更新:原来生成树的解析器存在错误。请参见最终编辑部分。
设 T 是一棵二叉树,其中每个内部节点恰好有两个子节点。对于这棵树,我们想编写一个函数,对于树中的每个节点 v,找到由 v 定义的子树中节点的数量。
示例
输入:
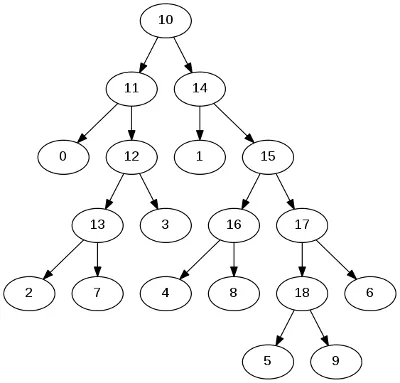
期望的输出
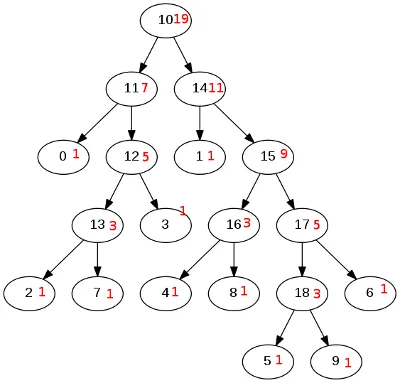
红色数字表示我们要计算的数字。树的节点将存储在一个数组中,我们称其为TreeArray,按照前序布局进行。
对于上面的示例,TreeArray将包含以下对象:
10, 11, 0, 12, 13, 2, 7, 3, 14, 1, 15, 16, 4, 8, 17, 18, 5, 9, 6
树的节点由以下结构描述:
struct tree_node{
long long int id; //id of the node, randomly generated
int numChildren; //number of children, it is 2 but for the leafs it's 0
int size; //size of the subtree rooted at the current node,
// what we want to compute
int pos; //position in TreeArray where the node is stored
int lpos; //position of the left child
int rpos; //position of the right child
tree_node(){
id = -1;
size = 1;
pos = lpos = rpos = -1;
numChildren = 0;
}
};
计算所有 size 值的函数如下:
void testCache(int cur){
if(treeArray[cur].numChildren == 0){
treeArray[cur].size = 1;
return;
}
testCache(treeArray[cur].lpos);
testCache(treeArray[cur].rpos);
treeArray[cur].size = treeArray[treeArray[cur].lpos].size +
treeArray[treeArray[cur].rpos].size + 1;
}
我想了解为什么这个函数在 T 看起来像这样(几乎像一个向左的链)时会更加快速:
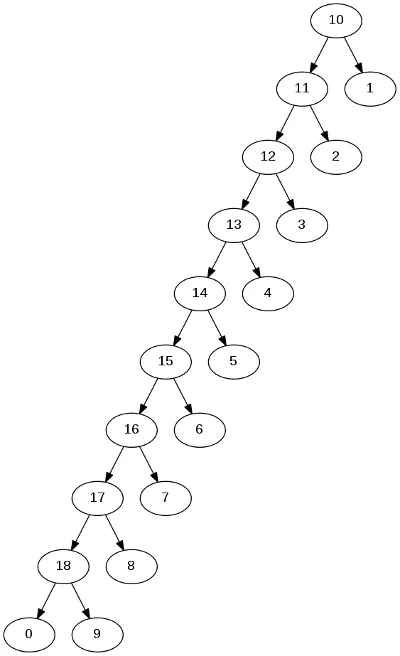
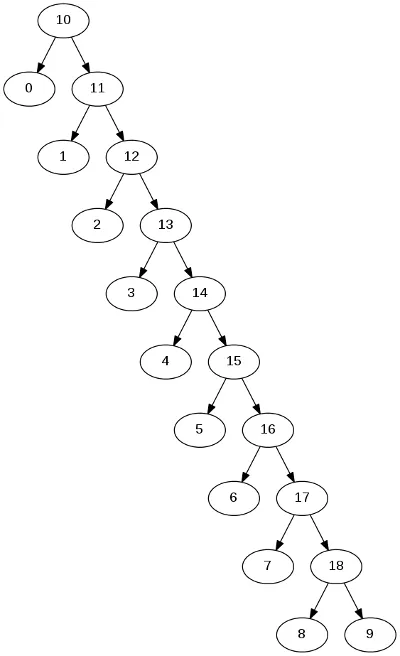
当T看起来像这样(几乎像一个向右的链)时,速度会变慢:
图中的每个点都是以下for循环的结果(参数由轴定义):
for (int i = 0; i < 100; i++) {
testCache(0);
}
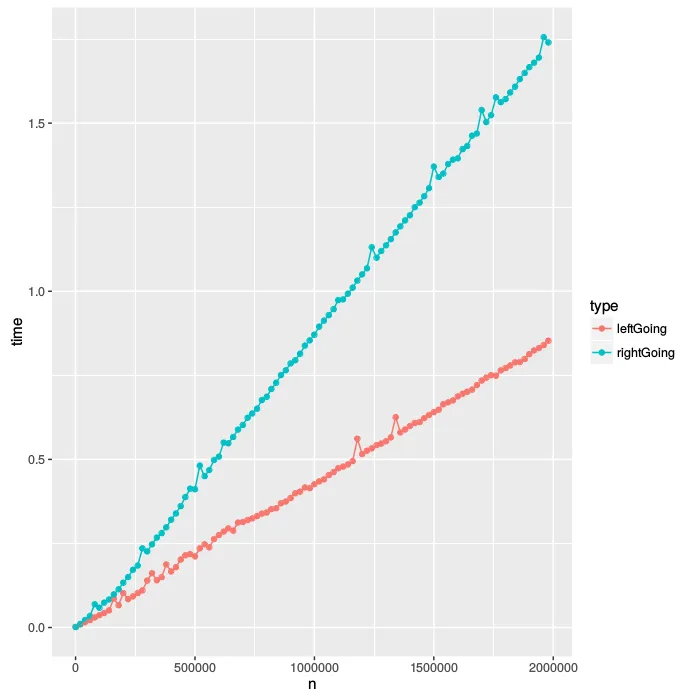
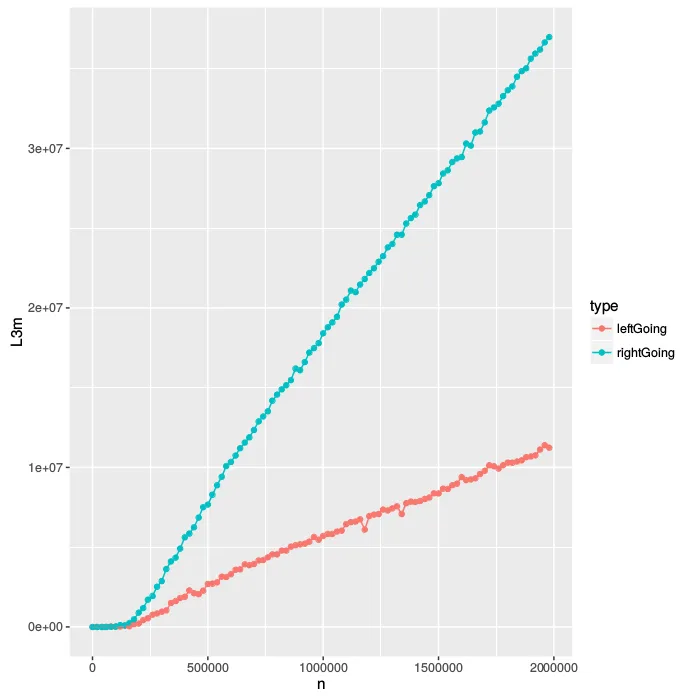
n 对应节点的总数,时间以秒为单位。我们可以看到,很明显当树形状类似于向左的链时,随着n的增长,函数速度更快,尽管在两种情况下节点数量完全相同。
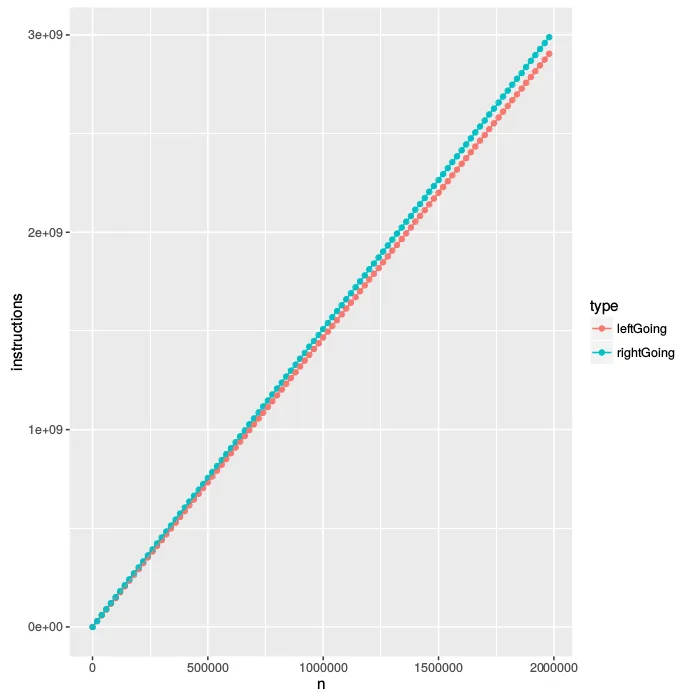
现在让我们尝试找出瓶颈所在。我使用了PAPI库来计算有趣的硬件计数器。
第一个计数器是指令,我们实际上花费了多少指令?当树的形状不同时是否存在差异?
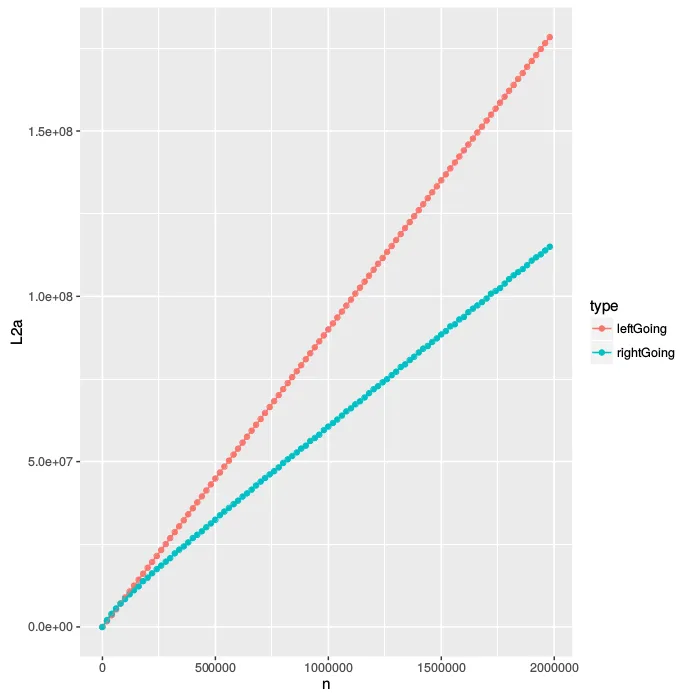
