在实践中,SortedList<TKey,TValue>和SortedDictionary<TKey,TValue>之间是否存在任何真正的实际差异?是否有任何情况下你会特别使用其中一个而不是另一个?
SortedList和SortedDictionary有什么区别?
311
- Shaul Behr
3
7个回答
347
是的 - 两者的性能特征有很大的不同。更好的称呼可能是SortedList和SortedTree,因为这更接近实现。
查看它们各自的MSDN文档(SortedList, SortedDictionary),了解不同情况下不同操作的性能细节。以下是一个很好的总结(来自于SortedDictionary文档):
SortedDictionary<TKey, TValue>泛型类是一种二分搜索树,具有O(log n)检索,其中n是字典中元素的数量。在这方面,它与SortedList<TKey, TValue>泛型类相似。这两个类具有类似的对象模型,并且都具有O(log n)的检索。这两个类的区别在于内存使用和插入/删除速度:
SortedList<TKey, TValue>比SortedDictionary<TKey,TValue>使用更少的内存。
SortedDictionary<TKey,TValue>对于无序数据的插入和删除操作更快,具有O(log n),而SortedList<TKey,TValue>则具有O(n)。如果列表一次性从排序数据中填充,
SortedList<TKey,TValue>比SortedDictionary<TKey,TValue>更快。
(SortedList 实际上维护了一个已排序的数组,而不是使用树。它仍然使用二分查找来查找元素。)
- Jon Skeet
4
非常感谢大家提供的指导。我想我只是太懒了,不想看文档...向SO上的好心人提问更容易一些...;) 我为你们两个的回答投了赞成票;Jon因为最先发出回答而获得了答案积分。 :) - Shaul Behr
2我认为SortedList的定义应该进行更正,因为我不认为它是一个二叉搜索树...? - nchaud
1我使用了反射器并发现它没有使用二叉搜索树。 - Daniel Imms
我认为SortedDictionary是AVL树或红黑树(所有操作的成本都是O(logn))。而SortedList是二分搜索(在最坏情况下它需要O(n)时间)。 - Ghoster
141
如果有助于理解,这里是表格视图...
从性能的角度来看:
+------------------+---------+----------+--------+----------+----------+---------+
| Collection | Indexed | Keyed | Value | Addition | Removal | Memory |
| | lookup | lookup | lookup | | | |
+------------------+---------+----------+--------+----------+----------+---------+
| SortedList | O(1) | O(log n) | O(n) | O(n)* | O(n) | Lesser |
| SortedDictionary | O(n)** | O(log n) | O(n) | O(log n) | O(log n) | Greater |
+------------------+---------+----------+--------+----------+----------+---------+
* Insertion is O(log n) for data that are already in sort order, so that each
element is added to the end of the list. If a resize is required, that element
takes O(n) time, but inserting n elements is still amortized O(n log n).
list.
** Available through enumeration, e.g. Enumerable.ElementAt.
从实施的角度来看:
+------------+---------------+----------+------------+------------+------------------+
| Underlying | Lookup | Ordering | Contiguous | Data | Exposes Key & |
| structure | strategy | | storage | access | Value collection |
+------------+---------------+----------+------------+------------+------------------+
| 2 arrays | Binary search | Sorted | Yes | Key, Index | Yes |
| BST | Binary search | Sorted | No | Key | Yes |
+------------+---------------+----------+------------+------------+------------------+
SortedDictionary可能是更好的选择。如果您需要较低的内存开销和索引检索,则SortedList更适合。请参阅此问题以了解更多有关何时使用哪种的信息。
- nawfal
3
请注意,如果您想要良好的性能、相对较低的内存使用和索引检索,请考虑使用 LoycCore 中的
BDictionary<Key,Value> 而不是 SortedDictionary。链接 - Qwertie1是的,请看这篇文章的底部。结果表明,除了非常大的尺寸外,
BDictionary通常比SortedDictionary慢,但如果有超过700个项目,它比SortedList更快。由于在树的叶子中使用数组,内存使用应该只比SortedList略高(比SortedDictionary低得多)。 - Qwertie1很遗憾,将元素有序插入SortedList的时间复杂度是O(log n)。如果在执行二分查找之前进行一次检查,使其变为O(1)的实现本来很容易。 - relatively_random
27
我打开了Reflector来查看这个问题,因为关于SortedList似乎有些混淆。实际上它不是二叉搜索树,而是按键排序的键值对数组。还有一个TKey[] keys变量,与键值对同步排序并用于二分搜索。
这里有一些针对.NET 4.5的源代码来支持我的说法。
私有成员:
这里有一些针对.NET 4.5的源代码来支持我的说法。
私有成员:
// Fields
private const int _defaultCapacity = 4;
private int _size;
[NonSerialized]
private object _syncRoot;
private IComparer<TKey> comparer;
private static TKey[] emptyKeys;
private static TValue[] emptyValues;
private KeyList<TKey, TValue> keyList;
private TKey[] keys;
private const int MaxArrayLength = 0x7fefffff;
private ValueList<TKey, TValue> valueList;
private TValue[] values;
private int version;
SortedList.ctor(IDictionary, IComparer)
public SortedList(IDictionary<TKey, TValue> dictionary, IComparer<TKey> comparer) : this((dictionary != null) ? dictionary.Count : 0, comparer)
{
if (dictionary == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.dictionary);
}
dictionary.Keys.CopyTo(this.keys, 0);
dictionary.Values.CopyTo(this.values, 0);
Array.Sort<TKey, TValue>(this.keys, this.values, comparer);
this._size = dictionary.Count;
}
SortedList.Add(TKey, TValue) : void
public void Add(TKey key, TValue value)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
int num = Array.BinarySearch<TKey>(this.keys, 0, this._size, key, this.comparer);
if (num >= 0)
{
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
this.Insert(~num, key, value);
}
SortedList.RemoveAt(int) : void
public void RemoveAt(int index)
{
if ((index < 0) || (index >= this._size))
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.index, ExceptionResource.ArgumentOutOfRange_Index);
}
this._size--;
if (index < this._size)
{
Array.Copy(this.keys, index + 1, this.keys, index, this._size - index);
Array.Copy(this.values, index + 1, this.values, index, this._size - index);
}
this.keys[this._size] = default(TKey);
this.values[this._size] = default(TValue);
this.version++;
}
- Daniel Imms
15
已经有足够的关于这个主题的讨论了,然而为了简化,以下是我的看法。
当-
- 需要更多的插入和删除操作。
- 数据无序。
- 只需要键访问而不需要索引访问。
- 内存不是瓶颈时,应该使用排序字典。
另一方面,当-
- 需要更多的查找和较少的插入和删除操作。
- 数据已经排序(如果不是全部,则是大多数)。
- 需要索引访问。
- 内存是一个负担时,应该使用排序列表。
希望能对您有所帮助!
