在SQL Server中,有两种元数据模式:
- INFORMATION_SCHEMA
- SYS
我听说INFORMATION_SCHEMA表是基于ANSI标准的。在开发存储过程等操作时,使用INFORMATION_SCHEMA表会比使用sys表更加明智吗?
在SQL Server中,有两种元数据模式:
我听说INFORMATION_SCHEMA表是基于ANSI标准的。在开发存储过程等操作时,使用INFORMATION_SCHEMA表会比使用sys表更加明智吗?
除非您正在编写一个肯定需要可移植性的应用程序,或者您只需要基本信息,否则我建议您一开始就使用专有的SQL Server系统视图。
Information_Schema 视图仅显示与SQL-92标准兼容的对象。这意味着甚至对于基本构造,例如索引(这些未在标准中定义,并留作实现细节),也没有信息模式视图。更不要说任何SQL Server专有功能了。
此外,它并不是人们可能认为的可移植性万灵药。实现确实会因系统而异。Oracle根本不会“开箱即用”实现它,而MySql文档说:
SQL Server 2000的用户(也遵循标准)可能会注意到相似之处。但是,MySQL省略了许多与我们的实现无关的列,并添加了MySQL特定的列。 INFORMATION_SCHEMA.TABLES表中的ENGINE列就是其中之一。
即使对于烤面包和黄油般的SQL结构,例如外键约束,Information_Schema视图与sys. 视图相比,在处理效率上也可以大大降低,因为它们不会公开允许高效查询的对象ID。
例如,请参见问题SQL query slow-down from 1 second to 11 minutes - why?和执行计划。
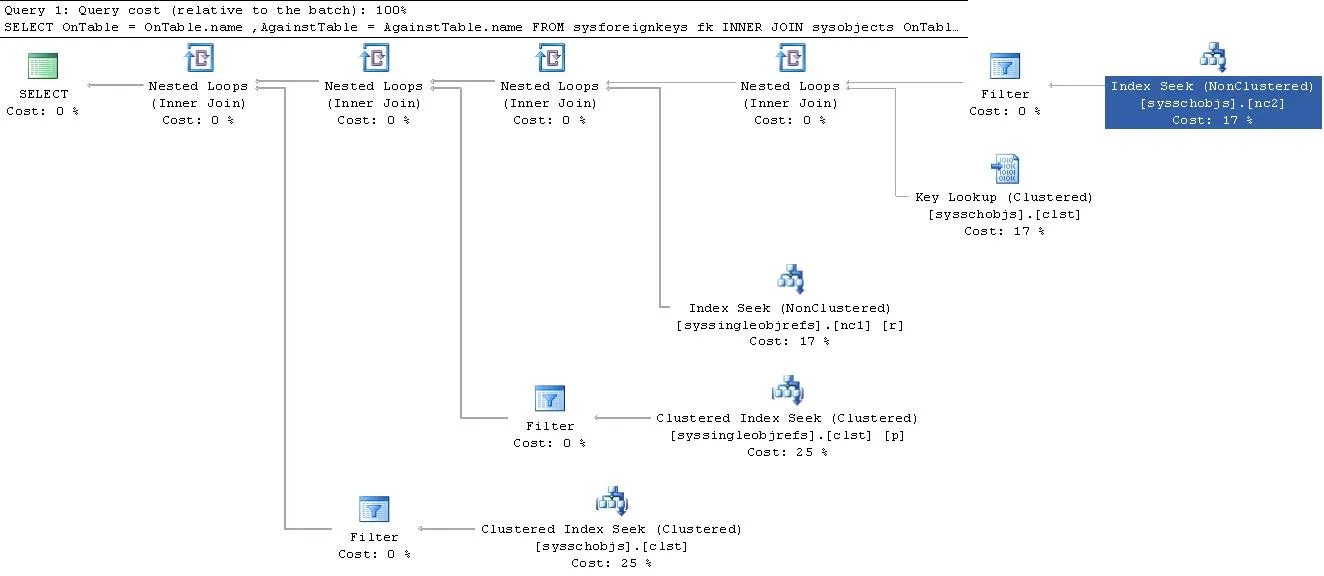
我总是尽量使用Information_schema视图来查询数据库,而不是直接查询sys模式。
这些视图符合ISO标准,因此理论上您应该能够轻松地将任何查询迁移到不同的关系型数据库管理系统(RDBMS)中。
然而,在某些情况下,我需要的信息在视图中并不可用。
我提供了一些链接,其中包含有关视图和查询SQL Server目录的更多信息。
sys模式就可以了。好的评论。 - codingbadgerINFORMATION_SCHEMA 更适合需要与多种数据库进行接口的外部代码。一旦开始在数据库中编程,可移植性就有点无从谈起了。如果你正在编写存储过程,那说明你已经致力于特定的数据库平台(无论是好是坏)。如果你已经致力于 SQL Server,则务必使用 sys 视图。
if exists (select * from information_schema.tables where table_schema = 'dbo' and table_name = 'MyTable')
print '75% cost';
if exists (select * from sys.tables where object_id = object_id('dbo.MyTable'))
print '25% cost';