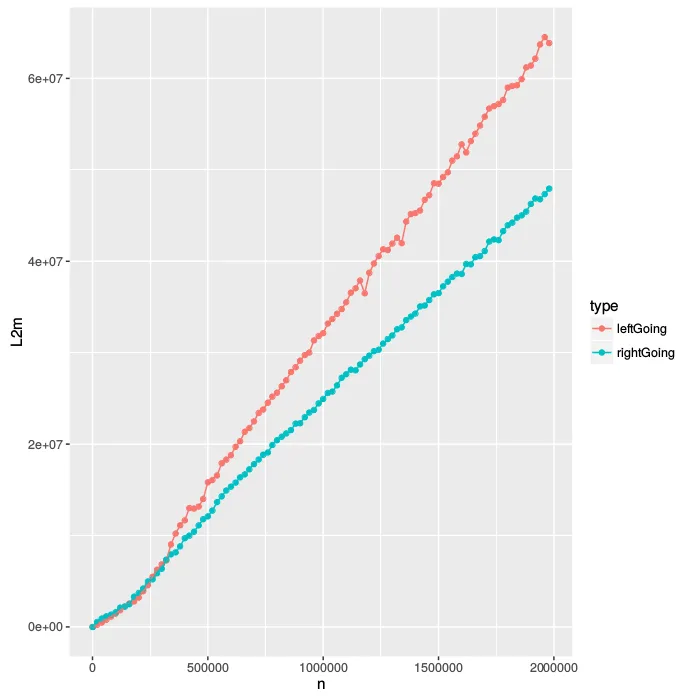
既然我们已经在treeArray中以漂亮的预排序布局存储了树,那么查看缓存中正在发生的事情是有意义的。不幸的是,对于L1缓存,我的电脑没有提供任何计数器,但是我有L2和L3的计数器。
让我们来看看对L2缓存的访问。当我们在L1缓存中遇到未命中时,就会发生对L2缓存的访问,因此这也是L1未命中的间接计数器。
#include <iostream>
#include <fstream>
#define BILLION 1000000000LL
using namespace std;
/*
*
* Timing functions
*
*/
timespec startT, endT;
void startTimer(){
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &startT);
}
double endTimer(){
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &endT);
return endT.tv_sec * BILLION + endT.tv_nsec - (startT.tv_sec * BILLION + startT.tv_nsec);
}
/*
*
* tree node
*
*/
//this struct is used for creating the first tree after reading it from the external file, for this we need left and child pointers
struct tree_node_temp{
long long int id; //id of the node, randomly generated
int numChildren; //number of children, it is 2 but for the leafs it's 0
int size; //size of the subtree rooted at the current node
tree_node_temp *leftChild;
tree_node_temp *rightChild;
tree_node_temp(){
id = -1;
size = 1;
leftChild = nullptr;
rightChild = nullptr;
numChildren = 0;
}
};
struct tree_node{
long long int id; //id of the node, randomly generated
int numChildren; //number of children, it is 2 but for the leafs it's 0
int size; //size of the subtree rooted at the current node
int pos; //position in TreeArray where the node is stored
int lpos; //position of the left child
int rpos; //position of the right child
tree_node(){
id = -1;
pos = lpos = rpos = -1;
numChildren = 0;
}
};
/*
*
* Tree parser. The input is a file containing the tree in the newick format.