- Prakash Tripathi
13
这是一种将性能相互比较的可视化表示方式。
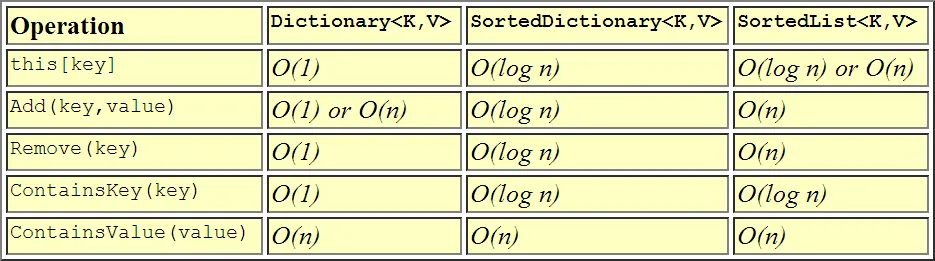
- Lev
3
1你从哪里得到这个信息的?从这个方案中我们可以看出,字典在任何方面都更好,所以其他的方式没有存在的理由。 - Cute pumpkin
1@alexkostin 或许有点晚了,但请参考 https://dev59.com/2XM_5IYBdhLWcg3wUxZB#19702706。我在源链接方面遇到了问题,但是我在 wayback machine 上找到了它。 - Ben
1@alexkostin
Dictionary<K, V> 不保留其元素的插入顺序,而 SortedList<K, V> 和 SortedDictionary<K, V> 则按照给定的 IComparer<K> 进行排序。 - Steve Guidi13
来自备注部分:
SortedList<(Of <(TKey, TValue>)>)泛型类是一个二叉搜索树,具有O(log n)的检索速度,其中n是字典中元素的数量。在这方面,它与SortedDictionary<(Of <(TKey, TValue>)>)泛型类相似。这两个类具有相似的对象模型,并且都具有O(log n)的检索速度。这两个类的区别在于内存使用和插入/删除速度方面:
SortedList<(Of <(TKey, TValue>)>)使用的内存比SortedDictionary<(Of <(TKey, TValue>)>)少。
SortedDictionary<(Of <(TKey, TValue>)>)对于未排序的数据具有更快的插入和删除操作,是O(log n),而不是SortedList<(Of <(TKey, TValue>)>)的O(n)。如果列表一次性从已排序的数据中填充,则
SortedList<(Of <(TKey, TValue>)>)比SortedDictionary<(Of <(TKey, TValue>)>)更快。
- Stephan
1
9引用的文本是错误的(并已在 MSDN 上更新):SortedList 不是“二叉搜索树”,而是“键/值对的数组”。 - Eldritch Conundrum
1
索引访问(在此处提到)是实际上的区别。如果需要访问后继或前驱,您需要使用SortedList。SortedDictionary无法做到这一点,因此您在使用排序(首个/foreach)时受到相当大的限制。
- Guy
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 3 为什么有两种 SortedList?
- 12 <%# %> 和 <%= %> 有什么区别?
- 26 .NET中是否有SortedList<T>类?(不是SortedList<K,V>)
- 223 .Net数据结构:ArrayList、List、HashTable、Dictionary、SortedList、SortedDictionary -- 速度、内存和何时使用它们?
- 4 SortedList/SortedDictionary的奇怪行为
- 4 一个实现了合适比较器的 SortedList<> / SortedDictionary<> 是否能用来保证插入顺序?
- 71 何时应该使用SortedList<TKey, TValue>而不是SortedDictionary<TKey, TValue>?
- 128 SortedList<>, SortedDictionary<> and Dictionary<>
- 23 从SortedList或SortedDictionary中获取第i个值
- 24 SortedList、SortedDictionary和Sort()的比较
SortedList<TKey, TValue>而不是一个SortedList<T>?它为什么没有实现IList<T>?我感到困惑。 - Colonel Panic