCES [dbo].[Appointment] ([ID])
GO
ALTER TABLE [dbo].[Comment] CHECK CONSTRAINT [FK_Comment_Appointment]
GO
ALTER TABLE [dbo].[Comment] ADD CONSTRAINT [DF_Comment_Text] DEFAULT (N'Some random Comment for Testing purposes') FOR [Text]
GO
ALTER TABLE [dbo].[Comment] ADD CONSTRAINT [DF_Comment_Time] DEFAULT (getdate()) FOR [Time]
GO
---------------------------------------------------------------------------------------------------
CREATE VIEW [dbo].[vAppointmentDetailsWithComments]
AS
SELECT A.ID AppointmentID, (K.Comments + CHAR(13) + CHAR(10)) Comment
FROM Appointment A LEFT JOIN
(SELECT A.ID,
(SELECT STUFF
((SELECT REPLACE(CHAR(13) + CHAR(10) + K.Text, CHAR(7), '')
FROM Comment K
WHERE K.Appointment_ID = A.ID
AND K.Text != ''
ORDER BY K.Time FOR XML PATH, TYPE ).value('.[1]', 'NVARCHAR(MAX)'), 1, 1, '')) Comments
FROM Appointment A) K ON K.ID = A.ID
GO
---------------------------------------------------------------------------------------------------
CREATE VIEW [dbo].[vAppointmentDetailsWithoutComments]
AS
SELECT A.ID AppointmentID
FROM Appointment A
GO
---------------------------------------------------------------------------------------------------
SET NOCOUNT ON
BEGIN TRAN
DECLARE @int_appointmentID AS INT = 1,
@int_tempComment AS INT
WHILE @int_appointmentID <= 16000
BEGIN
INSERT INTO Appointment VALUES (@int_appointmentID)
SET @int_tempComment = 1
WHILE @int_tempComment <= 5
BEGIN
INSERT INTO Comment (Appointment_ID) VALUES (@int_appointmentID)
SET @int_tempComment = @int_tempComment + 1
END
SET @int_appointmentID = @int_appointmentID + 1
END
COMMIT TRAN
GO
执行计划: 快速(FetchAll) 慢速(Top)
ORDER BY语句的OFFSET子句以便于T-SQL基础分页。但是,在执行分页操作之前,请确保视图查询已经完全优化,否则在其之上进行分页将会使情况变得更糟。请发布你的视图查询、CREATE TABLE语句和索引。 - Dan Guzman