*
*/
string treeNewickStr; //string storing the newick format of a tree that we read from a file
int treeCurSTRindex; //index to the current position we are in while reading the newick string
int treeNumLeafs; //number of leafs in current tree
tree_node ** treeArrayReferences; //stack of references to free node objects
tree_node *treeArray; //array of node objects
int treeStackReferencesTop; //the top index to the references stack
int curpos; //used to find pos,lpos and rpos when creating the pre order layout tree
//helper function for readNewick
tree_node_temp* readNewickHelper() {
int i;
if(treeCurSTRindex == treeNewickStr.size())
return nullptr;
tree_node_temp * leftChild;
tree_node_temp * rightChild;
if(treeNewickStr[treeCurSTRindex] == '('){
//create a left child
treeCurSTRindex++;
leftChild = readNewickHelper();
}
if(treeNewickStr[treeCurSTRindex] == ','){
//create a right child
treeCurSTRindex++;
rightChild = readNewickHelper();
}
if(treeNewickStr[treeCurSTRindex] == ')' || treeNewickStr[treeCurSTRindex] == ';'){
treeCurSTRindex++;
tree_node_temp * cur = new tree_node_temp();
cur->numChildren = 2;
cur->leftChild = leftChild;
cur->rightChild = rightChild;
cur->size = 1 + leftChild->size + rightChild->size;
return cur;
}
//we are about to read a label, keep reading until we read a "," ")" or "(" (we assume that the newick string has the right format)
i = 0;
char treeLabel[20]; //buffer used for the label
while(treeNewickStr[treeCurSTRindex]!=',' && treeNewickStr[treeCurSTRindex]!='(' && treeNewickStr[treeCurSTRindex]!=')'){
treeLabel[i] = treeNewickStr[treeCurSTRindex];
treeCurSTRindex++;
i++;
}
treeLabel[i] = '\0';
tree_node_temp * cur = new tree_node_temp();
cur->numChildren = 0;
cur->id = atoi(treeLabel)-1;
treeNumLeafs++;
return cur;
}
//create the pre order tree, curRoot in the first call points to the root of the first tree that was given to us by the parser
void treeInit(tree_node_temp * curRoot){
tree_node * curFinalRoot = treeArrayReferences[curpos];
curFinalRoot->pos = curpos;
if(curRoot->numChildren == 0) {
curFinalRoot->id = curRoot->id;
return;
}
//add left child
tree_node * cnode = treeArrayReferences[treeStackReferencesTop];
curFinalRoot->lpos = curpos + 1;
curpos = curpos + 1;
treeStackReferencesTop++;
cnode->id = curRoot->leftChild->id;
treeInit(curRoot->leftChild);
//add right child
curFinalRoot->rpos = curpos + 1;
curpos = curpos + 1;
cnode = treeArrayReferences[treeStackReferencesTop];
treeStackReferencesTop++;
cnode->id = curRoot->rightChild->id;
treeInit(curRoot->rightChild);
curFinalRoot->id = curRoot->id;
curFinalRoot->numChildren = 2;
curFinalRoot->size = curRoot->size;
}
//the ids of the leafs are deteremined by the newick file, for the internal nodes we just incrementally give the id determined by the dfs traversal
void updateInternalNodeIDs(int cur){
tree_node* curNode = treeArrayReferences[cur];
if(curNode->numChildren == 0){
return;
}
curNode->id = treeNumLeafs++;
updateInternalNodeIDs(curNode->lpos);
updateInternalNodeIDs(curNode->rpos);
}
//frees the memory of the first tree generated by the parser
void treeFreeMemory(tree_node_temp* cur){
if(cur->numChildren == 0){
delete cur;
return;
}
treeFreeMemory(cur->leftChild);
treeFreeMemory(cur->rightChild);
delete cur;
}
//reads the tree stored in "file" under the newick format and creates it in the main memory. The output (what the function returns) is a pointer to the root of the tree.
//this tree is scattered anywhere in the memory.
