我不能确定这段代码片段是否被视为池。但是看看这个。
所有的点在gevent中都是异步的。例如,如果您需要请求100个HTML页面(没有gevent),则首先请求第一页,直到响应准备好,您的Python解释器将被冻结。因此,gevent允许冻结这些第一次请求的输出并移动到第二个,这意味着不浪费时间。
因此,我们可以轻松地对所有内容进行猴子补丁。但是,如果您需要将请求结果写入数据库(例如couchdb,couchdb具有修订版本,这意味着必须同步修改文档)。在这里,我们可以使用Semaphore。
让我们编写一些代码(这里是同步示例):
import os
import requests
import time
start = time.time()
path = os.path.dirname(os.path.abspath(__file__))
test_sites = [
'https://vimeo.com/',
'https://dev59.com/an3aa4cB1Zd3GeqPYRdR',
'http://www.gevent.org/gevent.monkey.html#gevent.monkey.patch_all',
'https://www.facebook.com/',
'https://twitter.com/',
'https://www.youtube.com/',
'https://zaxid.net/',
'https://24tv.ua/',
'https://zik.ua/',
'https://github.com/'
]
def process_each_page(html_page):
response = requests.get(html_page)
with open(path + '/results_no_sema.txt', 'a') as results_file:
results_file.write(str(response.status_code) + ' ' +html_page +'\n')
for page in test_sites:
process_each_page(page)
print(time.time() - start)
这是一个涉及到gevent的模拟代码:
from gevent import monkey
monkey.patch_all()
import gevent
import os
import requests
from gevent.lock import Semaphore
import time
start = time.time()
path = os.path.dirname(os.path.abspath(__file__))
gevent_lock = Semaphore()
test_sites = [
'https://vimeo.com/',
'https://dev59.com/an3aa4cB1Zd3GeqPYRdR',
'http://www.gevent.org/gevent.monkey.html#gevent.monkey.patch_all',
'https://www.facebook.com/',
'https://twitter.com/',
'https://www.youtube.com/',
'https://zaxid.net/',
'https://24tv.ua/',
'https://zik.ua/',
'https://github.com/'
]
def process_each_page(html_page):
response = requests.get(html_page)
gevent_lock.acquire()
with open(path + '/results.txt', 'a') as results_file:
results_file.write(str(response.status_code) + ' ' +html_page +'\n')
gevent_lock.release()
gevent_greenlets = [gevent.spawn(process_each_page, page) for page in test_sites]
gevent.joinall(gevent_greenlets)
print(time.time() - start)
现在让我们发现输出文件。这是来自同步结果的。
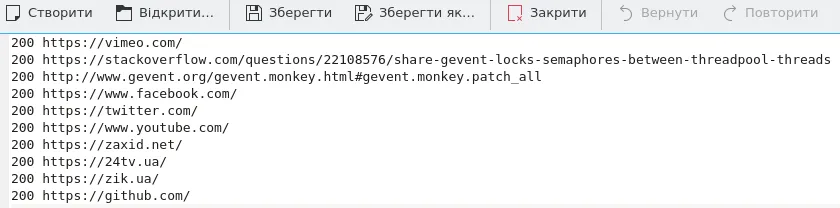
这段文字来自涉及gevent的脚本。
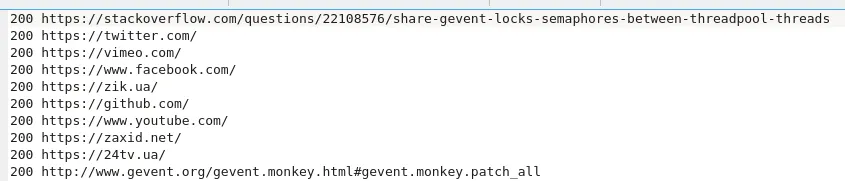
可以看到,当使用gevent时,响应并不按顺序返回。因此,先返回响应的将首先被写入文件。让我们看一下使用gevent时我们节省了多少时间。
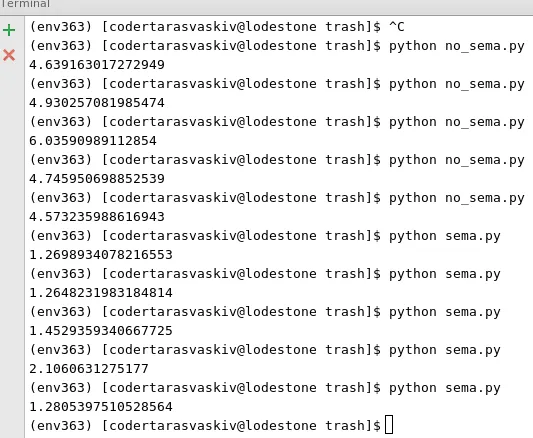
注意:在上面的例子中,我们不需要锁定写入(追加)到文件。但对于couchdb来说,这是必需的。因此,当您在使用Semaphore与couchdb一起获取保存文档时,您将不会遇到文档冲突!