tree_node* readNewick(string& file){
treeCurSTRindex = -1;
treeNewickStr = "";
treeNumLeafs = 0;
ifstream treeFin;
treeFin.open(file, ios_base::in);
//read the newick format of the tree and store it in a string
treeFin>>treeNewickStr;
//initialize index for reading the string
treeCurSTRindex = 0;
//create the tree in main memory
tree_node_temp* root = readNewickHelper();
//store the tree in an array following the pre order layout
treeArray = new tree_node[root->size];
treeArrayReferences = new tree_node*[root->size];
int i;
for(i=0;i<root->size;i++)
treeArrayReferences[i] = &treeArray[i];
treeStackReferencesTop = 0;
tree_node* finalRoot = treeArrayReferences[treeStackReferencesTop];
curpos = treeStackReferencesTop;
treeStackReferencesTop++;
finalRoot->id = root->id;
treeInit(root);
//update the internal node ids (the leaf ids are defined by the ids stored in the newick string)
updateInternalNodeIDs(0);
//close the file
treeFin.close();
//free the memory of initial tree
treeFreeMemory(root);
//return the pre order tree
return finalRoot;
}
/*
*
*
* DOT FORMAT OUTPUT --- BEGIN
*
*
*/
void treeBstPrintDotAux(tree_node* node, ofstream& treeFout) {
if(node->numChildren == 0) return;
treeFout<<" "<<node->id<<" -> "<<treeArrayReferences[node->lpos]->id<<";\n";
treeBstPrintDotAux(treeArrayReferences[node->lpos], treeFout);
treeFout<<" "<<node->id<<" -> "<<treeArrayReferences[node->rpos]->id<<";\n";
treeBstPrintDotAux(treeArrayReferences[node->rpos], treeFout);
}
void treePrintDotHelper(tree_node* cur, ofstream& treeFout){
treeFout<<"digraph BST {\n";
treeFout<<" node [fontname=\"Arial\"];\n";
if(cur == nullptr){
treeFout<<"\n";
}
else if(cur->numChildren == 0){
treeFout<<" "<<cur->id<<";\n";
}
else{
treeBstPrintDotAux(cur, treeFout);
}
treeFout<<"}\n";
}
void treePrintDot(string& file, tree_node* root){
ofstream treeFout;
treeFout.open(file, ios_base::out);
treePrintDotHelper(root, treeFout);
treeFout.close();
}
/*
*
*
* DOT FORMAT OUTPUT --- END
*
*
*/
/*
* experiments
*
*/
tree_node* T;
int n;
void testCache(int cur){
if(treeArray[cur].numChildren == 0){
treeArray[cur].size = 1;
return;
}
testCache(treeArray[cur].lpos);
testCache(treeArray[cur].rpos);
treeArray[cur].size = treeArray[treeArray[cur].lpos].size + treeArray[treeArray[cur].rpos].size + 1;
}
int main(int argc, char* argv[]){
string Tnewick = argv[1];
T = readNewick(Tnewick);
n = T->size;
double tt;
startTimer();
for (int i = 0; i < 100; i++) {
testCache(0);
}
tt = endTimer();
cout << tt / BILLION << '\t' << T->size;
cout<<endl;
return 0;
}
通过输入以下命令进行编译:
g++ -O3 -std=c++11 file.cpp
通过输入以下命令运行:./executable tree.txt。在 tree.txt 中,我们将树存储为Newick格式。这里是一个有10^5个叶子的向左的树(链接)。
这里是一个有10^5个叶子的向右的树(链接)。
我得到的运行时间为: 向左的树约为0.07秒 向右的树约为0.12秒
很抱歉内容较长,但考虑到问题似乎很狭窄,我找不到更好的描述方式。
提前感谢您!
编辑:
这是对MrSmith42回答后的跟进编辑。我了解到地域因素起着非常重要的作用,但我不确定是否在这种情况下也是如此。
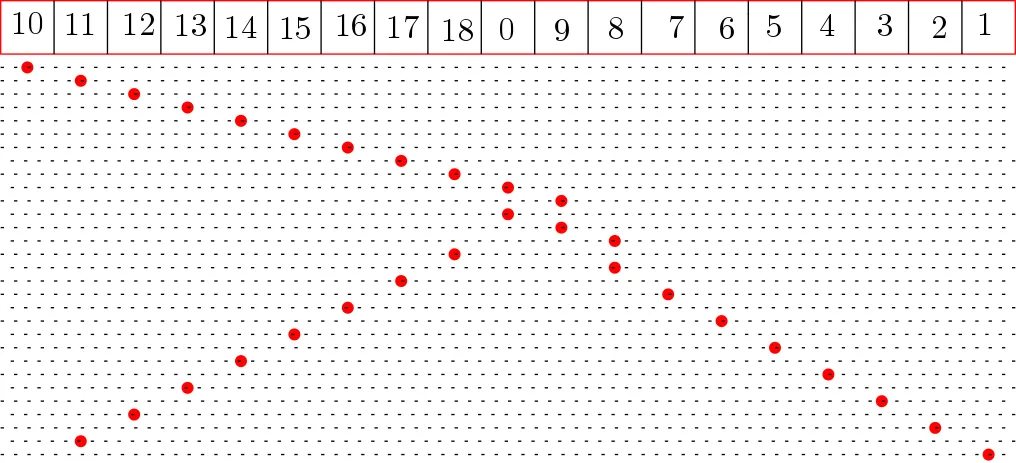
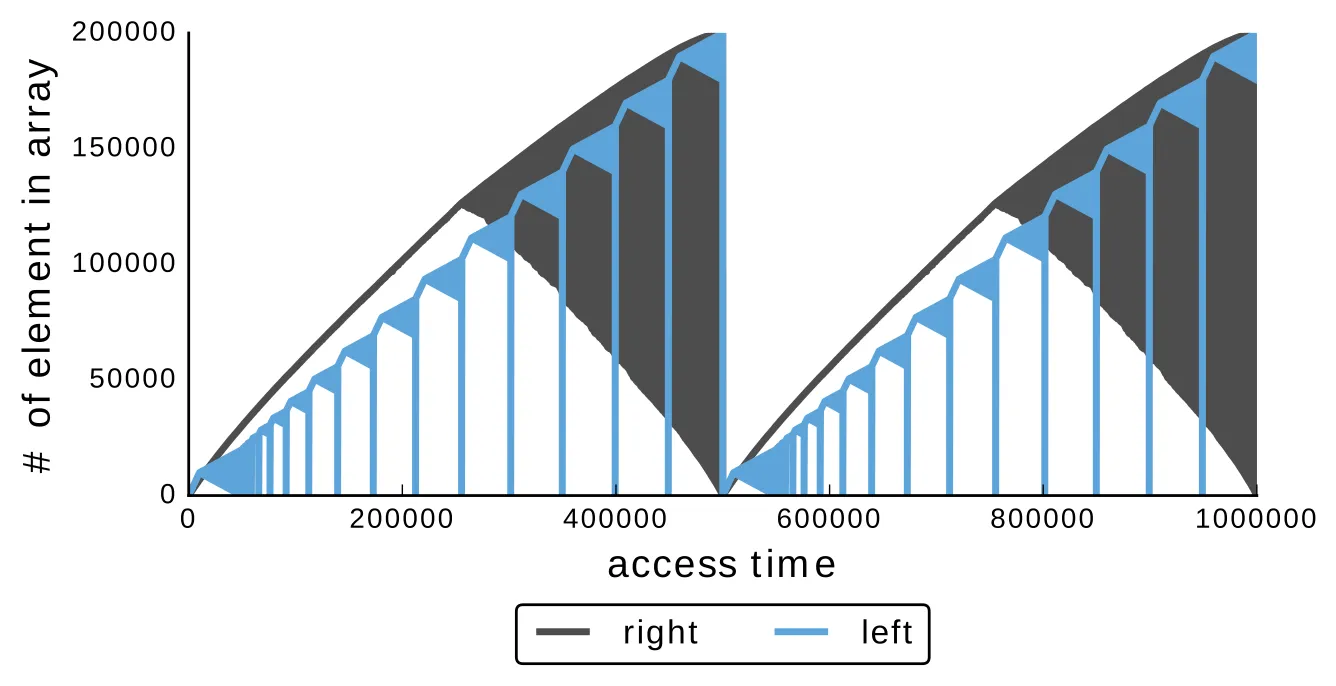
对于上面的两棵示例树,让我们看看如何随时间访问内存。
对于向左走的树:
编辑:
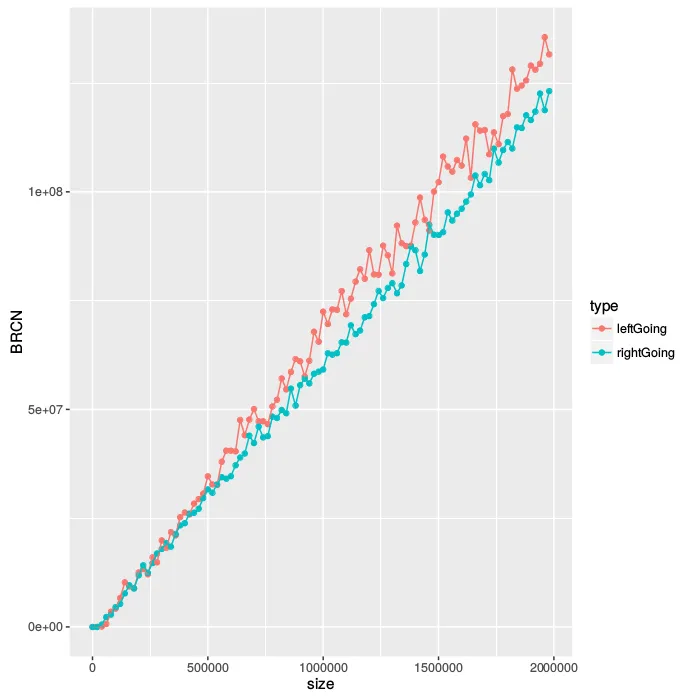
这里是关于条件分支数量的图表:
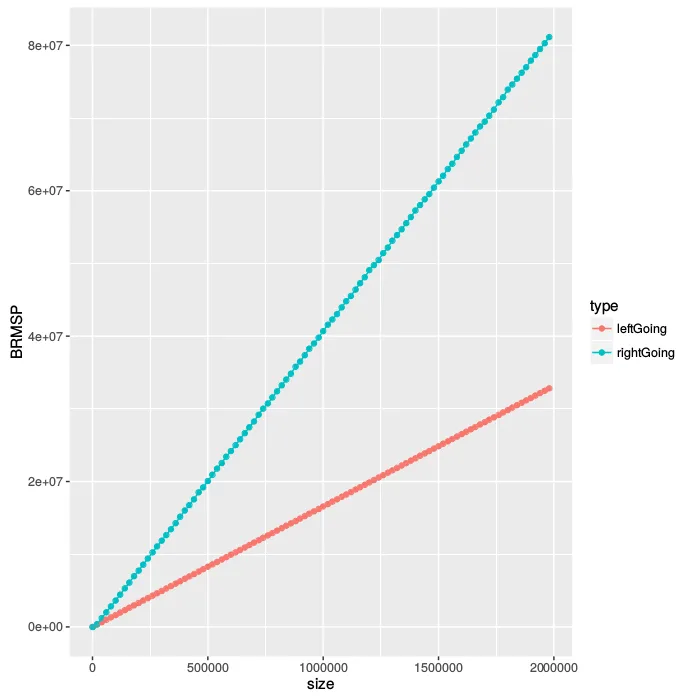
这里是一个有10^6个叶子节点的向左生长的树
这里是一个有10^6个叶子节点的向右生长的树
最终编辑:
我想为浪费大家的时间道歉,我使用的解析器有一个参数,可以使我的树看起来“左”或“右”。那是一个浮点数,它必须接近0才能向左移动,接近1才能向右移动。但是,要使它看起来像一条链,它必须非常小,例如0.000000001或0.999999999。对于小输入,即使对于像0.0001这样的值,树也看起来像一条链。我认为这个数字已经足够小了,而且它也会给较大的树带来链式效果,但正如我将展示的那样,并非如此。如果您使用像0.000000001这样的数字,解析器由于浮点问题而停止工作。vadikrobot的答案表明我们存在局部性问题。受他的实验启发,我决定将上面的访问模式图形推广到不仅仅是示例树中,而是在任何树中都能看到它的行为。
我修改了vadikrobot的代码,如下所示:
void testCache(int cur, FILE *f) {
if(treeArray[cur].numChildren == 0){
fprintf(f, "%d\t", tim++);
fprintf (f, "%d\n", cur);
treeArray[cur].size = 1;
return;
}
fprintf(f, "%d\t", tim++);
fprintf (f, "%d\n", cur);
testCache(treeArray[cur].lpos, f);
fprintf(f, "%d\t", tim++);
fprintf (f, "%d\n", cur);
testCache(treeArray[cur].rpos, f);
fprintf(f, "%d\t", tim++);
fprintf (f, "%d\n", cur);
fprintf(f, "%d\t", tim++);
fprintf (f, "%d\n", treeArray[cur].lpos);
fprintf(f, "%d\t", tim++);
fprintf (f, "%d\n", treeArray[cur].rpos);
treeArray[cur].size = treeArray[treeArray[cur].lpos].size +
treeArray[treeArray[cur].rpos].size + 1;
}
使用错误解析器生成的访问模式
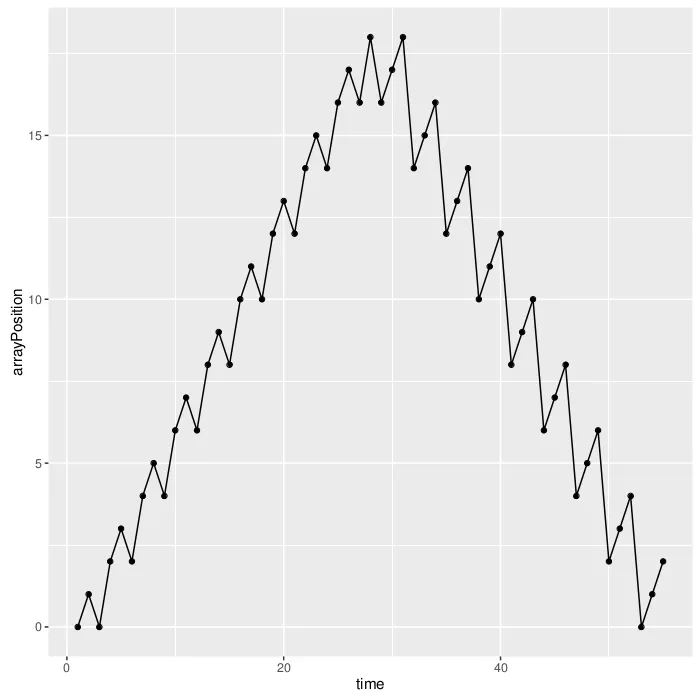
让我们看一个有10个叶子节点的左树。
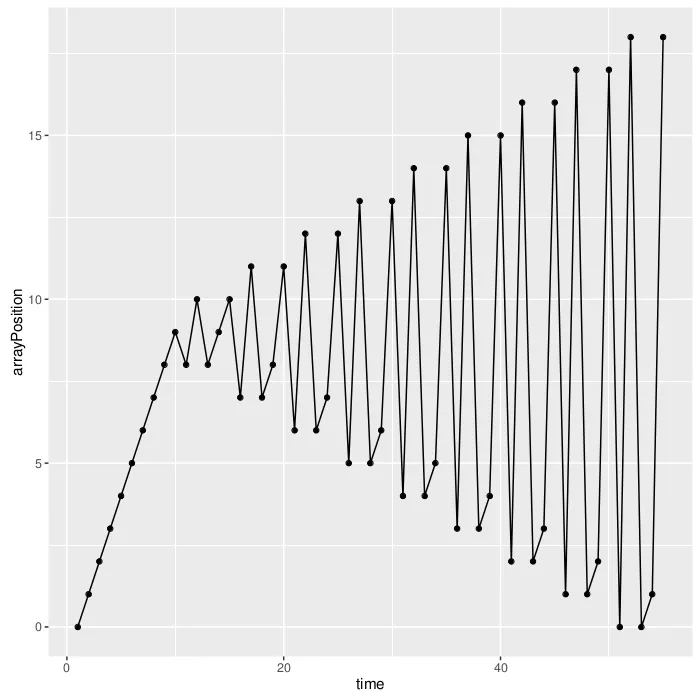
看起来非常不错,与上面的图表预测一样(我只是忘记了在上面的图表中,当我们找到节点的大小时,还要访问该节点的大小参数,源代码中的cur)。
让我们来看一个有100个叶子节点的左树。
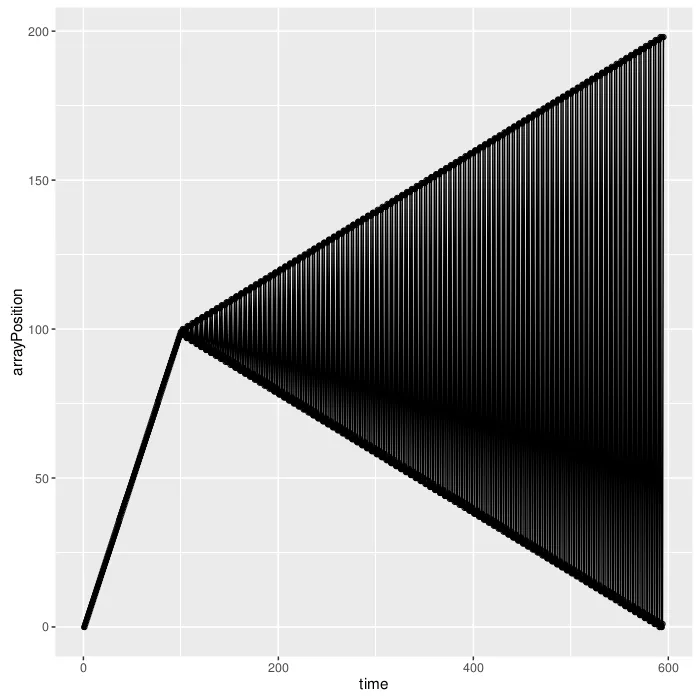
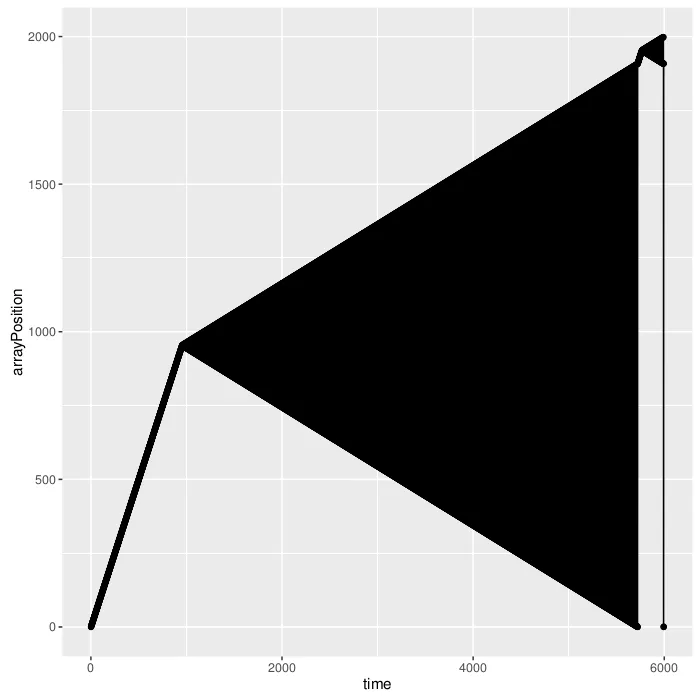
这绝对是出乎意料的。右上角有一个小三角形。原因是树看起来不像一个向左的链,末尾还有一个小子树。当叶子节点达到10^4时,问题变得更加严重。
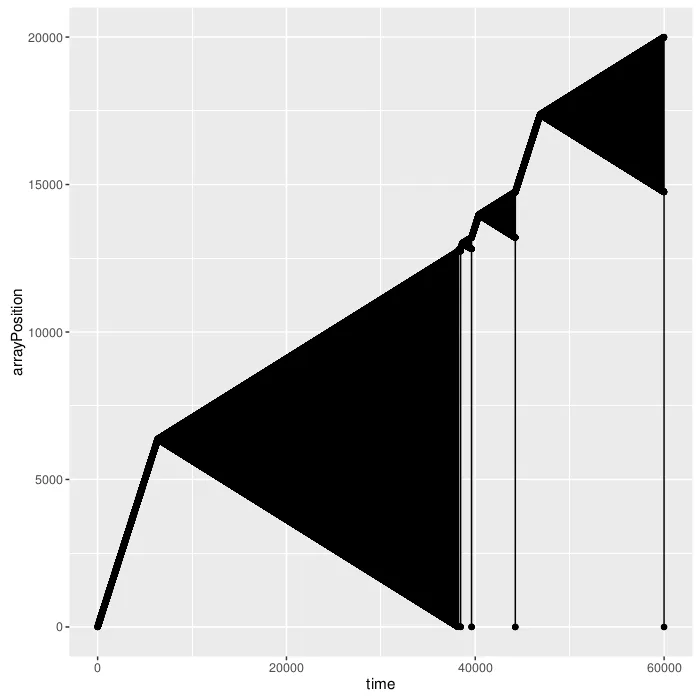
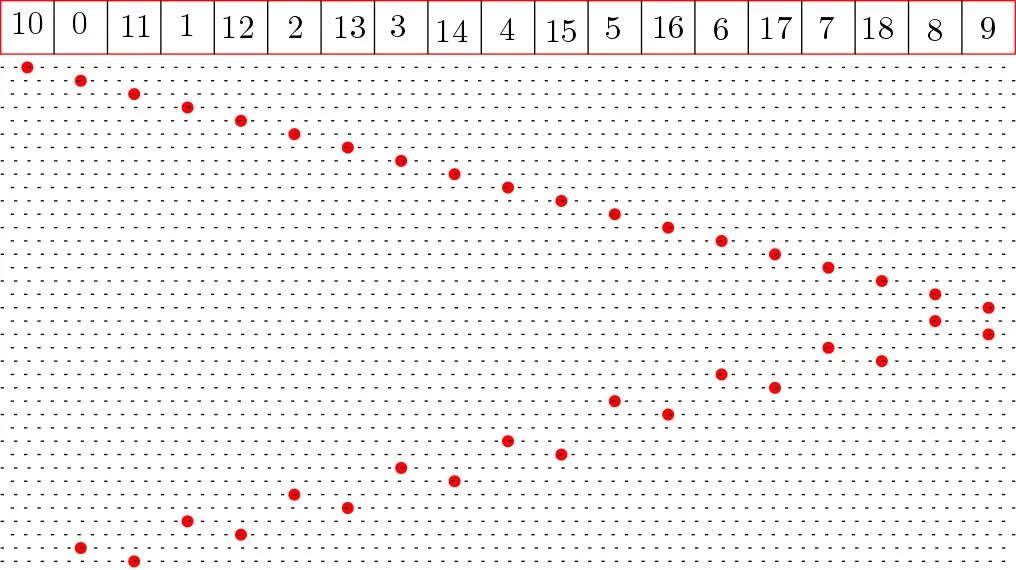
让我们来看看正确树的情况。当叶子数量为10时:
看起来不错,那100个叶子呢?
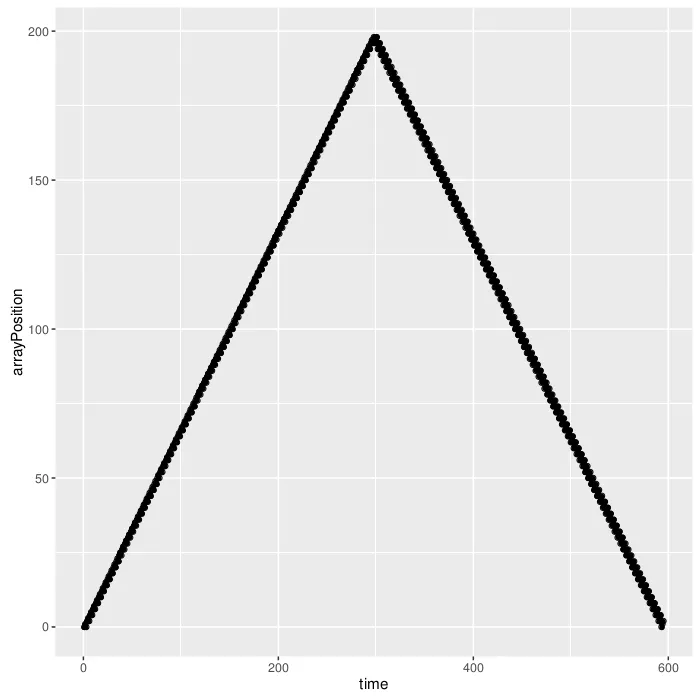
看起来也不错。这就是我对正确树的本地性提出质疑的原因,对我来说两者都至少在理论上是本地的。现在,如果你尝试增加大小,会发生一些有趣的事情:
对于1000个叶子:
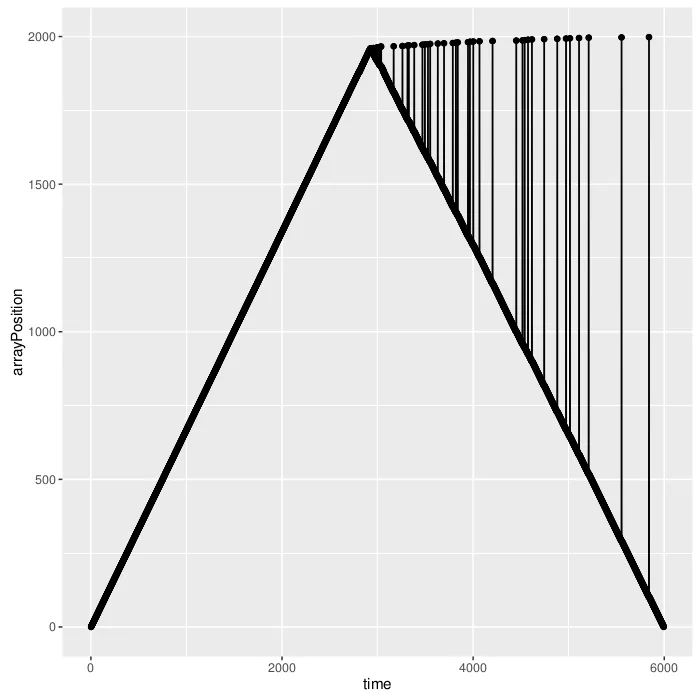
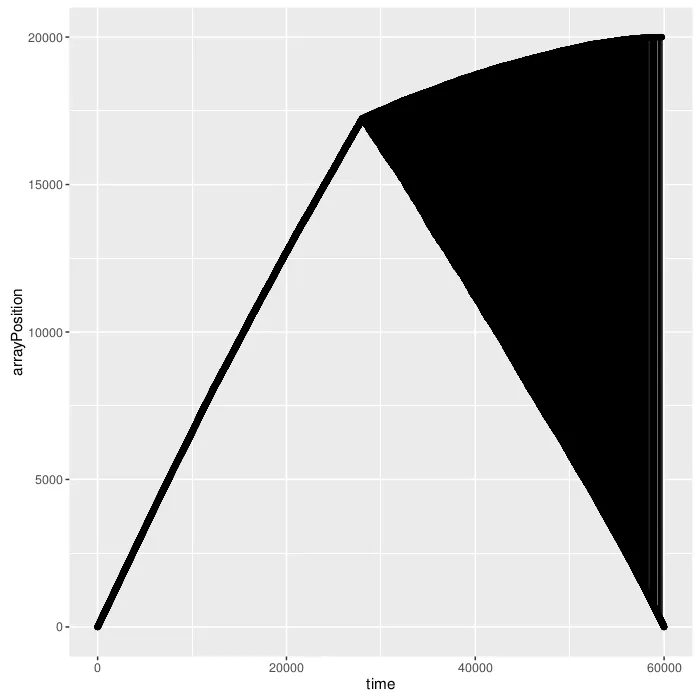
正确解析器生成的访问模式
与使用通用解析器不同,我为这个特定问题创建了一个解析器:
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char* argv[]){
if(argc!=4){
cout<<"type ./executable n{number of leafs} type{l:left going, r:right going} outputFile"<<endl;
return 0;
}
int i;
int n = atoi(argv[1]);
if(n <= 2){cout<<"leafs must be at least 3"<<endl; return 0;}
char c = argv[2][0];
ofstream fout;
fout.open(argv[3], ios_base::out);
if(c == 'r'){
for(i=0;i<n-1;i++){
fout<<"("<<i<<",";
}
fout<<i;
for(i=0;i<n;i++){
fout<<")";
}
fout<<";"<<endl;
}
else{
for(i=0;i<n-1;i++){
fout<<"(";
}
fout<<1<<","<<n<<")";
for(i=n-1;i>1;i--){
fout<<","<<i<<")";
}
fout<<";"<<endl;
}
fout.close();
return 0;
}
现在访问模式看起来如预期。
对于有10^4个叶子节点的左树:
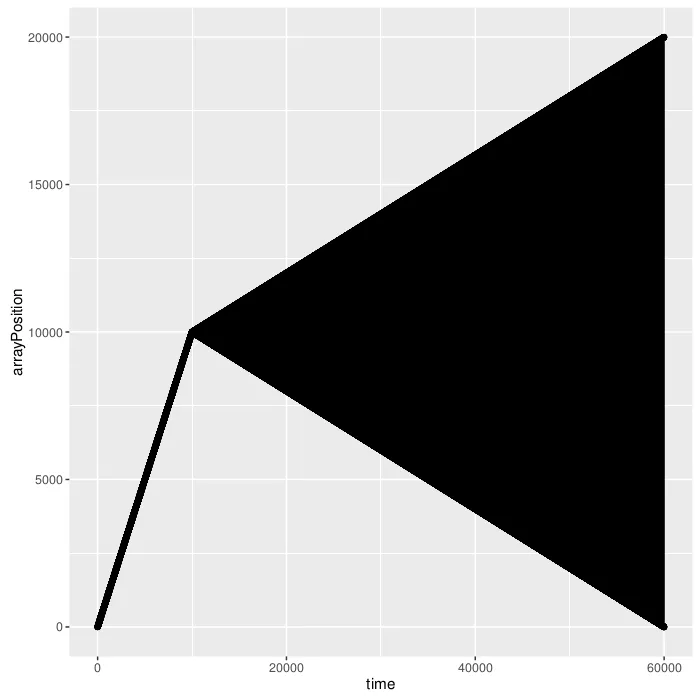
对于具有10^4个叶子节点的右树:
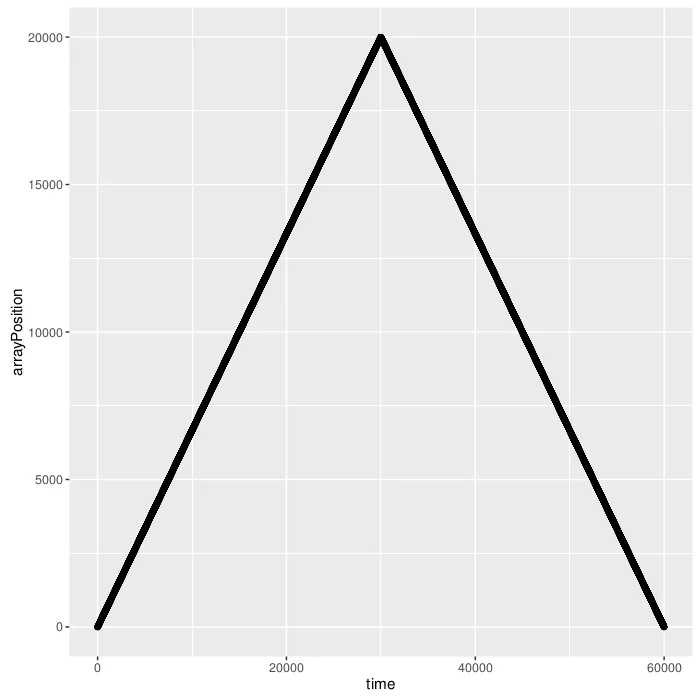
这个实验重做了一遍。这次我只试了最多10^5片叶子,因为正如Mysticial所指出的那样,由于树的高度,我们会遇到堆栈溢出问题。这在之前的实验中并不是问题,因为高度小于预期。
时间上它们似乎表现相同,但缓存和分支不同。右侧树在分支预测方面胜过左侧树,在缓存方面则输给左侧树。
也许我的PAPI使用方法有误,来自perf的输出:
左侧树:
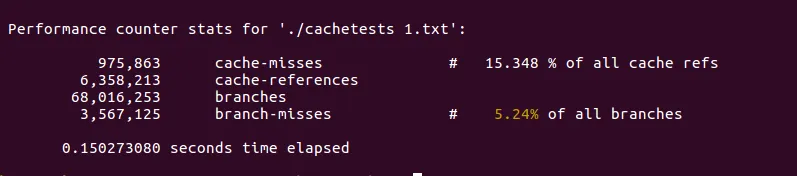
正确的树:

我可能又搞砸了什么事情,对此我感到抱歉。我在这里提供了我的尝试,以防有人想要继续调查。
startTimer()。现在运行时间已经改变,对于l.txt是~0.7s,对于r.txt是~0.12s。我使用dot函数和https://en.wikipedia.org/wiki/DOT_(graph_description_language)生成了这些图形。 - jsguy-O3选项会激活-finline-functions选项,使得gcc将testCache内联到自身几次。函数的大小增加了几倍,但最大堆栈深度减少了一个因子。因此,只有更大的n才会达到堆栈限制。 - user4407569